РАЗРАБОТКА ПРИЛОЖЕНИЯ ДЛЯ СТРУКТУРИРОВАНИЯ ДАННЫХ СОЦИАЛЬНЫХ СЕТЕЙ В ФОРМАТЕ FOAF

Вагарина Н.С.1, Мельникова Н.И.2, Маринин Д.С.2
1кандидат физико-математических наук, Саратовский государственный технический университет им. Ю.А. Гагарина, 2доктор социологических наук, Саратовский государственный технический университет им. Ю.А. Гагарина, 3магистрант
РАЗРАБОТКА ПРИЛОЖЕНИЯ ДЛЯ СТРУКТУРИРОВАНИЯ ДАННЫХ СОЦИАЛЬНЫХ СЕТЕЙ В ФОРМАТЕ FOAF
Аннотация
На настоящий момент социальные сети являются «венцом эволюции» современного веба. Поэтому чрезвычайно важно иметь стандартную модель представления данных, позволяющую легко производить процедуры обмена, взаимодействия, преобразования и анализа данных из социальных сетей, а также обработку запросов к данным. Одним из возможных вариантов такой модели на настоящий момент представляется модель описания связанных данных RDF (Resource Description Framework), которая позволяет использовать технологии Семантического веба для интерпретации информации, представленной в вебе. Наиболее серьезным препятствием к развитию идей семантического веба, а также внедрением их в коммерческую область, является сложность создания семантической разметки уже существующей информации. В данной статье предлагается подход к автоматической генерации семантической информации в формате словаря FOAF из социальной сети ВКонтакте для последующего объединения и анализа данных.
Ключевые слова: социальные сети, семантика, RDF, FOAF.Vagarina N.S.1, Melnikova N.I.2, Marinin D.S.3
1PhD in Physics and Mathematics, Yuri Gagarin State Technical University of Saratov, 2PhD in Sociology, Yuri Gagarin State Technical University of Saratov, 3Undergraduate student, Yuri Gagarin State Technical University of Saratov
DEVELOPING APPLICATIONS FOR STRUCTURING DATA OF SOCIAL NETWORKS INTO A FOAF FORMAT
Abstract
Nowadays, social networks are "the crown of evolution" of the modern web. It is therefore extremely important to have a standard model of reporting, which would enable easy exchange procedures, interaction, transformation and analysis of data from social networks, as well as the processing of requests for data. One of the possible options of this model at the moment seems to be the model associated RDF data (Resource Description Framework), which allows the Semantic Web technology to interpret the information provided on the web. The most serious obstacle to the development of the ideas of the Semantic Web, as well as the introduction of the commercial area, is the difficulty of creating a semantic markup of existing information. This article proposes an approach of automatic generation of semantic information in the FOAF vocabulary format from the social network VKontakte to merge and analyze data in future.
Keywords: social network, semantics, RDF, FOAF.В настоящее время объем информации в вебе таков, что эффективный поиск и обработка ее становятся все более затруднительными. В связи с этим делаются попытки поиска новых методов и подходов к созданию, предоставлению и обработке информации. Один из основных подходов на настоящий момент для решения этой задачи является применение технологий семантического веба (semantic web). Концепция cемантического веба была принята и продвигается Консорциумом W3C, разрабатывающим и внедряющим технологические стандарты для сети Интернет. Основным результатом по продвижению идеи семантического веба является стандартизация ключевой технологии семантического описания ресурсов RDF (Resource Description Framework). Абстрактно, RDF представляет собой неотсортированную коллекцию утверждений, которые называются триплеты. Триплет, в свою очередь, представляет собой модель «субъект – предикат – объект». Субъект представляет собой сущность, которую необходимо описать, предикат является свойством субъекта, а объект определяет значение этого свойства. В качестве примера можно привести кодировку утверждения «Металлическая кружка». Здесь объект – кружка, предикат – материал, объект – металл. Триплеты могут быть сериализованы по-разному. Способ их сериализации называется диалектом (или нотацией). Самыми распространенными диалектами являются RDF/XML, Turtle, Notation3 и N-Triples, причем только RDF/XML является стандартом, официально поддерживаемым консорциумом W3C.
Наиболее серьезным препятствием к развитию идей семантического веба, а также внедрению их в коммерческую область, является сложность создания семантической разметки уже существующей информации. Поэтому, в настоящее время одним из перспективных направлений исследований в этой области является создание программных продуктов, генерирующих семантические форматы данных из уже существующих [1], автоматическое создание онтологий [2,3] и др.
Поскольку семантическая модель RDF[4] описывает данные в виде графа, представляется актуальным создание инструмента визуализации графов для последующего экспорта данных в формат RDF, позволяющего в простой и наглядной форме создавать визуальную информацию о взаимосвязях в виде графа, а также переводить эту информацию в формат RDF, изучать и сравнивать различные связи в графах, строить соответствующие RDF-нотации в формате FOAF. FOAF (Friend of a Friend) является проектом семантического веба по созданию модели машинно-читаемых домашних страниц и социальных сетей [5]. Семантический анализ социальных сервисов имеет большое значение для научного сообщества. Учёные используют социальные сервисы в целях так называемой открытой науки для обращения к широкой аудитории и для профессионального взаимодействия. Научные социальные сетевые сервисы обнажили глобальные процессы социальной дифференциации и интеграции научного сообщества. Они автономный от авторов механизм накопления и публикации их научного социального капитала, показали дифференциацию учёных и циркулирующих информационных потоков в научном мире, а также предложили новые возможности интеграции учёных для совместной творческой деятельности [6]. Проект основан на использовании словаря FOAF, определяющего некоторые выражения, используемые в высказываниях о людях.
С целью эффективности разработки приложения визуализации данных были рассмотрены и проанализированы уже существующие аналогичные программные продукты для социальных сетей и результаты анализа представлены в таблице 1, в которой отображены все плюсы и минусы по представленным характеристикам:
Таблица 1 – Сравнительный анализ приложений визуализации графов
| Интуитивный интерфейс | Простота в работе | Просмотр друзей своего круга друзей и следующие уровни | Экспорт в RDF – формат | |
| Gephi | - | - | - | - |
| Friend Wheel | + | + | - | - |
| YASIV VK | + | + | - | - |
| YASIV FACEBOOK | + | + | - | - |
| Интерактивный граф друзей | + | + | - | - |
| VK FRIENDS | + | + | + | + |
Рассмотрев самые популярные сервисы для обработки и визуализации социального графа, можно сделать следующие выводы. Сервисов для визуализации и обработки данных графов социальных сетей мало, так как данная сфера имеет узкую направленность. Существующие сервисы имеют достаточно хороший функционал и оптимизированы для работы с большими данными. Но у каждого сервиса есть и отрицательные стороны. На сегодняшний день не существует стандарта, по которому строилась бы иерархия сервиса и имелась возможность его использования в новых проектах. Все рассмотренные сервисы либо имеют документацию на английском языке, либо не имеют её вовсе. Все рассмотренные сервисы направлены на визуализацию данных и построение графа друзей, но нет возможности экспорта данных в форматы семантического веба. Исходя из вышеперечисленного, представляется целесообразным создание нового приложения “VK Friends” для более глубокого анализа взаимосвязей профиля в социальной сети. Основной функционал приложения состоит из двух частей. Первая часть заключается в построении графа связей, вторая – в экспорте полученных данных в RDF-формат (нотация RDF/XML).
Для разработки приложения визуализации социального графа и экспорта дружеских связей в RDF-формат необходимо было принять решение о выборе языка программирования, IDE, необходимых библиотек и др. В качестве языка разработки был выбран Python в силу таких преимуществ, как лаконичность синтаксиса, кроссплатформенность кода, большое количество библиотек, в том числе для визуализации любого вида данных, автоматическая сборка мусора и отсутствие утечки памяти, динамическая типизация данных и др. В качестве IDE была выбрана среда Geany по таким причинам, как стабильная работа IDE на любой системе, понятный интерфейс и возможность вывода вспомогательных модулей, быстрая настройка компиляции, отладчика, удобная навигация по файлам и классам и др. Для реализации приложения были выбраны библиотеки: Tkinter – кроссплатформенная библиотека визуализации пользовательского интерфейса; PIL – библиотека для обработки изображений; Urllib – стандартная библиотека, позволяющая исполняемой программе получать доступ к объектам WWW; NetworkX – библиотека, позволяющая вести обработку графов; Matplotlib - библиотека с дополнительным набором инструментов для построения графиков, диаграмм данных; Vk – библиотека, ориентированная на генерацию запросов и обработку ответов сервиса api.vk.com.
При тестировании созданного приложения было выявлено следующее. Программа оптимизирована на визуализацию крупных графов. При работе с 25 000 вершинами потребление памяти не превышало 150 – 180 Мегабайт. Пиковая нагрузка на оперативную память возникала при визуализации графа. Потребление оперативной памяти доходило до 1,1 Гигабайта оперативной памяти. После чего шла очистка от лишних данных, что давало существенную очистку памяти. При построении графа загрузка процессора не выходила за пределы 25%. Время визуализации графа и экспорта данных в формат RDF с количеством в 150 вершин занимает 45 секунд.
На рисунках 1 и 2 представлены результаты работы программы:
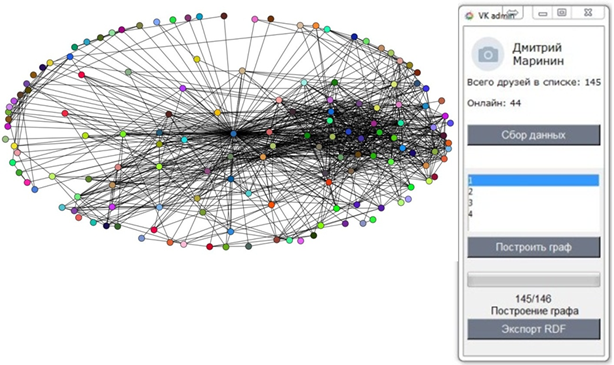
Рис.1 – Построенный граф дружеских связей аккаунта
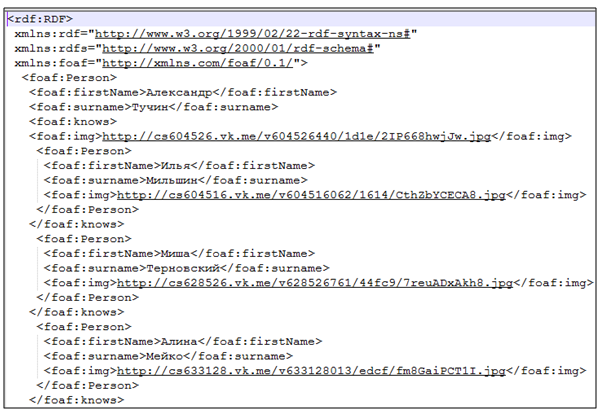
Рис.2 – Фрагмент данных, экспортированных в формат RDF/XML
Таким образом, созданное приложение является одним из шагов на пути решения задачи автоматизации создания данных в формате RDF/XML. К полученным данным, после размещения их, например, в репозитории, можно подавать запросы на языке запросов SPARQL, а также размещать их как связанные открытые данные в облаке открытых данных, тем самым обеспечивая возможность расширения сети FOAF за счет автоматического установления связей через семантические словари. Дальнейшие развитие проекта предполагает выявление перескающихся сообществ, в том числе научных, в различных социальных сетях, с учетом особенностей стратификации общества.
Список литературы / References
- Вагарина Н.С., Апсаликов М.Ю. Разработка библиотеки для генерации семантических данных//Наука, техника и образование. – Москва, - № 10 (16). - стр. 31-35.
- Романов С.В., Сытник А.А., Шульга Т.Э. О возможностях использования коммуникативных грамматик и LSPL-шаблонов для автоматического построения онтологий//Известия Самарского научного центра Российской академии наук, т. 17, №2(5), 2015. - C. 1104-1108.
- Данилов Н.А. Шульга Т.Э. О разработке онтологии предметной области «Юзабилити»// Инжиниринг предприятий и управление знаниями: сборник научных трудов XIX научно-практической конференции. - Москва : ФГБОУ ВО "РЭУ им. Г. В. Плеханова", 2016. - С.245-249.
- RDF 1.1 XML Syntax [Электронный ресурс]/W3C Recommendation. – Режим доступа: http://www.w3.org/TR/rdf-syntax-grammar/ (дата обращения 25.09.2016)
- FOAF Vocabulary Specification 0.99: http://xmlns.com/foaf/spec/[Электронный ресурс]. Режим доступа: http://xmlns.com/foaf/spec/ (дата обращения 21.09.2016).
- Мельникова Н.И. Научные социальные сетевые сервисы как средство дифференциации и интеграции научного сообщества, -Вестник Саратовского государственного технического университета, Т.1., № 1, - 2013. С. 255-260.
Список литературы на английском языке / References in English
- Vagarina N. S. Razrabotka biblioteki dlja generacii semanticheskih dannyh [Development library to generate semantic data] // Nauka, tehnika i obrazovanie [Science, technology and education] / N. S. Vagarina, M. Ju. Apsalikov. – M., 2015. – № 10 (16). – P. 31–35. [in Russian]
- Romanov S. V. O vozmozhnostjah ispol'zovanija kommunikativnyh grammatik i LSPL-shablonov dlja avtomaticheskogo postroenija ontologij [On the possibilities of the use of communicative grammar and LSPL-templates for automatic construction of ontologies] / S. V. Romanov, A. A. Sytnik, T.Je. Shul'ga // Izvestija Samarskogo nauchnogo centra Rossijskoj akademii nauk [Bulletin of Samara Scientific Center of the Russian Academy of Sciences]. – V. 17. – №2(5). – 2015. – P. 1104-1108. [in Russian]
- Danilov N. A. O razrabotke ontologii predmetnoj oblasti «Juzabiliti» [On the development of the subject area "Usability" ontology] / N. A. Danilov, T. Je. Shul'ga // Inzhiniring predprijatij i upravlenie znanijami: sbornik nauchnyh trudov XIX nauchno-prakticheskoj konferencii [Engineering enterprises and knowledge management: Proceedings XIX scientificpractical conference]. – M. : FGBOU VO "RJeU im. G. V. Plehanova", 2016. – P. 245–249. [in Russian]
- RDF 1.1 XML Syntax [Electronic resource]/W3C Recommendation. – URL: http://www.w3.org/TR/rdf-syntaxgrammar/ (accessed 25.09.2016)
- FOAF Vocabulary Specification 0.99: http://xmlns.com/foaf/spec/ [Electronic resource]. – URL: http://xmlns.com/foaf/spec/ (accessed 21.09.2016).
- Mel'nikova N. I. Nauchnye social'nye setevye servisy kak sredstvo differenciacii i integracii nauchnogo soobshhestva [Scientific social media as a means of differentiation and integration of the scientific community] / N. I. Mel'nikova // Vestnik Saratovskogo gosudarstvennogo tehnicheskogo universiteta [Bulletin of Saratov State Technical University]. – V. 1. – № 1. – 2013. – P. 255-260. [in Russian]