ИСПОЛЬЗОВАНИЕ ВЕСОВЫХ МЕТРИК В ПОИСКЕ СХОЖЕСТИ ДЛЯ ИДЕНТИФИКАЦИИ СТАТИЧЕСКИ КОМПОНУЕМЫХ БИБЛИОТЕЧНЫХ ФУНКЦИЙ

Гедич А.А.
Аспирант, Санкт – Петербургский Национальный Исследовательский Университет Информационных Технологий, Механики и Оптики
ИСПОЛЬЗОВАНИЕ ВЕСОВЫХ МЕТРИК В ПОИСКЕ СХОЖЕСТИ ДЛЯ ИДЕНТИФИКАЦИИ СТАТИЧЕСКИ КОМПОНУЕМЫХ БИБЛИОТЕЧНЫХ ФУНКЦИЙ
Аннотация
В статье рассмотрены существующие решения, используемые при идентификации статически компонуемых библиотечных функций. Описаны их основные достоинства и недостатки. Представлено новое для данной области решение, сочетающее гибкость поиска и открытость системы. Проведён ряд экспериментов, доказывающих применимость разработанного решения.
Ключевые слова: дизассемблер, метрика, сигнатура, исполнимый код, статическая библиотека.
Gedich A.A.
Postgraduate student, Saint Petersburg National Research University of Information Technologies, Mechanics and Optics
USAGE OF WEIGHTED SIMILARITY METRICS FOR IDENTIFICATION OF STATICALLY LINKED LIBRARY FUNCTIONS
Abstract
The article considers existing solutions that are used for identification of statically linked library functions. Their main advantages and disadvantages are described. Novel approach that combines flexibility and easy integration is introduced. Set of experiments was conducted to prove usability of developed solution.
Keywords: disassembler, metric, signature, executable code, static library.
Introduction
One of important steps during analysis of executable code is identification of statically linked library functions (SLLF). Ability to solve this complex task provides additional information that can be used to facilitate executable code analysis. Identification of library functions allows to separate user code from large amount of runtime auxiliary code that is integrated into executable by compiler. Runtime functions often pose a problem during executable code analysis [1] because they can be highly optimized or even contain parts written in assembly language. Such code brings additional complexity to disassembling process and generation of high level language program. Extensive analysis of executable should be done only after user code is separated from runtime code.
SLLF identification can also provide rich amount of information about function arguments. Argument names and types can be used during data flow analysis by propagating them through control flow graph. For example such feature is implemented by popular IDA disassembler. Analyzer developed in this research retrieves information about arguments by function name through meta-information provider that utilizes database generated by GCCXML tool [2].
Finally SLLF identification introduces ability to map library symbols on identified code fragments. This gives information about function variables and global labels in particular which pose serious problem to executable code analysis.
Research motivation
This research was motivated by lack of flexible algorithms for SLLF search that are able to identify partially similar executable code fragments. Many of existing solutions are based on signature search. Such type of search was actively developed in Fast Library Identification and Recognition Technology (FLIRT) that is used by IDA disassembler [3]. Same approach was used in [4] later in [1] and [5, 6].
Signature is a byte sequence that represents machine code. Some bytes can be masked to facilitate the search. Binary tree composed from such signatures is stored in database. Signature search that requires quite exact matching can be performed on this database taking masked bytes into account. Such approach has difficulties and drawbacks in implementation that will be discussed later.
Alternative approach is introduced in [7] where usage of machine learning algorithms is proposed. However authors concentrate on identification of procedure borders and differentiating executable code from data. Thus it motivated investigation of possibility to use such techniques for identification of SLLF in this research.
Purpose of this research
Main task is development of very flexible algorithm for SLLF search that allows identification of partially similar executable code fragments. Preliminary search step should allow fast and obvious encoding of instructions with saving them into reusable signature file. Encoding process should not depend on required search flexibility that should be controlled by input threshold parameters.
Vector approach should be used for implementation of SLLF search. It should be proved that such method can be used for stated task. This paper should also introduce alternative solution for eliminating main drawback of vector approach expressed by inability to keep information about topology of compared objects.
Further research
Problem of keeping topology of compared objects will be solved in further research by using graph approach and kernel functions in particular. Such solution will be integrated as second step of the search. Also additional algorithms for filtering noise in results will be introduced. Variety of metrics and kernel functions will be added giving ability to select corresponding comparison function during SLLF search. Finally more experiments will be performed on real applications.
Research domain
This paper concentrates on research of msvc compiler and corresponding runtime functions that are statically linked into compiled executable. Linker used by msvc has different versions depending on IDE. Versions considered in this paper are 7.0, 7.1, 8.0, 9.0, 10.0. It is important that runtime library version depends on version of linker. Each runtime library is deployed in two variations – as static library (lib) or as dynamic library (dll). Each library has also two types – singlethreaded or multithreaded. In later versions only multithreaded libraries exist. Finally each library can be assembled either in debug or in release mode. All these details should be taken into account while performing generation of unique signature files corresponding to each combination of library types. This research concentrates on multithreaded static release runtime library libcmt.lib. Dynamic equivalent is msvcrt.dll.
Next step done before search is version identification of linker that was used during compilation of analyzed executable. PEiD [8] tool is used for that purpose. This tool is based on signature search of compiler through compiler database. During research it was able to exactly identify compiler name and linker version used for compilation of executable.
Structure of lib files
Lib file is an archive composed from object (obj) files. Each object file consists from multiple sections that contain code of runtime functions with their names known beforehand. Contents of section can be disassembled same way as executable file. Generic disassembler in this research utilizes different address space providers for object and executable files to perform this task. Disassembler uses recursive traversal approach along with procedure border identification, code and data separation and other techniques that facilitate analysis process. This solution avoids many common problems of naive linear sweep approach described in [4].
Typically lib files contain different types of symbols. Additional filtering is performed before encoding signature file of runtime library. Functions that contain public, private and protected attributes in name are filtered out because they are class methods. External symbols and symbols that are not functions are also filtered. Some amount of functions is not encoded due to disassembling errors which is about 4.5% of all functions that can be statically linked into executable.
Standard way of signature encoding
It is a well known fact that decoding of Intel x86 architecture instructions poses a very complex problem. For example semantically equal instructions can be encoded in multiple ways. Immediate or displacement operands in instruction both can represent address or constant. Addresses can differ from one executable to another and moreover lib and executable files utilize different address spaces. More exactly lib files use RVA (relative virtual address) space where typically one or few functions belong to same section. On the other hand executable files use VA (virtual address) space where all functions belong to one section which is typically code section. In other words immediate or displacement can’t be easily compared in terms of classical signature search. Search on machine code level in general is hard to implement and encoding process is complex and not obvious.
To solve this problems instruction parts are often masked by null byte and ignored during signature search. Sometimes rarely used opcode like HALT is chosen as null byte for masking purpose [4]. Such solution is unacceptable as it always leaves probability of not being able to distinguish real opcode from null byte.
This drawback can be eliminated by introducing mechanism that can distinguish immediate or displacement from address that belongs to specified address space. Though such solution is harder to implement it brings many advantages not only to SLLF search. Such approach is implemented in this research.
Generic background of developed instruction encoding system
Research presented in this paper is based on different approaches from bioinformatics area such as QSAR (Quantitative Structure-Activity Relationship) search. This search utilizes machine learning algorithms and mathematical statistics methods and is targeted on prediction of different properties of chemical compounds from structure description.
Typically two methods are used in this area which are vector and graph approach. In vector approach given object is encoded into vector of descriptors called fingerprint. Vector components are called features. Main drawback of this approach is inability to keep topology of given object while doing comparison. Graph approach eliminates this issue. Such method models molecule properties by means of neural network or kernel functions that utilize special graph kernels.
In vector approach comparison function defined between objects is called metric. Typically such function has four input parameters a, b, c, d that are computed from pair of compared vectors. Then similarity coefficient is calculated according to given metric. Sometimes input parameters have weights corresponding to them.
This paper introduces alternative approach with usage of weight map where each feature from defined alphabet can have corresponding standalone weight. Such map gives ability to effectively manipulate similarity coefficient and gives control over each part of fingerprint. It is obvious that such approach is much flexible than usage of naive binary search with masking bytes which requires quite exact matching.
Advantages of developed fingerprint encoding system
Disassembler that was implemented in this research gives ability to work with instruction on semantics level. Such abstraction avoids machine code level while bringing simplicity to encoding process and making it more obvious in general.
Fingerprint encoder utilizes maximum amount of information from each instruction. Nothing is ignored or discarded compared to solutions described earlier. Moreover in some cases additional meta-information is integrated into fingerprint allowing further enhancement of fingerprint comparison.
For example when function import from dynamic library is detected absolute address is not encoded into fingerprint. Instead special import function feature is generated. Such feature contains hash code of import function name. FNV1 (Fowler-Noll-Vo version 1) non cryptographic 32bit hash function is used for that purpose.
When immediate or displacement is detected analyzer does possible address check by using PE (Portable Executable) parser implemented in this research. If immediate or displacement can be represented as address it is encoded by special feature without exact immediate value. In case when immediate or displacement can’t be address they are encoded by another feature with exact value integrated.
General architecture of search system is based on factory pattern. Usage of encoder and fingerprint factory allows fast integration of new components as soon as new feature alphabet and weight map is defined. Fingerprint comparator is also generic and allows fast integration of new metrics if needed.
Instruction encoding process
During disassembling and analysis of lib files list of library functions is retrieved. Each list entry contains function name and instructions that belong to this function. When executable code analyzer is not used problems described in [4] can arise. Reading of instruction stream in linear sweep can cause capturing of code fragment that belongs to different function which in turn will lead to generation of wrong fingerprint list.
Each instruction set has corresponding encoder. Currently GP (general purpose), FPU, SSE, SSE2 and P6F instruction sets are encoded. On the other hand developed disassembler can decode all instructions up to SSE4.2. It is important that each instruction set forms a class that has corresponding feature alphabet and weight map. For different instruction sets different feature alphabets should be used because such alphabet should include only features that can be used by compared objects. For example SSE instructions use xmm registers that are not present in GP instructions. Usage of common alphabet can have negative impact on similarity coefficient.
After list of instructions is obtained each instruction is passed to generic encoder. According to instruction type corresponding encoder is created through factory. Encoder then translates instruction into feature vector using given alphabet and returns fingerprint that is created through factory accordingly. This process is repeated for each instruction list corresponding to library function. Encoded fingerprints are then stored in signature file that can be further archived to save disk space if needed.
Feature alphabet example
Each feature has 64bit size and is combined from feature code and optional meta-information part. One of the most complex alphabets is indeed GP instruction set alphabet. Following features are encoded with GP encoder.
Prefixes: Segment overload prefixes are semantically part of memory operand and belong to another feature group.
LOCK, BHT, BHNT, REP, REPE, REPNE.
Mnemonic: 172 GP mnemonics are encoded.
Operand number: Operand number is encoded with special feature that has big weight which improves similarity coefficient.
OPNUM(num)
Operand order: Currently operand order is not encoded which can lead to presence of false positive results.
Main registers: General purpose registers used as operands are encoded.
AL, CL, DL, BL, AH, CH, DH, BH.
AX, CX, DX, BX, SP, BP, SI, DI.
EAX, ECX, EDX, EBX, ESP, EBP, ESI, EDI.
Memory operand registers: This registers are encoded with features that are different from main registers group.
AX, CX, DX, BX, SP, BP, SI, DI.
EAX, ECX, EDX, EBX, ESP, EBP, ESI, EDI.
AL – encoded for XLAT instruction.
Memory segment: Segment registers are encoded.
ES, CS, SS, DS, FS, GS.
Scale index: Scale index used in SIB (scale-base-index) operand is encoded.
Indexes 2, 4, 8. Index 1 has no semantic sense an can be ignored.
INDEX(ind)
Pointer type: Type of pointer used when accessing memory is encoded.
BYTE, WORD, DWORD, QWORD, DQWORD – standard instructions.
VARIABLE, ADDRESS, EXPRESSION – non standard instructions like LEA.
Relative address: Relative address can be encoded with or without information about specific value. Direction of control flow is also encoded or discarded.
REL8, REL16, REL32 – for CALL instructions.
REL8LESS, REL8GRTR, REL16LESS, REL16GRTR, REL32LESS, REL32GRTR – for JMP and Jcc instructions.
Immediate: Immediate is encoded with exact value or as address. Low level information about immediate size (8, 16 or 32 bits) is discarded.
IMM, LBLIMM
Displacement: Displacement is encoded same way as immediate.
DISP, LBLDISP
Import: Import address is a special case of displacement or immediate in rare cases. Import function name is extracted from PE header or symbol table of lib file. Then 32bit non cryptographic FNV1 hash is calculated and integrated into feature.
IMP(hash)
Segment registers: Segment registers that are used as operands are encoded.
ES, CS, SS, DS, FS, GS.
Calculating fingerprint similarity coefficient
Given two fingerprints of same class, where each consists from set of features defined in alphabet next parameters can be calculated.
a – number of features unique to first fingerprint.
b – number of features unique to second fingerprint.
c – number of features common to both fingerprints.
d – number of features that are not present in both fingerprints.
When described parameters are calculated similarity coefficient can be obtained through given metric. This paper uses Ochiai (cosine similarity) metric that calculates angle between two vectors and can be written as:
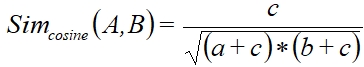
As it was indicated earlier a, b, c, d parameters represent number of features from each kind. Developed algorithm on the other hand utilizes weighted parameters aw, bw, cw, dw. Weighted parameter can be calculated by using next formula, where |Fi| is number of ith feature and Wi is weight that corresponds to ith feature.
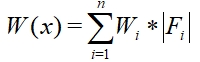
Usage of LCS algorithm
After mechanism of instruction comparison is defined next step is to identify similar instruction sequences. Assumption can be made that same vector approach with similarity metric can be used to identify code fragments. Unfortunately this is incorrect as order of instructions will not be considered because vector approach does not keep object topology during comparison.
This paper introduces alternative approach to solve such problem. Code fragment comparison is based on LCS (longest common sequence) algorithm that is usually used to find difference between two texts. This algorithm was generalized allowing comparison of two abstract objects from same class with comparison function defined between them. Here compared object is instruction and comparison function is weighted similarity metric that was described earlier. Because comparison function returns coefficient user threshold Ilim is defined. If coefficient value is greater than threshold comparison function returns true otherwise false.
Matrix of matches that shows similarity between compared lists of fingerprints is computed according to LCS algorithm. The longest substring that contains sequence of matching fingerprints is then constructed by backtracing through this matrix. Substring is then mapped back on fingerprint lists that belong to compared functions. Because each fingerprint has instruction address as identifier it becomes possible to obtain lists of common code ranges that belong to compared functions. Intersection of full fingerprint lists with lists of common code ranges gives list of non matching code ranges that belong to compared functions.
When three types of lists are obtained weighted similarity metric can be applied to them to calculate similarity coefficient of compared functions. In this case code range means feature and number of instructions in this range serves as feature weight. User threshold Plim is defined for function similarity coefficient. If coefficient value is greater than threshold functions are considered matching.
It is important that similarity coefficient is computed based on weighted metric. Usage of such approach allows non matching range with more fingerprints to have greater influence on result than matching range with less fingerprints and vice versa.
Usage of heuristics to improve search performance
Obvious drawback of described approach is low performance. To be more exact LCS algorithm is very time and resource consuming. In general when doing SLLF search every function from executable should be compared to every function in fingerprint database. Search result is then represented by list with one-to-many relationship where user can choose most relevant match.
To improve performance two heuristics are used. First one is size ratio of compared functions. It is obvious that when difference in number of fingerprints is great there is no point in doing comparison between such functions. User threshold Slim is defined for this ratio. When doing comparison between two functions zero result is returned immediately if functions size ratio is greater than threshold.
Another heuristic assumes that only first N fingerprints of compared functions can be fetched for comparison. Although that N value should be great enough to still allow unique function identification. To perform such fetch user threshold Nlim is defined. Main drawback of this approach is existing probability of false positive results presence in search results. This heuristic is used in [3], [4]. In [4] it causes problems during search because sometimes instructions that do not belong to compared function are fetched. Such drawback is eliminated in this research by usage of analyzer with recursive traversal.
Further speed up can be achieved with sorting lists of compared functions by number of fingerprints that they contain. This allows minimization of distance between possibly same objects in compared lists. Unfortunately such approach is inapplicable to one-to-many relationship search.
False positive results
False positive results can not be avoided while performing SLLF search. Their presence is described in [3], [4] and they also appear in this research. Typically such problem arises from small Nlim value or in functions that have small size. They should be identified as different functions but are actually same on machine code level. This problem can be partially solved by using one-to-many relationship list as result storage where user can choose most relevant match. However if this task should be automated then additional noise filters should be used. They can be based on call context analysis or search through possible call tree etc. Such approaches are not described in this paper.
Main advantages and drawbacks of introduced algorithm
Advantages of developed algorithm include obvious implementation of fingerprint encoding, generic encoding mechanism, easy integration of new encoders and high encoding performance. Algorithm has enough flexibility controlled by usage of weighted similarity metric along with user thresholds Ilim, Plim, Slim, Nlim. It allows searching not only exactly but also partially matching code sequences.
Main drawback is definitely low performance of fingerprint comparison operation that is caused by slow LCS algorithm. This problem can be eliminated in future research by using kernel functions with high performance.
Research results
Series of experiments were performed during research on typical hello world application that was specially compiled for that purpose. Source code of this application is listed below. This program uses some standard library functions such as strlen, printf, sin, cos. Compilation was done using msvc linker of versions 7.0, 7.1, 8.0, 9.0, 10.0. Most important parameter that had influence on search is optimization level which can take values O1, O2, O3.
#include "stdio.h"
#include "math.h"
#include "string.h"
int main(int argc, wchar_t* argv[]) {
double s = sin(1.0);
double c = cos(1.0);
const char* hello = "Hello world VC 8.0";
size_t len = strlen(hello);
printf("len:%d %s\n", len, hello);
printf("sin:%f cos:%f\n", s, c);
return 0;
}
Experiments had shown that when optimization level is O1 (minimize size) library function code is simply integrated into executable. When optimization level is O2 (maximize speed) assembly code can be significantly changed which in turn makes SLLF search harder. For example some library functions are inlined into body of another function. That happens with strlen function. In other cases usage of library function is replaced by call to auxiliary runtime procedure. Detection of inlined functions is not discussed in this paper however it can be done by using algorithms that are applied in molecule substructure search for example.
Testing of search results was done by comparing them with original symbol (pdb) files that are generated during compilation of test executable. For that task additional symbol file parser was developed in this research. It was built over dialib library which in turn is a wrapper for COM library msdia that is deployed by vendor along with other msvc tools. Possible test results are given in table 1. Tests were performed two times with different values of Plim threshold.
Table 1
| test name | symbol in exe | symbol in lib | match | Description |
| Р1 | yes | yes | yes | Match with approval possibility |
| Р2 | yes | yes | yes | Match with wrong function |
| Р3 | no | yes | yes | Match without approval possibility |
| Р4 | yes | yes | no | Match with approval possibility |
| Р5 | no | yes | no | Match without approval possibility |
Approval possibility is defined by presence of symbol in executable file. Symbols are always present in lib file. P1 defines true match while P2 defines false positive result. P3 defines match that can’t be approved. Experiments have shown that typically this is auxiliary function or false positive result. P4 defines non match. Typically this is user function (main), search error or function that is missing in fingerprint database due to disassembling error. P5 defines non match. Experiments showed that typically this is auxiliary function or user function.
Tables 2 and 3 show how results can vary by changing Plim threshold. Increase of threshold allows filtering large amount of noise that appears during search. It can be seen that main results from P1 group have quite low percentage.
Table 2 - (Ilim= 0.95 Plim= 0.75 Slim = 1.8 Nlim = 10)
| Р1 | Р2 | Р3 | Р4 | Р5 | |
| msvc7 | 74.790 | 0.840 | 10.924 | 4.202 | 9.244 |
| msvc71 | 72.000 | 0.800 | 12.000 | 4.000 | 11.200 |
| msvc8 | 74.877 | 0.985 | 9.360 | 3.941 | 10.837 |
| msvc9 | 74.874 | 2.513 | 12.060 | 2.513 | 8.040 |
| msvc10 | 79.191 | 2.312 | 10.405 | 1.734 | 6.358 |
Table 3 - (Ilim= 0.95 Plim= 0.90 Slim = 1.8 Nlim = 10)
| Р1 | Р2 | Р3 | Р4 | Р5 | |
| msvc7 | 74.790 | 0.840 | 3.361 | 4.202 | 16.807 |
| msvc71 | 71.200 | 0.800 | 3.200 | 4.800 | 20.000 |
| msvc8 | 74.877 | 0.985 | 5.419 | 3.941 | 14.778 |
| msvc9 | 74.874 | 2.010 | 0.503 | 3.015 | 19.598 |
| msvc10 | 79.191 | 1.156 | 1.156 | 2.890 | 15.607 |
Low results of P1 group don’t mean that introduced SLLF search is ineffective. Actually P5 column should be excluded from tables because it contains results for non library functions that can’t be mapped a priori. True results are shown in table 4. They also appear on graph 1. As can be seen from table 4 average match percentage is 90.744, average noise percentage is 4.686 and average non match percentage is 4.570. Experiments showed that most non matches are caused by missing fingerprints in signature database which is caused by errors during disassembling.
Sequentially P1 group results should be analyzed because groups P2, P3, P4 represent noise. Table 5 shows percentage ratio of results with one and multiple matches. Average percentage of exact matches is 79,665 and average percentage of matches with noise is 20.335. Results are also presented on graph 2
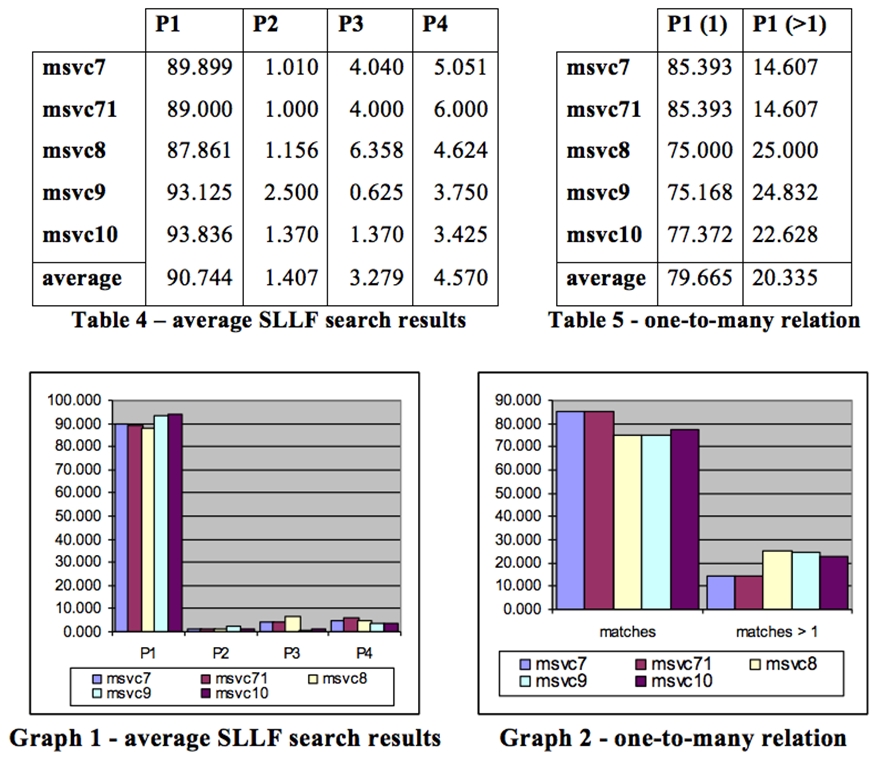
Fig. 1
Conclusion
In presented research standard approaches for SLLF search were analyzed. Their main drawbacks and advantages were described. Novel approach in research area was introduced. Main advantage of introduced algorithm is search flexibility and easy integration of new components into system. It was experimentally proved that developed algorithm is effective and can be used for SLLF search. Future research will allow further improvement of results. Described system will be expanded and adjusted to allow search of inlined functions and partially similar code fragments.
Список литературы
Cifuentes C. Reverse Compilation Techniques // PhD Dissertation, Queensland University of Technology, Department of Computing Science. – 1994. – P.1–342.
GCCXML compiler extension. URL: http://gccxml.github.io/HTML/Index.html (access date 27.10.2013).
Guilfanof I. FLIRT Technology 1997. URL: http://www.idapro.ru/description/flirt/ (access date 27.10.2013).
Fuan C., Zongtian L. C Function recognition technique and its implementation in 8086 C decompiling system // Mini-Micro Systems. – 1991. – V. 12, № 11. – P.33–40.
Emmeric M. Signatures for Library Functions in Executable Files // Technical Report. – 1994. – P.1-8.
Emmeric M. Identifying Library Functions in Executable Files Using Patterns // In Proceedings of the Australian Software Engineering Conference. – 1998. – P.90-97.
Wartell R., Zhou Y., W. Hamlen K., Kantarcioglu M., Thuraisingham B. Differeating code from Data in x86 Binaries // Proceedings of the 2011 European conference on Machine learning and knowledge discovery in – 2011. - V.3. – P.522-536.
URL: http://www.aldeid.com/wiki/PEiD (access date 27.10.2013).
Список литературы
Cifuentes C. Reverse Compilation Techniques // PhD Dissertation, Queensland University of Technology, Department of Computing Science. – 1994. – P.1–342.
GCCXML compiler extension. URL: http://gccxml.github.io/HTML/Index.html (access date 27.10.2013).
Guilfanof I. FLIRT Technology 1997. URL: http://www.idapro.ru/description/flirt/ (access date 27.10.2013).
Fuan C., Zongtian L. C Function recognition technique and its implementation in 8086 C decompiling system // Mini-Micro Systems. – 1991. – V. 12, № 11. – P.33–40.
Emmeric M. Signatures for Library Functions in Executable Files // Technical Report. – 1994. – P.1-8.
Emmeric M. Identifying Library Functions in Executable Files Using Patterns // In Proceedings of the Australian Software Engineering Conference. – 1998. – P.90-97.
Wartell R., Zhou Y., W. Hamlen K., Kantarcioglu M., Thuraisingham B. Differeating code from Data in x86 Binaries // Proceedings of the 2011 European conference on Machine learning and knowledge discovery in – 2011. - V.3. – P.522-536.
URL: http://www.aldeid.com/wiki/PEiD (access date 27.10.2013).