АВТОМАТИЗИРОВАННАЯ ГЕНЕРАЦИЯ ТРЁХМЕРНОЙ МОДЕЛИ БРОНХИАЛЬНОГО ДЕРЕВА ПО КТ-ИЗОБРАЖЕНИЮ
АВТОМАТИЗИРОВАННАЯ ГЕНЕРАЦИЯ ТРЁХМЕРНОЙ МОДЕЛИ БРОНХИАЛЬНОГО ДЕРЕВА ПО КТ-ИЗОБРАЖЕНИЮ
Аннотация
В статье представлена разработка алгоритма автоматической сегментации бронхиального дерева на КТ-изображениях и построения его трёхмерной модели. Описан подход, основанный на текстурном анализе и использовании референсных сегментов, а также обучение различных алгоритмов машинного обучения, включая Decision Tree и Random Forest. Проведён анализ эффективности на выборке из 15 КТ-снимков, включающей более 300 сегментов. Представлены метрики качества (Accuracy, Recall, Precision, F1, IoU), результаты показали преимущество Random Forest для данной задачи. Предложены направления дальнейшего усовершенствования алгоритма. Разработка может быть полезна для клинической практики при планировании бронхопластики, а также в качестве инструмента диагностики и визуализации сложных структур дыхательной системы.
1. Введение
Заболевания органов дыхания являются распространенной проблемой здоровья, ухудшающей качество жизни и часто устойчивой к самолечению. Влияние экологических факторов на здоровье дыхательной системы приводит к увеличению числа пациентов с такими заболеваниями.
Бронхопластика — это сложная хирургическая процедура, направленная на исправление аномалий бронхов. Она включает удаление пораженных участков и восстановление анатомической целостности бронхов, что позволяет нормализовать воздушный поток и функцию легких. Решение о проведении бронхопластики требует глубокого анализа клинических факторов, таких как степень опухолевого процесса и общее состояние пациента .
На данный момент не существуют стандартизированных протоколов для бронхопластики, что делает каждый случай уникальным. Хирурги должны учитывать индивидуальные особенности заболевания и пациента для разработки оптимального плана лечения. Понимание анатомии бронхиального дерева критически важно для успешного вмешательства, и для этого часто используются КТ. Однако интерпретация КТ-изображений может быть сложной, что подчеркивает необходимость разработки более эффективных методов визуализации.
Сложности анализа КТ-данных ограничивают точность хирургического вмешательства, а низкая контрастность изображений затрудняет различение мелких деталей. Это особенно критично для операций на бронхах, где точность измерений важна для предотвращения повреждения окружающих тканей. Недостаточная контрастность может привести к ошибкам в диагностике и игнорированию серьезных проблем, что недопустимо в медицине .
На основании анализа проблематики и литературы целью данной работы была определена разработка алгоритма автоматической сегментации бронхиального дерева на снимках КТ и построения его трехмерной модели.
2. Набор данных
Для данной работы был использован датасет из открытого источника Kaggle Finding and Measuring Lungs in CT Data . Данный датасет включает в себя 4 КТ изображения грудной клетки. Также дополнительно были использованы изображения из других источников. В результате был собран комбинированный датасет из 15 снимков, основные параметры которых представлены в Таблице 1.
Таблица 1 - Параметры использованных снимков
№ | Ширина (в вокселях) | Высота (в вокселях) | Число срезов |
1 | 312 | 512 | 512 |
2 | 456 | 512 | 512 |
3 | 301 | 512 | 512 |
4 | 117 | 512 | 512 |
5 | 312 | 512 | 512 |
6 | 420 | 512 | 512 |
7 | 456 | 512 | 512 |
8 | 305 | 512 | 512 |
9 | 305 | 512 | 512 |
10 | 305 | 512 | 512 |
11 | 305 | 512 | 512 |
12 | 305 | 512 | 512 |
13 | 184 | 512 | 512 |
14 | 184 | 512 | 512 |
15 | 326 | 512 | 512 |
Разрабатываемый алгоритм предназначен для создания двоичной маски, которая будет классифицировать пиксели изображения на две категории: «бронхи» и «фон». В этой маске пиксели, соответствующие бронхам, будут обозначены как «1», что условно указывает на их принадлежность к классу «бронхи». В то же время пиксели, которые не относятся к бронхам и представляют собой фоновую ткань или пустое пространство, будут обозначены как «0», что соответствует классу «фон».
Для удобства визуализации и анализа, предполагается, что маска будет доступна не только в виде отдельного слоя, но и может быть наложена на исходное изображение. Это позволит пользователям легко сравнивать маску с исходными данными и оценивать точность алгоритма.
Чтобы оптимизировать использование памяти устройства и упростить обработку данных, предлагается представить маску в форме трехмерной бинарной матрицы или массива. Это сократит объем занимаемой памяти, поскольку для хранения каждого пикселя будет использоваться только один бит информации. Кроме того, такое представление упрощает интеграцию маски в различные системы обработки изображений и анализа данных, обеспечивая эффективную работу с большими объемами информации.
3. Описание используемых алгоритмов
Для выполнения данной работы был составлен алгоритм, состоящий из 2 основных элементов. В первую часть входят считывание и подготовка изображения, выделение референсных сегментов и проведение текстурного анализа. Ко второй части относятся калибровка алгоритмов машинного обучения на основе референсных сегментов и сканирование изображения для получения полной маски.
4. Референсные сегменты
Референсные сегменты играют ключевую роль в процессе текстурного анализа изображений, поскольку они служат эталонными образцами для определения границ параметров анализа. В контексте данного проекта, эти сегменты выбираются вручную в момент загрузки изображения для последующей разметки, что позволяет точно настроить параметры алгоритма под конкретные задачи.
Каждый такой сегмент представляет собой выделенную область на матрице изображения, которой присваивается определённый класс. В вашем случае, класс «1» соответствует бронхам — объектам, которые представляют интерес для исследования, в то время как класс «0» обозначает фоновые элементы, не несущие информации о бронхах. Для достоверности анализа и обучения алгоритма, необходимо выделить минимум по 10 сегментов для каждого класса на каждом изображении.
Дополнительно, для оценки точности и качества работы разрабатываемого алгоритма, было решено включить в анализ ещё 20 дополнительных сегментов, которые также разделяются на классы «1» и «0». Это позволит провести более глубокий анализ работы алгоритма и его способность корректно классифицировать интересующие объекты.
В итоге, для обучения и последующего тестирования алгоритма был сформирован датасет, включающий в себя 300 референсных сегментов для каждой из фаз. Такой подход обеспечивает алгоритм достаточным количеством данных для обучения и позволяет провести всестороннее тестирование его эффективности в реальных условиях.
5. Текстурный анализ
Текстурный анализ — это метод структурного анализа для определения расположения элементов в исследуемом объекте. В рентгенологии это подразумевает распределение пикселей или вокселей различной интенсивности по снимку.
Алгоритм текстурного анализа основан на определении параметров элемента на основе окружающих его других элементов. Для данной работы был использован алгоритм для двумерной матрицы из 9 элементов для определения параметров центрального элемента. Его упрощенная схема представлена на рисунке 1.
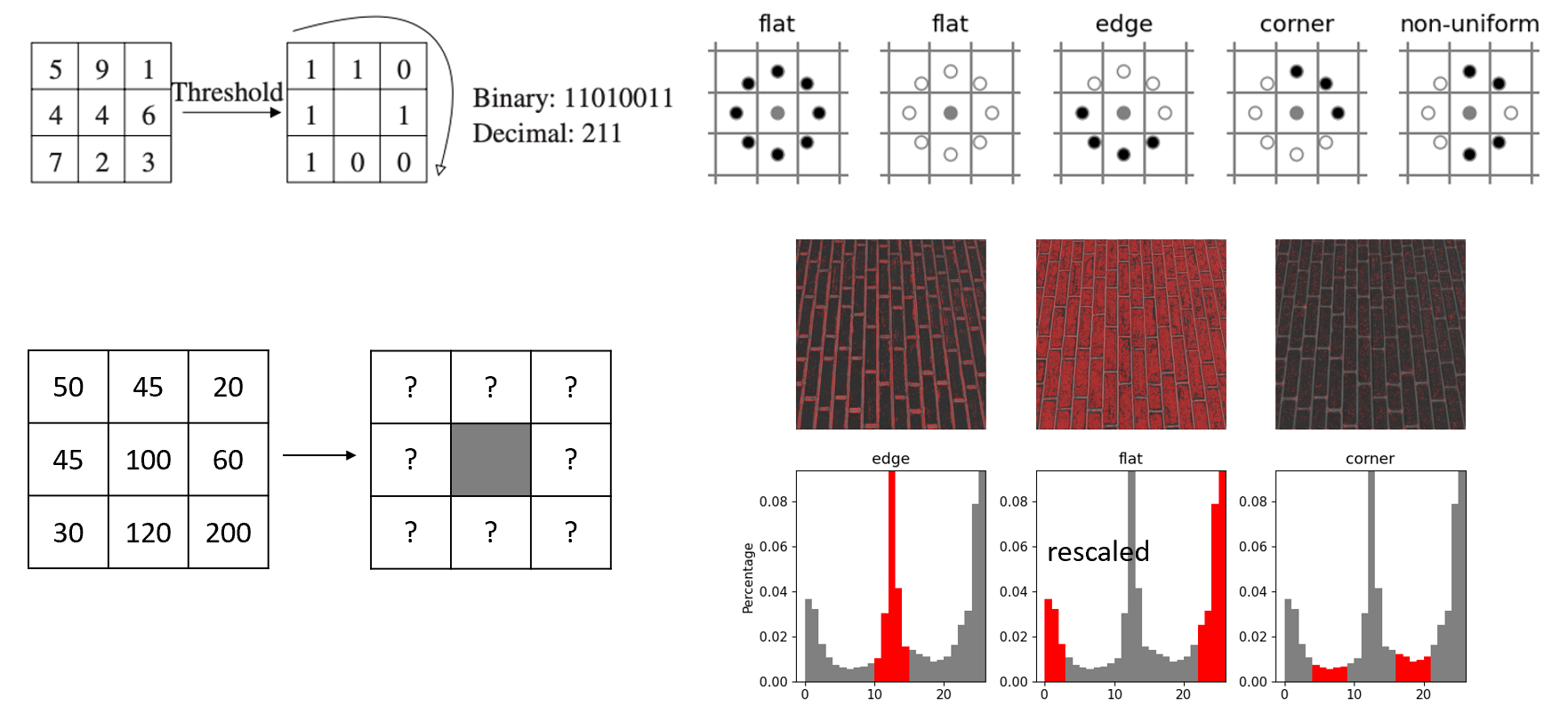
Рисунок 1 - Пример упрощенного алгоритма текстурного анализа

Рисунок 2 - Примеры локального бинарного паттерна
6. Использованные алгоритмы машинного обучения
Для обработки полученных данных были использованы различные алгоритмы машинного обучения для выбора наилучшего результата: метод опорных векторов (Support Vector Machine), дерево решений (Decision Tree), логистическая регрессия (Logistic Regression), а также алгоритмы адаптивного бустинга (Аdaboost) и случайный лес (Random Forest) , , , .
Все применяемые методы подразумевают обучение с учителем. При таком подходе сначала происходит калибровка алгоритма на заранее подготовленном наборе данных с уже известными метками классов, после чего алгоритм на основании откалиброванных параметров проводит анализ новых данных, определяя их метки классов.
Также для улучшения результатов на небольшом наборе данных был применён метод кросс-валидации. Он основан на разделении данных на приблизительно равные части (чаще всего 3 или 5 частей, но возможно использовать любое количество) и использовании одной части в качестве тестового набора данных, а остальных — в качестве тренировочного. В ходе каждой итерации происходит смена используемого тестового набора, что позволяет оптимизировать выходные параметры практически любого алгоритма. В данной работе было принято решение использовать деление на 5 частей.
7. Анализ результатов работы алгоритмов
Для анализа результатов были использованы несколько способов. Первый способ заключается в использовании тестовых референсных сегментов для изображения. Данные о результатах представлены в таблице 2. Для определения наиболее подходящего фрагмента были выбраны метрики Accuracy, Precision, Recall и F1 score.
Таблица 2 - Результаты сравнения качества алгоритмов на тестовых сегментах
Название алгоритма | Accuracy, % | Precision, % | Recall, % | F1 score, % |
SVM | 50 | 0 | 0 | 0 |
Decision Tree | 70 | 63 | 100 | 77 |
Logistic Regression | 50 | 80 | 10 | 10 |
Adaboost | 50 | 50 | 60 | 55 |
Random Forest | 80 | 71 | 100 | 83 |
На основании полученных данных можно уже сделать вывод, что такие алгоритмы как Logistic Regression и Support Vector Machine (SVM) плохо справляются с данной задачей и, скорее всего, не будут использованы в дальнейших разработках. Тогда как наилучшим образом показали себя алгоритмы Decision Tree и Random Forest.
Вторым способом проверки было выбрано создание маски для сегмента изображения размерами 100х100х1 вокселей. Данные размеры были выбраны для упрощения визуализации и анализа. Результаты анализа представлены в таблице 3. В качестве характеристических значений полученных результатов были использованы метрики Accuracy, Recall и IoU (Intersection over Union).
Таблица 3 - Результаты формирования маски для сегмента 100х100х1 вокселей
Название алгоритма | Accuracy, % | Recall, % | IoU, % |
SVM | 50 | 0 | 0 |
Decision Tree | 62 | 100 | 37 |
Logistic regression | 26 | 8 | 8 |
Adaboost | 34 | 43 | 5 |
Random Forest | 74 | 100 | 44 |
На рисунках 3–7 представлены результаты формирования маски различными алгоритмами в сравнении размеченной вручную маской.
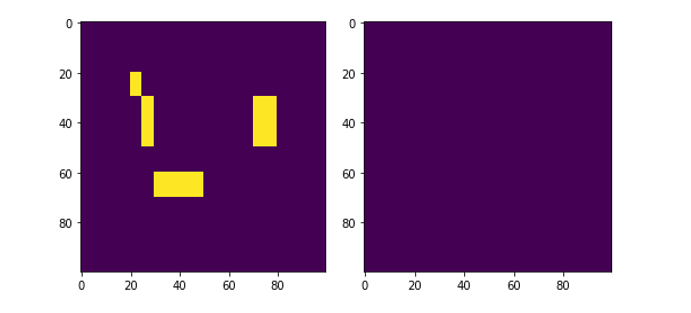
Рисунок 3 - Маски выбранного референсного сегмента, созданные вручную (слева) и алгоритмом SVM (справа)
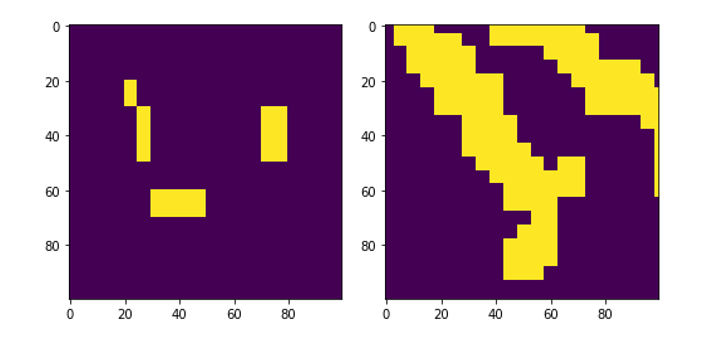
Рисунок 4 - Маски выбранного референсного сегмента, созданные вручную (слева) и алгоритмом Adaboost (справа)
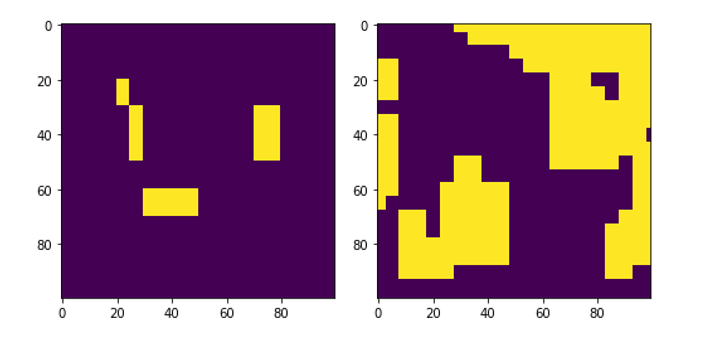
Рисунок 5 - Маски выбранного референсного сегмента, созданные вручную (слева) и алгоритмом Logistic Regression (справа)
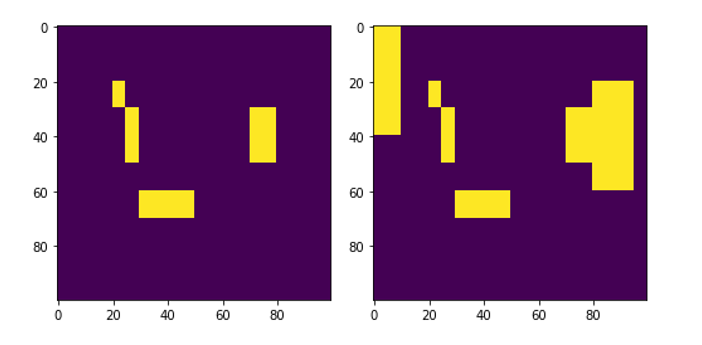
Рисунок 6 - Маски выбранного референсного сегмента, созданные вручную (слева) и алгоритмом Decision Tree (справа)
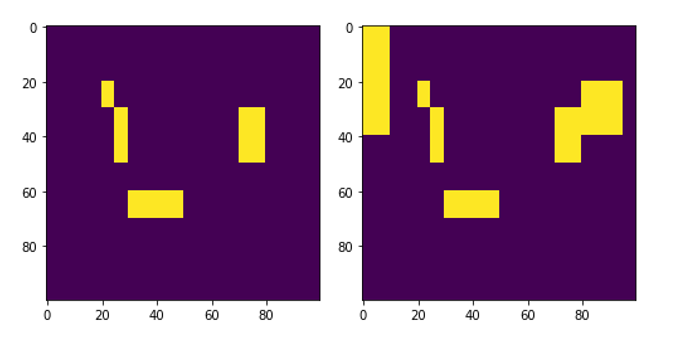
Рисунок 7 - Маски выбранного референсного сегмента, созданные вручную (слева) и алгоритмом Random Forest (справа)
8. Заключение
В результате работы был достигнут значительный прогресс в выполнении заранее определенных задач. Был проведён тщательный анализ научных источников, включая академические журналы, конференционные материалы и другие публикации, что позволило сформировать достаточную базу данных для последующего сравнения и выбора аналогов. В результате этого анализа были выработаны ключевые критерии и условия, которые должен был удовлетворять разрабатываемый алгоритм, чтобы соответствовать поставленным целям.
Далее был создан универсальный алгоритм, способный удовлетворить эти условия. Этот алгоритм был спроектирован таким образом, чтобы быть гибким и адаптивным, обладая возможностью интеграции с различными типами данных и сценариями использования. В ходе разработки было уделено особое внимание анализу основных типов алгоритмов машинного обучения, что позволило идентифицировать и выбрать наиболее эффективный и подходящий вариант для решения конкретной задачи. Выбранный алгоритм демонстрирует высокую степень точности и надежности, что подтверждается результатами тестирования и валидации.
В рамках текущего исследования был проведен глубокий анализ потенциальных направлений для дальнейшего усовершенствования и модификации разработанного алгоритма. Одним из ключевых аспектов, который был выделен как приоритетный, является создание механизма для систематического накопления референсных сегментов бронхиального дерева. Это позволит значительно расширить и обогатить используемый датасет, что, в свою очередь, улучшит качество и точность алгоритма за счет обучения на более разнообразной и представительной выборке данных.
Дополнительные модификации, которые были предложены для внедрения, включают в себя улучшенную визуализацию исходных изображений с применением наложенной маски сегментации. Это не только облегчит визуальный анализ результатов работы алгоритма, но и позволит пользователям более интуитивно оценивать точность сегментации. Также была предложена фильтрация входных изображений для подавления шумов, что улучшит четкость изображений и повысит общую точность сегментации.
Предложенные улучшения и модификации открывают новые возможности для повышения эффективности алгоритма и его применения в клинической практике, что может оказать значительное влияние на диагностику и лечение респираторных заболеваний.