СТРАТЕГИЯ БАЛАНСИРОВКИ НАГРУЗКИ И УПРАВЛЕНИЕ РАЗНОРОДНЫМИ ХРАНИЛИЩАМИ ДАННЫХ С ВЫСОКОЙ СТЕПЕНЬЮ ПАРАЛЛЕЛИЗМА
СТРАТЕГИЯ БАЛАНСИРОВКИ НАГРУЗКИ И УПРАВЛЕНИЕ РАЗНОРОДНЫМИ ХРАНИЛИЩАМИ ДАННЫХ С ВЫСОКОЙ СТЕПЕНЬЮ ПАРАЛЛЕЛИЗМА
Аннотация
В современном мире наблюдается экспоненциальный рост объёма данных и высокий уровень параллельного доступа в мощных Интернет вещах (PIoT), что требует эффективных стратегий балансировки нагрузки для равномерного распределения сетевого трафика между несколькими серверами. Это необходимо для повышения общей скорости отклика и доступности системы. Целью данного исследования является разработка стратегии балансировки нагрузки, основанной на четырёх и семи уровнях доступа IoT. Для достижения поставленной цели были использованы следующие материалы и методы: анализ существующих стратегий балансировки нагрузки; изучение протоколов транспортного и прикладного уровней; разработка новой стратегии балансировки нагрузки. В результате исследования была предложена новая стратегия балансировки нагрузки, основанная на сочетании четырёх- и семиуровневых подходов. Это позволит добиться более эффективного и гибкого распределения трафика в IoT, повысив производительность системы и удовлетворив требования к обработке сложных запросов.
1. Введение
В мощном Интернете вещей (PIoT) используются сотни миллионов терминальных устройств. Даже если данные загружаются пакетами, в часы пик они будут достигать более десяти миллионов уровней параллелизма. Технология доступа с высокой степенью параллелизма основана на балансировке нагрузки, оптимизации трафика и других стратегиях для достижения оптимального выбора сетевых соединений и эффективного, сбалансированного использования облачных ресурсов . Балансировка нагрузки необходима в системах с высокой степенью параллелизма и легкодоступности . Цель состоит в том, чтобы равномерно распределить сетевой трафик между несколькими серверами, чтобы повысить общую скорость отклика и доступность системы. Чтобы справиться с экспоненциальным ростом объема данных и высоким уровнем параллельного доступа, крупные центры обработки данных должны развёртывать модули балансировки нагрузки для обработки больших внешних или внутренних рабочих нагрузок и улучшения использования ресурсов .
В настоящее время стратегия балансировки нагрузки платформы управления IoT обычно заключается в развёртывании программного обеспечения для балансировки нагрузки, такого как NGINX (HTTP-сервер и обратный прокси-сервер, почтовый прокси-сервер, а также TCP/UDP прокси-сервер общего назначения. Nginx обслуживает серверы многих высоконагруженных российских сайтов, таких как Яндекс, Mail.Ru, ВКонтакте и Рамблер) , на сервере доступа для достижения балансировки нагрузки на нескольких уровнях, а именно на уровне приложений. Этот метод может удовлетворить требования к параллельному доступу от 100000 до одного миллиона уровней; однако трудно поддерживать высокие требования к параллельному доступу более чем на 10 миллионах уровней.
Таким образом, предлагается стратегия балансировки нагрузки, основанная на четырёх и семи уровнях доступа IoT, для достижения высокого уровня параллелизма – более десяти миллионов уровней . Четырёхуровневая балансировка нагрузки основана на протоколах транспортного уровня, таких как TCP и UDP. Он распределяет трафик между различными серверами на основе IP-адреса клиента и номера порта. Его основным преимуществом является высокая скорость обработки, поскольку он фокусируется только на сетевой информации более низкого уровня. Четырёхуровневая балансировка нагрузки подходит для сценариев со строгими требованиями к задержке.
Семиуровневая балансировка нагрузки основана на протоколах прикладного уровня, таких как HTTP и HTTPS. Она может распределять трафик между различными серверами на основе содержимого запроса, такого как URL-адреса, информация заголовка и самих сообщений. Поскольку он фокусируется на сетевой информации более высокого уровня, семиуровневая балансировка нагрузки позволяет реализовать более сложные стратегии распределения. Сочетание четырёх- и семиуровневых стратегий балансировки нагрузки позволяет добиться более эффективного и гибкого распределения трафика в IoT. Например, четырёхуровневый балансировщик нагрузки может обрабатывать несколько запросов с низкой задержкой, тогда как сложные запросы прикладного уровня могут направляться для обработки в семиуровневый балансировщик нагрузки. Это повышает производительность системы и удовлетворяет требованиям к обработке сложных запросов. В частности, коммутатор уровня 4 предоставляет единый IP-адрес доступа для внешнего мира. Терминальному устройству и пограничному IoT-агенту не нужно знать реальный IP-адрес, соответствующий каждому серверу на облачной платформе. Трафик внешних данных, получаемый облачной платформой, должен проходить через коммутатор уровня 4, который отвечает за пересылку запроса терминального устройства и пограничного агента Интернета вещей на сервер, а затем за установление TCP-соединения между терминальным устройством, пограничным агентом интернета вещей и сервером. В режиме NAT (от англ. Network Address Translation – «преобразование сетевых адресов») – это механизм в сетях TCP/IP, позволяющий преобразовывать IP-адреса транзитных пакетов , когда уровень 4 обменивается данными и устройство планирует запросы на доступ, сначала преобразуется IP-адрес назначения, а затем запрос на доступ пересылается на каждый сервер внешнего доступа в серверной части. Таким образом, четырёхуровневая балансировка нагрузки позволяет объединить терминал доступа и оборудование пограничного агента Интернета вещей и передавать исходящую информацию об оборудовании программно-определяемому агенту доступа в соответствии с установленной стратегией балансировки нагрузки.
2. Основные результаты
2.1. Управление разнородными хранилищами данных с несколькими источниками
Объём данных мощных IoT (PIoT) достиг петабайтного масштаба, что означает, что система должна справляться с проблемами, связанными с большим объемом данных и различными форматами данных. Диапазон скоростей генерации данных обширен, включая миллисекундные измерения вектора в широком диапазоне, данные в режиме реального времени, данные мониторинга стационарного состояния второго уровня, микрометеорологические данные минутного уровня , данные о циркуляции эксплуатационных характеристик часового уровня и экспериментальные данные оборудования с более длительным циклом . Существует множество источников данных и сложных методов взаимодействия, таких как веб-сервисы, специальные протоколы и специальные форматы файлов . Существует много типов данных, таких как данные в реальном времени, текстовые, мультимедийные, временные ряды, структурированные, полуструктурированные и неструктурированные данные и др. , . Отсутствие эффективного управления различными типами данных и трудности с формированием эффективной информации из изолированных данных значительно затрудняют управление, эксплуатацию и принятие быстрых решений .
В области хранения больших данных команда разработчиков Hadoop разработала файловую систему Google с открытым исходным кодом (GFS) и внедрила распределенную файловую систему Hadoop с открытым исходным кодом (HDFS) GFS. Программная библиотека Apache Hadoop – это платформа, которая позволяет распределять обработку больших наборов данных между кластерами компьютеров с использованием простых программных моделей . Что касается управления данными, то наиболее известной является технология управления данными Bigtable, предложенная Google. Bigtable – это распределенная система хранения, предназначенная для управления структурированными данными , . Эти данные могут быть расширены до очень больших масштабов, таких как петабайты данных на тысячах коммерческих серверов. Основными источниками данных PIoT являются данные управления, данные мониторинга, социальные сети и метеорологические данные, которые характеризуются различными источниками, сложными типами, различными мощностями и высокими уровнями управления безопасностью и контроля , . Для управления большими и разнообразными данными и метаданными нужна надёжная техническая архитектура, которая обеспечит контроль над данными, их качеством, структурой, безопасностью , а также эффективное управление ими.
2.2. Управление основными данными и метаданными
Основные данные в основном разрабатываются внутри систем и извлекаются из неструктурированных данных, которые были проанализированы или не исследованы. Таким образом, необходимо обеспечить плавную интеграцию метаданных неструктурированного контента с традиционным управлением метаданными. Основное содержание управления основными данными и метаданными проиллюстрировано на рис. 1.

Рисунок 1 - Распределение контента для управления основными данными и метаданными
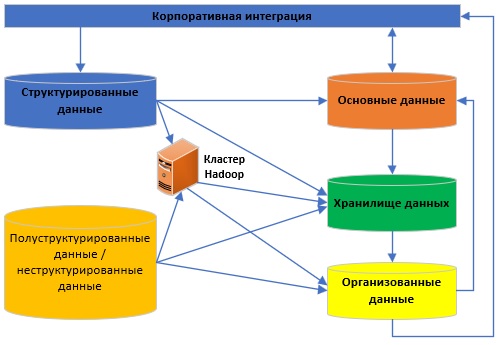
Рисунок 2 - Организация потока данных
Качество данных относится к способности данных удовлетворять бизнес, системным и техническим требованиям организации. Качество данных обычно описывается в соответствии с целостностью, своевременностью, точностью, непротиворечивостью и актуальностью. Качество данных в средах больших данных определяется случаями использования. Приложения предъявляют разные требования к качеству данных. Например, анализ потока кликов и обнаружение вторжений требуют разных уровней точности. В этой среде необходимо пересмотреть правила, политики и стандарты очистки качества данных.
Структура данных описывает внутреннюю организацию данных. Она включает в себя множество уровней данных, начиная от междисциплинарных моделей данных и заканчивая независимыми системами. Влияние структуры данных в среде больших данных в первую очередь обусловлено разнообразием данных. Стандарты классификации данных и логические модели данных должны адаптироваться к содержанию неструктурированных данных и процессу извлечения структурированной информации из неструктурированных данных.
Безопасность данных – это процесс и технология, которые гарантируют, что к данным нельзя получить доступ, просмотреть, отредактировать или удалить их без разрешения. При интеграции различных источников данных необходимо проанализировать и стандартизировать соответствующие политики безопасности и требования в соответствии с местными, национальными и международными правилами. Это включает в себя:
1 – безопасность доступа к данным: авторизацию доступа к хост-системе, хранение базы данных на разных уровнях безопасности и разделение пользователей для различных приложений;
2 – безопасность хранения данных: регулярное полное резервное копирование и инкрементное резервное копирование в режиме реального времени, которые могут поддерживать быстрое восстановление данных;
3 – аудит безопасности данных: записи журнала доступа к файлам, сети и другим данным, независимо хранящиеся журналы и регулярно проверяемые операции с конфиденциальными данными.
Управление службами данных обеспечивает унифицированный доступ к различным службам данных через сервисные интерфейсы. Благодаря внедрению стандартизированного протокола доступа к интерфейсу и унифицированного контроля доступа пользователей и данных для обеспечения безопасности данных, сервис может быть расширен и настроен в соответствии с будущими требованиями к доступу к данным.
Информация, хранящаяся в PIoT, является массивной, распределенной, разнообразной, действующей в режиме реального времени, динамичной и интерактивной . Границы сети на стороне терминала станут нечёткими и сложными. Индивидуальный доступ между данными и пользователями в рамках обычной схемы шифрования с открытым ключом не может соответствовать требованиям сложной системы PIoT. Механизм нулевого доверия был впервые предложен Kindervag. Его основная идея заключается в том, что по умолчанию не следует доверять человеку, устройству или системе внутри сети или за её пределами. Она должна основываться на доверительной основе аутентификации и авторизации с жёстким контролем доступа. После многолетней практики Google в 2014 году выпустила BeyondCorp, архитектуру с нулевым доверием, которая постепенно получила признание в отрасли. Нулевое доверие подрывает парадигму контроля доступа и направляет архитектуру безопасности от сети к идентификации, ориентированной на личность. Его основным требованием является управление доступом, ориентированное на личность .
Построение PIoT основано на построении унифицированной идентификации с использованием архитектуры сетевой безопасности с нулевым доверием в качестве эталона для проведения унифицированного управления идентификацией и обеспечения аутентификации между устройствами и службами PIoT. Надежное соединение, взаимодействие в области безопасности, интеллектуальная защита, а также динамическое предотвращение и контроль достигаются благодаря защите архитектуры PIoT «облачный интерфейс управления». Архитектура защиты PIoT, основанная на механизме нулевого доверия, проиллюстрирована на рис. 3.
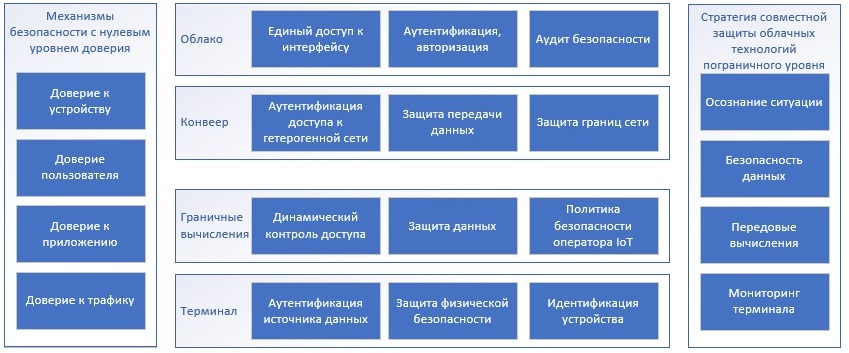
Рисунок 3 - Поток доступа к данным PIoT основан на многоуровневой балансировке нагрузки
3. Заключение
В заключении можно отметить, что предложенная стратегия балансировки нагрузки, основанная на сочетании четырёх- и семиуровневых подходов, позволяет эффективно и гибко распределять трафик в IoT, повышая производительность системы и удовлетворяя требования к обработке сложных запросов. Это особенно актуально в условиях экспоненциального роста объёма данных и высокого уровня параллельного доступа в мощный Интернет вещей (PIoT), где требуется балансировка нагрузки для равномерного распределения сетевого трафика между несколькими серверами. С увеличением объёма данных и разнообразием их типов, становится критически важным наличие эффективных инструментов и методов для управления этими данными.
Однако, несмотря на существующие технологии, управление данными в PIoT остается сложной задачей из-за разнообразия источников данных, их сложности и высоких требований к безопасности и контролю. Для успешного управления данными необходима надёжная техническая архитектура, обеспечивающая контроль над данными, их качеством, структурой, безопасностью, а также эффективное управление ими.
Исследование подчёркивает важность разработки и внедрения новых технологий и методов балансировки нагрузки для обеспечения стабильной и эффективной работы систем IoT в условиях растущих требований к объёму обрабатываемых данных и уровню параллелизма.