СЕТЕВАЯ МОДЕЛЬ АГГЛЮТИНАТИВНОЙ МОРФОЛОГИИ

Гречачин В. А.
ORCID: 0000-0002-1595-0995, аспирант,
Башкирский государственный университет
Работа выполнена в рамках поддержанного РФФИ проекта № 17-04-00193 «Исторический корпус башкирского языка»
СЕТЕВАЯ МОДЕЛЬ АГГЛЮТИНАТИВНОЙ МОРФОЛОГИИ
Аннотация
Статья посвящена разработке модели агглютинативной морфологии, основанной на теории графов. Теория графов, или метод сетей, является современным подходом в теоретической и прикладной лингвистике. Описаны основные характеристики такой модели. Рассмотрены возможности применения модели для исследовательских и прикладных целей. Представлена реализация модели для современного башкирского языка и для старотюркского. Показана эффективность применения разработанных моделей. Рассмотрена работа морфологического парсера для старотюркского языка, в основу которого легла представленная модель. Ключевые слова: теория графов, морфология, башкирский язык, старотюркский язык, обработка естественных языков.Grechanin V. A.
ORCID: 0000-0002-1595-0995, Postgraduate Student,
Bashkir State University
The work was carried out within the framework of the project supported by the Russian Fund of Federal Property No. 17-04-00193 “Historical Corpus of the Bashkir Language”
NETWORK MODEL OF AGGLUTINATIVE MORPHOLOGY
Abstract
The article is devoted to the development of the model of agglutinative morphology based on the graph theory. The graph theory or the method of networks is a modern approach in theoretical and applied linguistics. The main characteristics of such a model are described in the article. Possible use of the model for research and application purposes is considered. The implementation of the model for the modern Bashkir language and as well as for the Old Turkic language is presented. The effectiveness of the application of the developed models is shown. The work of the morphological parser for the Old Turkic language is considered based on the presented model. Keywords: graph theory, morphology, Bashkir language, Old Turkic language, natural language processing. Работа посвящена приложению теории графов к моделированию агглютинативной морфологии на примере тюркских языков. Графом называется абстрактный математический объект, представляющий собой множество вершин и их сочетаний, которые называют ребрами [3]. В англоязычной терминологии принято использовать термин complex network для обозначения конкретного примера графа [10]. В русскоязычной литературе, посвященной complex networks, используют эквивалентный термин сеть. Таким образом, термины граф, комплексная сеть, сеть можно использовать как взаимозаменяемые. На сегодняшний день методы автоматической обработки естественных языков уже приобрели популярность (в англоязычной терминологии для обозначения этих методов принято использовать аббревиатуру “natural language processing” - NLP). Сетевая модель агглютинативной морфологии, в частности, для тюркских языков, может быть использована как для разработки инструментов NLP, так и для анализа лингвистических данных. Актуальность исследования и разработки методов NLP (natural language processing) для «малых» языков обусловлена тем, что языки народов России представлены в Интернете и со временем количество текстов на этих языках возрастает, а оставшиеся тексты «мертвых» языков, которые необходимо сохранить как культурные памятники, лучше всего хранить в электронном и структурированном виде. Попытки разработать модель агглютинативной морфологии для тюркских языков предпринимались ранее. Например, в [6] автор предложил модель словоизменительной системы. Разработанная автором модель оказалась сложной и не нашла применения, кроме как для автоматического порождения словоформ. В данной работе мы не станем рассматривать все существующие модели агглютинативной морфологии, а рассмотрим только то, что связано с применением теории графов к агглютинативной морфологии. Наиболее близкой по теме оказалась работа [2], где авторы использовали сетевой подход для описания морфологии башкирского языка. Кроме того, авторы проанализировали труды, где обсуждались вопросы, связанные с методами сетей и морфологией, и пришли к выводу, что «к настоящему моменту теоретическая морфология и методика сетей далеки друг от друга» [2, с. 24]. Также авторы рассматривают принципы работы морфологического анализатора (далее парсер) для башкирского языка bashmorph. Отметим, что алгоритм парсера не имеет никакого отношения к методу сетей. Метод сетей авторы применяли для описания морфологии башкирского языка. Им удалось построить сеть, в которой вершинами являлись аффиксы, которые были связаны ребрами. Ребра отражали сочетаемость аффиксов. Источником данных послужил корпус текстов газеты «Йәшлек» («Молодость») за 2007—2014 гг., который включал 5,8 млн словоупотреблений. Перед тем, как построить сеть, авторы произвели морфологический разбор словоформ при помощи парсера bashmorph. Авторам удалось подсчитать количество обнаруженных аффиксов, среднюю частоту сочетаемости пар аффиксов, максимальную длину цепочки аффиксов. Полноту охвата авторами морфологической системы башкирского языка ставит под сомнение тот факт, что bashmorph не учитывает некоторые словообразовательные аффиксы. Например, ‘тәбрик’ (‘приветствие’) основа существительного и словообразовательный аффикс глагола -лә дают ‘тәбрик-лә’ (‘приветствие’). Кроме того, нами были встречены неверные разборы [4] с однобуквенными аффиксами, например, в слове ‘тәбрикләнем’ (‘я поприветствовал’) bashmorph выделяет аффикс залога -н перед показателем лица -ем, что невозможно в башкирском языке. Отметим, что вместе с ошибочным был дан и правильный разбор ‘тәбриклә-не-м’, но он не учитывал словообразовательный аффикс. Для того, чтобы приложить теорию графов к агглютинативной морфологии, рассмотрим ключевые особенности агглютинации. Мы основываемся на том, что в агглютинативных языках преобладает такой способ образования производных и грамматических форм слов, при котором аффиксы присоединяются к корню, сополагаются друг с другом, не изменяясь при этом существенным образом, каждый аффикс имеет только одно грамматическое значение [7]. Для агглютинативных языков характерно, что аффиксы однозначны (в подавляющем большинстве), в них отсутствуют фузии, таким образом морфемные швы всегда очевидны, последовательность аффиксации в грамматических формах постоянна. Именно последнее является ключевой особенностью агглютинации при построении сети. Причем на вопрос: почему последовательность аффиксации в агглютинативных языках постоянна? - нет однозначного ответа. Строгая последовательность аффиксации может быть объяснена семантической связностью аффиксов со значением слова [9]. Например, аффикс числа больше связан со значением слова, нежели аффикс падежа. В башкирском ‘бала-лар-ҙы’ (‘детей’), где -лар показатель множественного числа, -ҙы – аффикс местно-временного падежа. Можно также предположить, что строгая последовательность аффиксации может быть обусловлена структурами окружающего мира, закономерностью природных процессов, примером может послужить процесс смены дня и ночи, которому сопутствуют определенные события – восход солнца на Востоке, закат на Западе. В этой работе мы не будем рассматривать причины строгой последовательность аффиксации в агглютинативных языках. Положим, что утверждение о постоянстве позиции аффиксов относительно друг друга в словоформе – это аксиома. Теперь рассмотрим тип и характеристики сети, которые наилучшим образом смогли бы описать агглютинативную морфологию. Прежде всего мы используем ориентированную сеть, то есть в этой сети ребра обладают направленностью, их называют дугами. Таким образом, вершины обладают направленной связью. В этой сети нет изолированных вершин, то есть все вершины соединены дугами. Мы полагаем, что все аффиксы в агглютинативных языках можно разделить на классы по грамматическому значению. Например, один класс включает возможные аффиксы множественного числа, другой - аффиксы даnеkьного падежа. В башкирском языке в один класс попадут -лар, -тар, -дар, -ҙар и их алломорфы -ләр, -тәр, -дәр, -ҙәр [1]. В урало-поволжском тюрки (далее старотюркском) фонетических вариантов в этом классе окажется меньше: -лар, -ләр [8]. После того, как мы определили классы по грамматическому значению, положим, что каждый класс, каждое грамматическое значение – это абстрактные объекты, которые вступают в определенные позиционные отношения между собой. Эти позиционные отношения обусловлены тем, что положение аффиксов относительно друг друга постоянно. Теперь нашей задачей будет соотнести эти положения с теорией графов. Модель агглютинативной морфологии, которую мы предлагаем, представляет собой сеть, в которой множество вершин – это классы аффиксов с определенными грамматическими значениями и показатели частей речи; дуги отражают позиционные отношения между вершинами. Таким образом, в сетевой модели морфологии башкирского языка есть вершина ‘Plural’, которая является абстракцией грамматического значения множественного числа, и дуги, представленные парами типа (‘Plural’, ‘Ablative’) и (‘Possessive’, ‘Plural’), которые показывают возможное окружение для ‘Plural’. То есть в словоформах башкирского языка перед показателем множественного числа может стоять показатель принадлежности, а после – показатель исходного падежа. В сетевой модели количество пар с ‘Plural’ показывает все возможные варианты совместной встречаемости показателя множественного числа с другими показателями. Также в ней есть вершины, означающие части речи, например, вершина ‘NOUN’ (существительное), и пары типа (‘NOUN’, ’Plural’), которые показывают какие показатели могут встречаться после основы определенной части речи. Для каждой вершины есть свой набор пар. Путь в этой модели, то есть набор вершин, соединенных дугами, который начинается вершинами, означающими часть речи, представляет собой модель словоформы.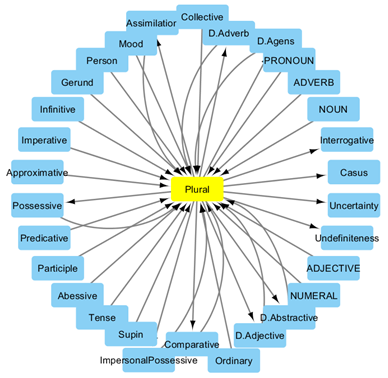
Рис. 1 – Подграф сетевой модели современного башкирского языка
Представим подграф сетевой модели башкирской морфологии, который включает вершину ‘Plural’ и вершины, которые имеют общие дуги с ‘Plural’ (см. рис. 1). Эта сеть показывает позиционные отношения показателя множественного числа с другими показателями, которые могут встречаться в словоформах как перед ним, так и после него. Из сети следует, что показатель принадлежности ‘Possessive’ может стоять как перед показателем множественного числа, так и после. Большей частью аффиксы множественного числа присоединяются непосредственно к основе слова, например, ‘китап-тар-ым’ (‘мои книги’). Существуют случаи, например, в терминах родства, когда аффикс приндалежности стоит перед аффиксом множественного числа - ‘ағай-ым-дар’ (‘мои братья’) [1]. Функционирование показателей множественного числа в старотюркском не отличается существенным образом. В современном башкирском отсутствуют некоторые грамматические значения, поэтому, чтобы адаптировать наш подграф для тюрки, нужно добавить показатель комитатива. Теперь рассмотрим путь (см. рис. 2) в сетях башкирской и старотюркской морфологии. Данный путь есть в обоих сетях и представляет собой некоторую последовательность грамматических показателей, которая следует за основой существительного. Такую последовательность можно встретить, например, в словах ‘эш-се-ләр-ҙеке’ (башк. ‘принадлежащий рабочим’) и ‘ил-че-ләр-неке’ (старотюрк. ‘принадлежащий послам’).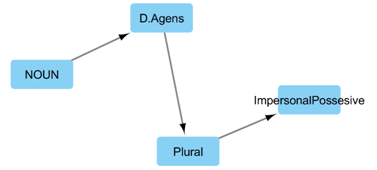
Рис. 2 – Путь в сетевой модели старотюркского языка
Таким образом, нам удалось разработать сетевые морфологические модели башкирского и старотюркского языков. Последняя легла в основу разработанной нами программы морфологического анализа старотюркского языка [11], которая представлена в сети Интернет и доступна по адресу http://oldturkicmorph.herokuapp.com/. В основе программы лежит сеть (см. рис. 3), вершинами которой являются грамматические показатели, которые содержат множество вариантов аффиксов с грамматическими пометами, также вершинами являются и показатели частей речи. Дуги показывают, какие грамматические показатели следуют друг за другом или предшествуют друг другу. Кроме того, программа использует словарь корней с пометами частей речи, а также набор правил для фильтрации возможных разборов вводимой словоформы. Алгоритм разбора словоформы начинается с поиска в вершинах сети возможного аффикса на конце слова, то есть слово разбирается с конца. После обнаружения вершины, которая содержит возможный аффикс, начинается поиск следующего аффикса в вершинах, к которым ведут дуги предыдущей вершины. Поиск происходит до тех пор, пока не обнаруживается корень из словаря или пока обнаруживаются возможные аффиксы. Если корень из словаря не найден ни в одном из возможных разборов, то программа предсказывает части речи по последнему обнаруженному в цепочке аффиксу. Далее программа фильтрует возможные разборы и строит удобочитаемый вывод. Парсер был использован для статистического исследования лексики М.-А. Чукури. Результаты исследования отражены в работе [5]. В заключении отметим, что сетевая модель агглютинативной морфологии находит свое применения как для разработки инструментов автоматического морфологического анализа, так и для квантитативных исследований. Дальнейшие исследования преимуществ сетевого подхода могут помочь в разработке универсальных инструментов NLP для всех тюркских языков.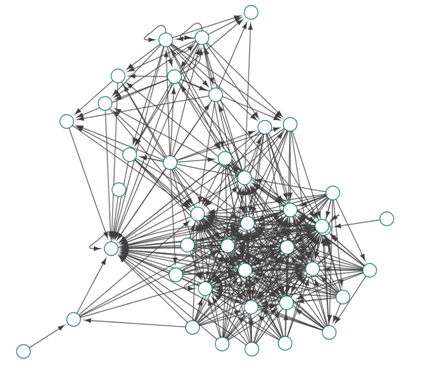
Рис. 3 – Сетевая модель морфологии старотюркского языка
Список литературы / References
- Грамматика современного башкирского литературного языка / Под ред. А. А. Юлдашева. — М.: Наука, 1981. — 495 с.
- Кирьянов Д. П., Орехов Б. В. СЕТЕВОЙ ПОДХОД К ОПИСАНИЮ БАШКИРСКОЙ МОРФОЛОГИИ / Кирьянов Д. П., Орехов Б. В. // Вестник Приамурского государственного университета им. Шолом-Алейхема, 2015. — № 3(20) — С. 23 – 40.
- Оре О. Теория графов / О. Оре — М.: Наука, 1968. — 336 с.
- Программа автоматического анализа башкирской морфологии: тәбрикләнем [Электронный ресурс] / Б. Орехов —URL: http://nevmenandr.net/cgi-bin/bashmorphweb.py (дата обращения: 24.12.2017)
- Саитбатталов И. Р. Лексика м.-а. Чукури в статистическом освещении / И. Р. Саитбатталов, В. А. Гречачин // Международный научно-исследовательский журнал. — 2016. — № 12 (54) Часть 2. — С. 76—78. — URL: https://research-journal.org/languages/leksika-m-a-chukuri-v-statisticheskom-osveshhenii/ (дата обращения: 24.12.2017)
- Сиразитдинов З. А. Моделирование грамматики башкирского языка. Словоизменительная система / З. А Сиразитдинов — Уфа: АН РБ, Гилем, 2006. — 160 с.
- Словарь лингвистических терминов: Изд. 5-е, испр-е и дополн. / Т.В. Жеребило — Назрань: Пилигрим, 2010. — 486 с.
- Щербак А. Грамматический очерк языка тюркских текстов X-XIII вв. из восточного Туркестана / А. Щербак — Ленинград: АН СССР, 1961. —204 с.
- Языкознание: От Аристотеля до компьютерной лингвистики / Владимир Алпатов — М.: Альпина нон-фикшн, 2018. — 253 с.
- L. Zhukov Complex Networks [Электронный ресурс] / Л. Жуков — URL: http://www.leonidzhukov.net/hse/2013/lingnetworks/lectures/lecturepdf (дата обращения: 24.12.2017)
- Oldturkicmorph [Электронный ресурс]: морфологический анализатор старотюркского языка / В. Гречачин —URL: http://oldturkicmorph.herokuapp.com/ (дата обращения: 24.12.2017)
Список литературы на английском языке / References in English
- Grammatika sovremennogo bashkirskogo literaturnogo yazyika [Modern literary Bashkir language] / Edited by A. A. Yuldashev. — M.: Nauka, 1981. — 495 p. [in Russian]
- Kiryanov D. P., Orehov B. V. Setevoy podhod k opisaniyu bashkirskoy morfologii [network based approach to the bashkir morphology description] / Kiryanov D. P., Orehov B. V. // Vestnik Priamurskogo gosudarstvennogo universiteta im. Sholom-Alejhema [Bulletin of the Amur state university of Sholom-Aleyhem] — 2015. — # 3(20) — P. 23 – 40. [in Russian]
- Ore O. Teoriya grafov [Graph theory] / O. Ore — M.: Nauka, 1968. — 336 p. [in Russian]
- Programma avtomaticheskogo analiza bashkirskoj morfologii: тәбрикләнем [Program of automatic analysis of Bashkir morphology: тәбрикләнем]: [Electronic resource] / B. Orekhov —URL: http://nevmenandr.net/cgi-bin/bashmorphweb.py?t=%D1%82%D3%99%D0%B1%D1%80%D0%B8%D0%BA%D0%BB%D3%99%D0%BD%D0%B5%D0%BC&mod=disp (accessed 24.12.2017) [in Russian]
- Saitbattalov I. R. Leksika m.-a. Chukuri v statisticheskom osveshchenii [the vocabulary of m.-a. Chuquri in statistical coverage] / I. R. Saitbattalov, V. A. Grechachin // Mezhdunarodnyj nauchno-issledovatelskij zhurnal [International research journal] — 2016. — № 12 (54) Part 2. — P. 76—78. —URL: https://research-journal.org/languages/leksika-m-a-chukuri-v-statisticheskom-osveshhenii/doi: 10.18454/IRJ.2016.54.016 (accessed 24.12.2017) [in Russian]
- Sirazitdinov Z. A. Modelirovanie grammatiki bashkirskogo yazyika. Slovoizmenitelnaya Sistema [Modeling of Bashkir grammar. Inflectional system] / Z. A Sirazitdinov — Ufa: AN RB, Gilem, 2006. — 160 p. [in Russian]
- Slovar lingvisticheskih terminov: Izd. 5-e, ispr-e i dopoln. [Dictionary of linguistic terms. 5th edition, revised and updated] / T.V. Zherebilo — Nazran: Piligrim, 2010. — 486 p. [in Russian]
- Scherbak A. Grammaticheskij ocherk yazyka tyurkskih tekstov X-XIII vv. iz vostochnogo Turkestana [Grammatical essay of language of turkic texts of X-XIII century from eastern Turkestan] / Scherbak — Leningrad: AN SSSR, 1961. —204 p. [in Russian]
- Yazyikoznanie: Ot Aristotelya do kompyuternoy lingvistiki [Linguistics: From Aristotle to computational linguistics] / Vladimir Alpatov —M.: Alpina non-fikshn, 2018. — 253 p. [in Russian]
- Zhukov Complex Networks [Electronic resource] / L. Zhukov — URL: http://www.leonidzhukov.net/hse/2013/lingnetworks/lectures/lecture1.pdf (accessed: 24.12.2017)
- Oldturkicmorph [Electronical resource]: oldturkic morphological analyzer / V. Grechachin — URL: http://oldturkicmorph.herokuapp.com/ (accessed: 24.12.2017) [in Russian]