ИДЕНТИФИКАЦИЯ И ВЕРИФИКАЦИЯ МНОГОФАКТОРНЫХ ПРЕДИКТОРОВ СЛОЖНОСТИ ТЕКСТА В АСПЕКТЕ ПРЕПОДАВАНИЯ РУССКОГО ЯЗЫКА КАК ИНОСТРАННОГО
ИДЕНТИФИКАЦИЯ И ВЕРИФИКАЦИЯ МНОГОФАКТОРНЫХ ПРЕДИКТОРОВ СЛОЖНОСТИ ТЕКСТА В АСПЕКТЕ ПРЕПОДАВАНИЯ РУССКОГО ЯЗЫКА КАК ИНОСТРАННОГО
Аннотация
В статье представлено корпусное исследование, направленное на выявление и верификацию объективных лексико-синтаксических предикторов сложности учебных текстов для изучающих русский язык как иностранный (РКИ). На материале текстов, стратифицированных по уровням CEFR (A1–C2), с помощью статистической среды R был проведён анализ четырёх ключевых параметров: лексического разнообразия (характеристика K Юла), синтаксической сложности (средняя длина предложения и средняя дистанция синтаксической зависимости) и стилистических особенностей (соотношение существительных и глаголов). Результаты статистического анализа (критерий Краскела-Уоллиса и корреляция Спирмена) показали, что синтаксические предикторы и лексическое разнообразие являются высокозначимыми индикаторами, демонстрирующими сильную корреляцию с уровнем владения языком. Соотношение существительных и глаголов также выявило значимую тенденцию к номинализации в текстах более высоких уровней. Исследование предлагает многомерную модель для объективной оценки текстовой сложности и закладывает эмпирическую основу для будущих психолингвистических экспериментов.
1. Введение
Оценка сложности текста является одной из фундаментальных задач в области преподавания русского языка как иностранного (РКИ). Адекватный подбор учебных материалов, соответствующий текущему уровню владения языком обучающегося, напрямую влияет на эффективность усвоения знаний и является залогом успешной языковой подготовки . Однако традиционные методы оценки, часто опирающиеся на интуицию преподавателя или ограниченный набор лексико-грамматических тем, не всегда обеспечивают необходимую объективность и последовательность . В связи с этим возникает острая необходимость в разработке и применении объективных, количественных методов анализа, способных предоставить эмпирически обоснованные критерии для классификации текстов по уровням сложности.
Современная вычислительная лингвистика предлагает широкий инструментарий для количественного анализа текста, однако многие существующие метрики, такие как простая частотность слов или классические индексы удобочитаемости, оказываются недостаточными для языков с богатой морфологией и свободным порядком слов, каким является русский. Сложность текста — это многомерное явление, которое не может быть сведено к одному или двум параметрам . Она охватывает лексическое разнообразие, синтаксическую структуру, стилистические особенности и когнитивную нагрузку, возникающую при обработке текста читателем. Следовательно, для получения достоверной картины необходимо перейти от одномерных подходов к многофакторному анализу, направленному на выявление целого комплекса взаимосвязанных лингвистических характеристик .
Цель настоящей статьи — идентификация и верификация набора объективных корпусных предикторов, которые надёжно отражают лексико-синтаксическую сложность текстов, предназначенных для изучающих русский язык. На материале учебных текстов, предварительно размеченных по уровням Общеевропейских компетенций владения иностранным языком (CEFR), с помощью статистической среды R и инструментов компьютерной лингвистики (quanteda, udpipe) проводится анализ четырёх ключевых групп параметров: лексического разнообразия (характеристика K Юла), длины синтаксических единиц (средняя длина предложения), сложности внутренней структуры предложения (средняя дистанция синтаксической зависимости) и стилистических особенностей (соотношение существительных и глаголов). Полученные результаты призваны не только способствовать созданию более качественно градуированных учебных материалов, но и заложить эмпирическую основу для последующих экспериментальных исследований в области психолингвистики восприятия текста.
2. Методы и принципы исследования
2.1. Материалы
Эмпирической базой для настоящего исследования послужил корпус учебных текстов, собранных из различных пособий по русскому языку как иностранному. Ключевым преимуществом данного корпуса является то, что все тексты в нём предварительно классифицированы по уровням владения языком в соответствии с Общеевропейскими компетенциями (CEFR), охватывая диапазон от A1 до C2. Для анализа были отобраны преимущественно тексты, предназначенные для чтения (текст для чтения), так как именно они наиболее полно отражают комплексную лексико-синтаксическую структуру, с которой сталкивается обучающийся при работе с аутентичными или адаптированными материалами. Тексты упражнений, имеющие специфическую дидактическую направленность, были исключены из основного анализа для обеспечения гомогенности выборки.
2.2. Методы анализа
Анализ данных проводился в среде статистического программирования R, которая предоставляет широкие возможности для обработки и анализа текстовых данных. Для решения поставленных задач были использованы два ключевых пакета компьютерной лингвистики. Пакет quanteda применялся для быстрой и эффективной токенизации текстов и расчёта метрик лексического разнообразия. Для более глубокого морфологического и синтаксического анализа, включая частеречную разметку и построение деревьев зависимостей, был использован пакет udpipe с предварительно обученной моделью для русского языка russian-syntagrus.
2.3. Анализируемые параметры
На основе теоретических предпосылок о многомерности языковой сложности для анализа были выбраны четыре предиктора, отражающие различные аспекты текста :
Характеристика K Юла: метрика лексического разнообразия, измеряющая степень повторяемости слов. В отличие от базового показателя TTR, данный индекс практически нечувствителен к длине текста, что делает его надёжным инструментом для сравнения выборок разного объёма .
Средняя длина предложения: классический параметр, отражающий сложность на макросинтаксическом уровне. Увеличение длины предложения, как правило, коррелирует с усложнением его структуры и повышением когнитивной нагрузки на читателя.
Средняя дистанция синтаксической зависимости: продвинутый параметр, оценивающий сложность на микросинтаксическом уровне. Он измеряет среднее расстояние (в словах) между синтаксически связанными элементами предложения. Большая дистанция требует от читателя удерживать в рабочей памяти больше информации, что напрямую связано с воспринимаемой трудностью текста.
Соотношение существительных и глаголов: стилистический параметр, указывающий на степень номинализации текста. Преобладание существительных над глаголами характерно для более абстрактного, формального и информационно плотного стиля, свойственного текстам высоких уровней сложности.
2.4. Статистическая обработка
Для верификации выбранных предикторов использовались два непараметрических статистических теста. Критерий Краскела-Уоллиса применялся для определения наличия статистически значимых различий в значениях каждого параметра между всеми уровнями CEFR. Для оценки силы и направления тенденции (т.е. последовательного роста или снижения параметра с повышением уровня) рассчитывался коэффициент ранговой корреляции Спирмена (ρ). Уровень статистической значимости был принят за p < 0,05.
3. Основные результаты
Статистический анализ данных, проведённый на материале учебного корпуса, подтвердил гипотезу о многомерности текстовой сложности и позволил верифицировать выбранные параметры в качестве надёжных предикторов уровня владения языком. Всестороннее рассмотрение каждого предиктора выявило их различный вклад и специфику, что даёт комплексное представление о том, как меняется структура текста по мере повышения его сложности. Ниже представлены результаты анализа по каждому из четырёх параметров.
3.1. Лексическое разнообразие (Характеристика K Юла)
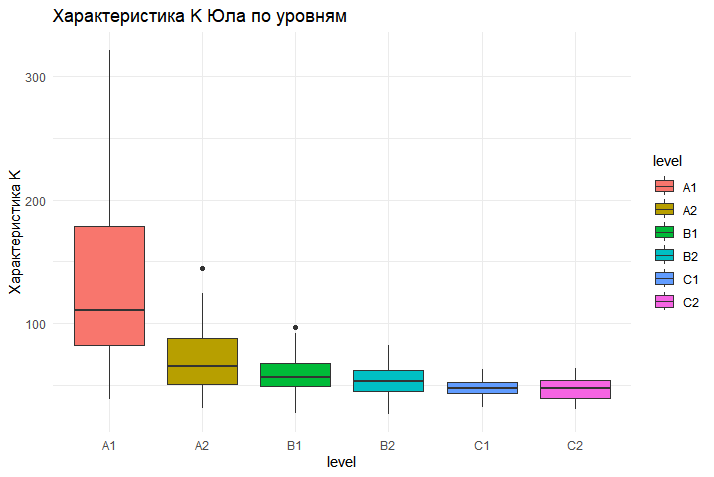
Рисунок 1 - Распределение Характеристики K Юла по уровням владения языком
Два параметра, оценивающие синтаксическую сложность с разных сторон, показали себя как наиболее сильные предикторы . Средняя длина предложения продемонстрировала положительную корреляцию с уровнем текста (ρ = 0,70, p < 0,001), что подтверждает гипотезу о том, что тексты более высоких уровней систематически используют более длинные и сложносочинённые/сложноподчинённые предложения (χ²(5) = 120,27, p < 0,001).
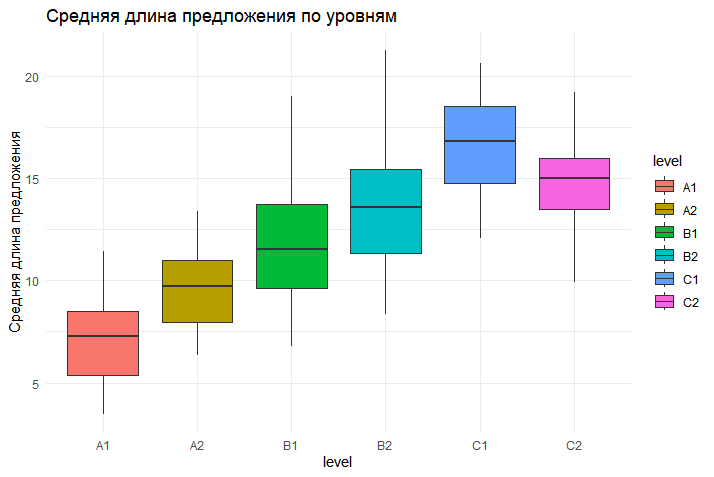
Рисунок 2 - Распределение средней длины предложения по уровням владения языком
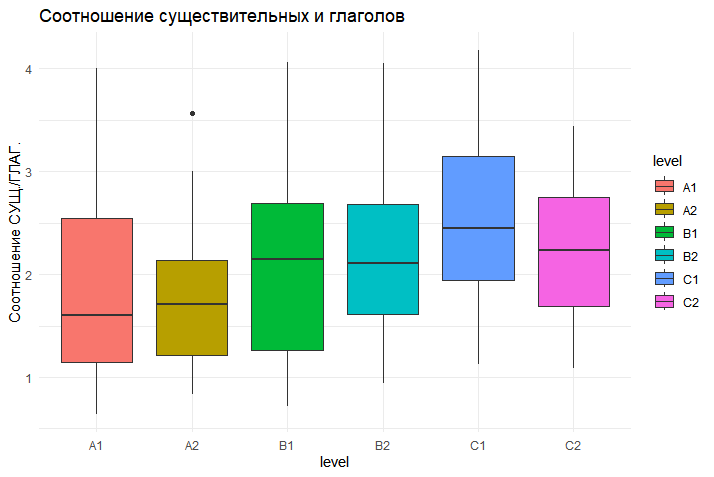
Рисунок 3 - Распределение соотношения существительных и глаголов по уровням владения языком
Анализ соотношения существительных и глаголов выявил более тонкую, но статистически значимую закономерность. Тест Краскела-Уоллиса показал, что общие различия между группами не достигают порога статистической значимости (χ²(5) = 9,94, p = 0,077). Однако корреляционный анализ по Спирмену обнаружил слабую, но статистически высокозначимую положительную тенденцию (ρ = 0,17, p < 0,01). Это говорит о том, что, несмотря на незначительные колебания, по мере роста уровня сложности наблюдается системный сдвиг в сторону номинализации — увеличения доли существительных по отношению к глаголам. Данный сдвиг отражает переход к более абстрактному, формальному и информационно насыщенному стилю изложения в текстах высоких уровней.
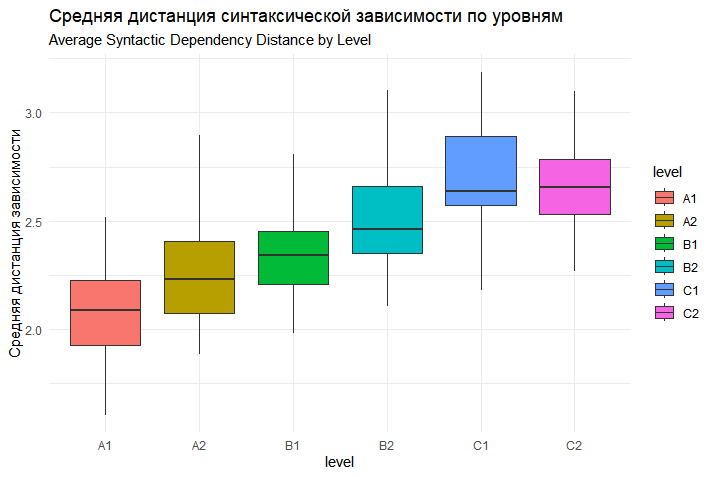
Рисунок 4 - Распределение средней дистанции синтаксической зависимости по уровням владения языком
Таблица 1 - Сводные результаты статистического анализа предикторов
Предиктор (Predictor) | Критерий Краскела-Уоллиса (Kruskal-Wallis) | Корреляция Спирмена (Spearman's Corr.) | ||
Характеристика K Юла | χ²(5) = 80,19 | p < 0,001 | ρ = -0,55 | p < 0,001 |
Средняя длина предложения | χ²(5) = 120,27 | p < 0,001 | ρ = 0,70 | p < 0,001 |
Средняя дистанция синтаксической зависимости | χ²(5) = 95,92 | p < 0,001 | ρ = 0,63 | p < 0,001 |
Соотношение существительных и глаголов | χ²(5) = 9,94 | p = 0,077 | ρ = 0,17 | p < 0,01 |
4. Обсуждение
Проведённое исследование позволило выявить и верифицировать четыре объективных параметра, которые в совокупности дают многомерное представление о лексико-синтаксической сложности учебных текстов по РКИ. Полученные результаты не только подтверждают существующие теоретические представления, но и вносят важные уточнения, имеющие как теоретическое, так и практическое значение .
Ключевым выводом является то, что сложность текста для иностранного учащегося определяется не одним, а целым комплексом факторов, среди которых доминирующую роль играют предикторы синтаксического уровня. Средняя длина предложения и, что особенно важно, средняя дистанция синтаксической зависимости показали себя как наиболее сильные и надёжные индикаторы . Это подчёркивает, что по мере повышения уровня владения языком основной вызов для учащегося заключается не столько в освоении новой лексики, сколько в способности обрабатывать всё более сложные синтаксические конструкции. Увеличение дистанции зависимости напрямую свидетельствует о росте когнитивной нагрузки, так как требует от читателя удерживать в рабочей памяти больше грамматических связей для успешного декодирования смысла предложения .
Наряду с синтаксисом, лексическое разнообразие, измеренное с помощью характеристики K Юла, также является фундаментальным параметром сложности. Сильная отрицательная корреляция данного показателя с уровнем текста доказывает, что переход на новый уровень владения языком неразрывно связан с расширением словарного запаса и уменьшением доли повторяющихся лексем. Наконец, соотношение существительных и глаголов, хоть и показало более слабую тенденцию, вскрыло важный стилистический аспект сложности. Системный сдвиг в сторону номинализации в текстах высоких уровней отражает переход от нарративного, ориентированного на действия стиля к более абстрактному, дескриптивному и информационно плотному изложению, характерному для академической и научной речи.
5. Заключение
В заключение, данное исследование успешно идентифицировало и верифицировало набор из четырёх корпусных предикторов, эффективно отражающих многоаспектную природу сложности текста в РКИ. Установлено, что сложность определяется как лексическими (разнообразие), так и синтаксическими (длина и внутренняя структура предложений) и стилистическими (степень номинализации) факторами. Практическая значимость работы заключается в том, что предложенные метрики могут быть использованы авторами учебников и преподавателями для объективной оценки и градуировки учебных материалов. Теоретический вклад состоит в количественном подтверждении и детализации структуры текстовой сложности. Результаты данного корпусного анализа закладывают прочную эмпирическую основу для следующего этапа исследований — проведения психолингвистических экспериментов, направленных на изучение того, как эти объективные текстовые параметры влияют на процессы восприятия и когнитивную нагрузку у реальных читателей, изучающих русский язык.