Применение машинного обучения для прогнозирования у сотрудников университета степени готовности к участию в программах по здоровому образу жизни
Применение машинного обучения для прогнозирования у сотрудников университета степени готовности к участию в программах по здоровому образу жизни
Аннотация
Целью исследования является разработка модели машинного обучения, способной прогнозировать готовность сотрудников университетов лично участвовать в программах и мероприятиях, направленных на укрепление здоровья. Опрос проведён с использованием платформы Яндекс.Формы, в нём приняли участие 394 научно-педагогических и административных сотрудника вузов Дальнего Востока. Для обработки и анализа данных использовалась программа Orange. Протестировано несколько моделей машинного обучения, включая метод ближайших соседей, логистическую регрессию, дерево принятия решений, случайный лес, наивный Байес, градиентный бустинг и адаптивный бустинг. Модели оценивались по различным метрикам с акцентом на F1-меру для достижения баланса между точностью и полнотой при работе с несбалансированными классами. Метод «Адаптивный бустинг» показал наивысшее значение F1-меры (0,807) и продемонстрировал высокую точность в прогнозировании класса «Нет» (71,1%) и класса «Да» (85,7%), что делает его наиболее подходящей для поставленной задачи. Модель адаптивного бустинга рекомендована для прогнозирования готовности сотрудников участвовать в мероприятиях, направленных на укрепление здоровья. Полученные результаты могут быть использованы для разработки программ и мероприятий, направленных на продвижение здорового образа жизни среди сотрудников университетов, что повысит эффективность таких инициатив в образовательных организациях.
1. Введение
1.1. Актуальность
Применение методов машинного обучения (МО) позволяет автоматизировать анализ больших объемов данных, полученных из опросов, и выявлять скрытые закономерности, например, в предпочтениях и мотивациях сотрудников вузов. Использование МО способствует более точной сегментации участников и адаптации программ по здоровому образу жизни (ЗОЖ) под их реальные потребности.
Актуальность темы обусловлена растущей необходимостью внедрения программ по здоровому образу жизни в образовательных учреждениях, что связано с улучшением качества жизни сотрудников и повышением их профессиональной эффективности. Однако успешная реализация таких программ во многом зависит от степени готовности сотрудников к участию в них, что требует точного анализа их мотивации, предпочтений и барьеров. Традиционные методы обработки данных опросов не всегда позволяют выявить скрытые закономерности, особенно при работе с большими объемами информации. Применение МО в данной области предоставляет возможность автоматизировать анализ данных, улучшить прогнозирование и создать персонализированные подходы к вовлечению сотрудников. Таким образом, использование современных технологий для решения данной задачи не только повышает эффективность программ ЗОЖ, но и способствует развитию цифровых инструментов в управлении образовательной средой.
1.2. Обзор исследований
Дж. Гриммер, М. Э. Робертс и Б. М. Стюарт рассматривают использование машинного обучения в социальных науках. Исследователи подчеркивают, что интеграция методов машинного обучения требует переосмысления как их применения, так и традиционных исследовательских практик, поскольку эти методы позволяют выявлять новые концепты, измерять их распространённость, оценивать причинно-следственные связи и делать прогнозы. Они предлагают агностический подход, ориентированный на задачи социальных наук, который способствует переходу от дедуктивного к более последовательному, интерактивному и индуктивному подходу, расширяя возможности для решения сложных исследовательских вопросов .
Исследование Н. Н. Леонова посвящено разработке методики применения машинного обучения для анализа социологических данных. В работе рассматриваются возможности использования машинного обучения для обработки и анализа информации, собранной в рамках социологических исследований. Автор акцентирует внимание на важности дальнейшего развития данной методологии и подробно описывает применение ряда классических методов машинного обучения в этом контексте .
М. Д. Молина и Ф. Гарип представили применение методов машинного обучения в социологии. Ученые подчеркивают, что машинное обучение, как область на стыке статистики и компьютерных наук, позволяет извлекать информацию и знания, что может помочь в решении традиционных вопросов в социологии .
В статье Х. Лейтгёб, Д. Пранднер и Т. Вольбринг показано влияние цифровой революции и технологий больших данных на социальные науки, с акцентом на использование машинного обучения. Рассматриваются ключевые аспекты цифровизации, такие как датафикация общества, развитие вычислительных мощностей и алгоритмов, а также их влияние на методы исследования и анализ социальных явлений. Авторы подчеркивают необходимость адаптации социальных наук к новым условиям, включая развитие теоретических основ, методологических подходов и образовательных программ для успешной интеграции технологий больших данных и машинного обучения .
Анализ данных медико-социологического мониторинга на основе методов машинного обучения показали Г. Г. Рапаков и др. Исследователи представили, как машинное обучение может помочь в интерпретации и использовании социологических и медицинских данных для принятия решений .
М. Б. Богданова и И. Б. Смирнова рассматривают возможности и ограничения использования цифровых следов и методов машинного обучения в социологии. Авторы выделяют новые источники данных и подчеркивают, как потенциал для более глубокого анализа социальных явлений, так и ограничения, связанные с этими методами, включая вопросы этики, качества данных и интерпретации результатов .
Исследование Р. Х. Хайбергера применяет машинное обучение в социологии для предсказания пола исследователей и выявления их предпочтений в исследованиях. В частности, он использует предсказанный пол в тематическом моделировании, чтобы подчеркнуть значительные тематические различия между работами мужских и женских ученых, которые зачастую были упущены из виду .
К. Б. Мухамадиева показал применение машинного обучения для обеспечения обратной связи с преподавателем после обработки данных в режиме реального времени для повышения эффективности преподавания и обучения. Основное внимание в работе уделяется тому, как современные технологии способствуют улучшению качества образовательного процесса .
Разработали технику в социологии для систем анализа настроений, основанную на методе машинного обучения (глубокие нейронные сети с использованием методов выбора признаков на основе хи-квадрат), М. Хуссейн и Ф. Озюрт. Эта комбинация показала улучшение точности классификации на стандартных наборах данных .
Р. Р. Халде рассмотрел различные способы применения алгоритмов машинного обучения в образовательных учреждениях. Автор показал, как машинное обучение может способствовать улучшению образовательной системы, в том числе через предсказание успеха студентов и оптимизацию учебных процессов .
1.3. Постановка задачи
Для проведения эксперимента по определению ценностно-мотивационных приоритетов научно-педагогических работников и сотрудников в разрезе здорового образа жизни (на примере вузов Дальнего Востока) составлен опрос .
Вопросы концентрируются возле нескольких тем:
- инфраструктура для занятий физической культурой и спортом в университете (спортивные залы, бассейны, тренажерные залы и т.д.);
- роль администрации университетов в продвижении здорового образа жизни среди научно-педагогических работников и сотрудников;
- вовлеченность научно-педагогических работников и сотрудников в программы по здоровому образу жизни, их мотивация и барьеры к участию;
- мотивация научно-педагогических работников и сотрудников к ведению здорового образа жизни;
- интеграция вопросов здорового образа жизни в образовательные программы университетов;
- системный подход к организации оздоровительных мероприятий, индивидуальных программ для научно-педагогических работников и сотрудников;
- предложения по формированию здорового образа жизни в условиях образовательной организации;
- информация о респонденте.
Важной составляющей в дальнейшем проектировании и реализации программ университетов, направленных на ЗОЖ, является готовность сотрудников к личному участию в таких мероприятиях. Поэтому для построения модели машинного обучения выбран вопрос «Готовы ли Вы лично участвовать в программах и мероприятиях, направленных на укрепление здоровья?».
1.4. Цель исследования
Цель исследования – разработать модель машинного обучения, способную прогнозировать степень готовности сотрудников к личному участию в программах и мероприятиях университета по ЗОЖ.
2. Материалы и методы
В теории социологических опросов используются термины: доверительная вероятность, доверительная погрешность. Доверительная вероятность – это показатель точности измерений. Доверительная погрешность – это возможная ошибка результатов исследования.
Например, при генеральной совокупности более 250000 тыс. человек выборка будет равняться 384 человека при доверительной вероятности 95% и погрешности 5% или при доверительном интервале 95±5% . Соответственно, получим репрезентативную выборку с минимальной вероятностью статистической ошибки.
Оценим генеральную совокупность научно-педагогических работников и сотрудников. По данным в Информационно-аналитических материалах по результатам проведения мониторинга деятельности образовательных организаций высшего образования за 2023 год в Дальневосточном федеральном округе 171 477 студентов бакалавриата, специалитета, магистратуры . Нормативное соотношение между студентами и преподавателями 1:12. Соответственно примерно 14 000 (округление до тысяч).
Таким образом, генеральная совокупность научно-педагогических работников и сотрудников в Дальневосточном федеральном округе составляет порядка 14 тыс. человек. Получаем минимальную оценку репрезентативной выборки в 374 человек при доверительном интервале 95±5%. В анкетировании приняло участие 394 научно-педагогических работников и сотрудников вузов Дальнего Востока, что достаточно для дальнейшей работы.
Опрос проведен на платформе Яндекс.Формы .
Для построения модели машинного обучения выбрана компьютерная система Orange . В связи с тем, что Orange не поддерживает вывод p-уровня значимости (p-value), то корреляционный анализ проводился отдельно с помощью написанной программы на python, в которой использовались библиотеки pandas и SciPy для расчета коэффициента Спирмена и p-уровня значимости.
3. Результаты и обсуждение
Для построения модели осуществлена предварительная обработка данных и конструирование признаков (Feature Engineering).
Начальное распределение ответов на вопрос «18. Готовы ли Вы лично участвовать в программах и мероприятиях, направленных на укрепление здоровья?» представлено в табл.1.
Таблица 1 - Распределение ответов в вопросе «18. Готовы ли Вы лично участвовать в программах и мероприятиях, направленных на укрепление здоровья?»
Варианты ответов | Доля ответов (%) |
Да | 65,65 |
Затрудняюсь ответить | 21,09 |
Нет | 13,26 |
Для более полного представления сконструирована новая целевая переменная «18.1 Готовы ли Вы лично участвовать в программах и мероприятиях, направленных на укрепление здоровья?», только в ней объединяются ответы «Нет» и «Затрудняюсь ответить» в «Нет». Такое объединение возможно, так как можно предположить, что при неопределённости будет в большинстве случаев «Нет».
Распределение по переменной «18.1 Готовы ли Вы лично участвовать в программах и мероприятиях, направленных на укрепление здоровья?» представлено в табл. 2.
Таблица 2 - Распределение ответов в новой переменной «18.1 Готовы ли Вы лично участвовать в программах и мероприятиях, направленных на укрепление здоровья?»
Варианты ответов | Доля ответов (%) |
Да | 65,65 |
Нет | 34,35 |
Таким образом, в новой целевой переменной улучшилась балансировка классов.
Для корреляционного анализа выбран расчёт коэффициента Спирмена, так как переменные категориальные. Из-за того что среда Orange не показывает p-уровня значимости (p-value), анализ для предварительно закодированных переменных проведен с помощью отдельно написанной программы на Python в среде Google Colab.
При корреляционном анализе обнаружены достаточные сильные связи (значимые по p-value) между переменными (табл. 3).
Таблица 3 - Результаты корреляционного анализа (значимый по p-value коэффициент корреляции Спирмена больше по модулю 0,4)
Переменная 2 | Переменная 2 | Коэффициент корреляции Спирмена |
1. Создана ли в Вашем университете инфраструктура для занятий физической культурой и спортом (спортивные залы, бассейны, тренажерные залы и т.д.). | 2. Доступна ли для научно-педагогических работников и сотрудников университета созданная в Вашем университете инфраструктура для занятий физической культурой и спортом (спортивные залы, бассейны, тренажерные залы и т.д.). | 0,64 |
2. Доступна ли для научно-педагогических работников и сотрудников университета созданная в Вашем университете инфраструктура для занятий физической культурой и спортом (спортивные залы, бассейны, тренажерные залы и т.д.). | 3. Считаете ли вы, что в Вашем университете созданы условия для ведения здорового образа жизни (спортивные секции, медицинские кабинеты, пропаганда ЗОЖ и т.д.)? | 0,61 |
3. Считаете ли вы, что в Вашем университете созданы условия для ведения здорового образа жизни (спортивные секции, медицинские кабинеты, пропаганда ЗОЖ и т.д.)? | 4. Какие меры по поддержанию здорового образа жизни преподавателей и сотрудников предпринимает Ваш университет? / К) не предпринимает | 0,53 |
1. Создана ли в Вашем университете инфраструктура для занятий физической культурой и спортом (спортивные залы, бассейны, тренажерные залы и т.д.). | 3. Считаете ли вы, что в Вашем университете созданы условия для ведения здорового образа жизни (спортивные секции, медицинские кабинеты, пропаганда ЗОЖ и т.д.)? | 0,48 |
1. Создана ли в Вашем университете инфраструктура для занятий физической культурой и спортом (спортивные залы, бассейны, тренажерные залы и т.д.). | 4. Какие меры по поддержанию здорового образа жизни преподавателей и сотрудников предпринимает Ваш университет? / К) не предпринимает | 0,43 |
4. Какие меры по поддержанию здорового образа жизни преподавателей и сотрудников предпринимает Ваш университет? / З) Еженедельные занятия фитнесом | 4. Какие меры по поддержанию здорового образа жизни преподавателей и сотрудников предпринимает Ваш университет? / Д) Групповые занятия физической активности | 0,40 |
Для предотвращения влияния мультиколлинеарности из входных переменных исключены вопросы: «2. Доступна ли для научно-педагогических работников и сотрудников университета созданная в Вашем университете инфраструктура для занятий физической культурой и спортом (спортивные залы, бассейны, тренажерные залы и т.д.)» и «4. Какие меры по поддержанию здорового образа жизни преподавателей и сотрудников предпринимает Ваш университет?». Также были исключены личностные переменные: «Курите ли Вы?», «Употребляете ли Вы алкогольные напитки?», «Ваш пол», «Ваша должность».
Из-за ограниченного объема данных (394 строки) для построения моделей машинного обучения в Orange была применена кросс-валидация на 10 фолдов со стратификацией. Этот метод перекрестной проверки делит набор данных на 10 случайных частей, при этом сохраняя пропорции классов. Модель обучается 10 раз, каждый раз используя 9 частей данных для обучения, а оставшуюся одну часть – для проверки. Соответственно, каждый кусочек данных побывает в роли тестовой выборки ровно один раз.
Проведены эксперименты с несколькими моделями: Метод ближайших соседей (рис. 1); Логистическая регрессия (рис. 2); Дерево принятия решений (рис. 3); Случайный лес (рис. 4); Наивный Байес (рис.5); Градиентный бустинг (рис.6); Адаптивный бустинг (Адабуст) (рис.7).

Рисунок 1 - Параметры модели: Метод ближайших соседей
Рисунок 2 - Параметры модели: Логистическая регрессия
Рисунок 3 - Параметры модели: Дерево принятия решений
Рисунок 4 - Параметры модели: Случайный лес
Рисунок 6 - Параметры модели: Наивный Байес
Рисунок 6 - Параметры модели: Градиентный бустинг
Рисунок 7 - Параметры модели: Адаптивный бустинг

Рисунок 8 - Схема моделирования в Orange
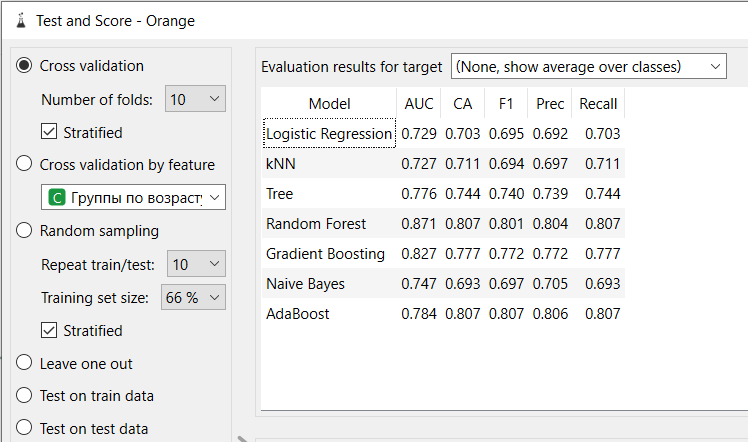
Рисунок 9 - Результаты моделирования
- AUC (Area under ROC) – Площадь под ROC-кривой;
- CA (Classification accuracy) – Доля правильно классифицированных примеров;
- F1 (F1-score) – Взвешенное гармоническое precision и recall;
- Prec (Precision) – Доля истинных положительных результатов среди случаев, классифицированных как положительные (точность);
- Recall (Recall) – Доля истинных положительных результатов среди всех положительных случаев в данных (полнота).
Для оценки качества моделей выбрана метрика F1. F1-мера является метрикой для оценки качества бинарной классификации, объединяющей точность (precision) и полноту (recall) в одно значение. Метрика полезна, когда требуется сбалансировать точность и полноту, особенно в случаях с несбалансированными классами.
По метрике F1 лучшей моделью можно признать модель «Адаптивный бустинг» со значением 0,807.
В процессе моделирования необходимо добиваться уменьшения ошибок второго рода, такие ошибки для целевой переменной получаются в классе (ответе) «Нет».
На рис. 10 представлена матрица ошибок для модели Адабуст.
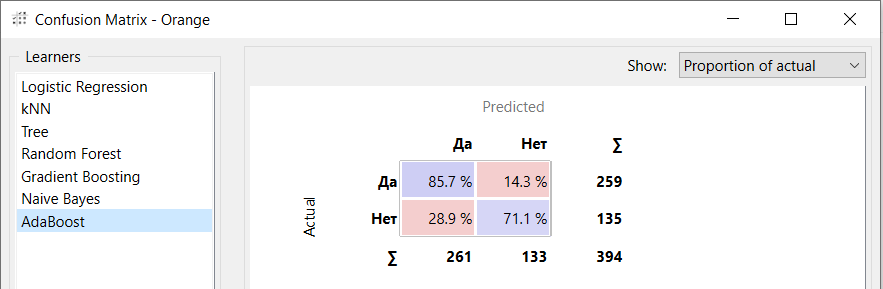
Рисунок 10 - Матрица ошибок модели Адабуст
Таким образом, лучшей моделью для прогнозирования качества у научно-педагогического работника, с кем требуется провести различные мероприятия по убеждению его в укреплении здоровья, является адаптивный бустинг.
4. Заключение
В ходе исследования была проведена предварительная обработка данных для построения модели машинного обучения, в том числе улучшение балансировки классов целевой переменной.
Выявлены значимые и достаточно высокие корреляции между переменными, что привело к исключению некоторых факторов (мультиколлинеарных) для минимизации их влияния на качество модели.
Для построения и оценки моделей использовались несколько алгоритмов машинного обучения: Метод ближайших соседей, Логистическая регрессия, Дерево решений, Случайный лес, Наивный Байес, Градиентный бустинг, Адаптивный бустинг. Результаты моделирования сравнивались по метрике F1, позволяющей сбалансировать точность и полноту.
Лучшая F1-мера (0,807) была достигнута моделью Адаптивного бустинга, показавшую достаточно высокую точность в прогнозировании класса «Нет» (71,1%) и класса «Да» (85,7%), что делает её наиболее подходящей для задачи.
Модель Адаптивного бустинга рекомендована для использования при прогнозировании готовности научно-педагогических работников участвовать в мероприятиях, направленных на укрепление здоровья, с целью дальнейшего формирования программ убеждения и поддержки здорового образа жизни.