ПОДГОТОВКА ВЫБОРКИ ИЗОБРАЖЕНИЙ ДЛЯ ЗАДАЧИ РАСПОЗНАВАНИЯ ТУРИСТИЧЕСКИ ПРИВЛЕКАТЕЛЬНЫХ ОБЪЕКТОВ
Сташевский П.С.1, Яковина И.Н.2
1,2Кандидат технических наук, Новосибирский государственный технический университет (НГТУ)
ПОДГОТОВКА ВЫБОРКИ ИЗОБРАЖЕНИЙ ДЛЯ ЗАДАЧИ РАСПОЗНАВАНИЯ ТУРИСТИЧЕСКИ ПРИВЛЕКАТЕЛЬНЫХ ОБЪЕКТОВ
Аннотация
В работе приводится описание процедуры сбора исходных данных в виде массива изображений для задачи распознавания туристически привлекательных объектов в городе. Описывается процедура сбора данных и ее реализация с использованием публично доступных API сервисов Flickr и Foursquare, файловой базы данных SQLite и языка разработки Python. Для собранных данных описывается процедура разметки на классы для задачи бинарной классификации изображений туристически привлекательных объектов и полученные описательные характеристики массива.
Ключевые слова: задача распознавания, сбор данных, обучающая выборка, туристически привлекательный объект.Stashesvky P.S.1, Yakovina I.N.2
1,2PhD in Engineering, Novosibirsk State Technical University (NSTU)
COLLECTION OF SAMPLE IMAGES FOR RECOGNITION OF TOURIST ATTRACTIVE PLACES
Abstract
The paper describes the procedure of collecting raw data in the form of an images array in the context of the recognition problem for attractive tourist places in the city. A procedure of data collection and its implementation with the use of publicly available services API Flickr and Foursquare, SQLite database and Python are desribed. For the collected data describes how markings on classes for binary image classification tasks tourist attractive sites and obtained the descriptive characteristics of the array.
Keywords: image recognition, data collection, training set, tourist attractive places.Введение
Интенсивное развитие социальных сетей и возрастающее количество их пользователей побуждают разработчиков и исследователей онлайн-сервисов решать новые задачи анализа разнородных гигантских массивов данных и использовать методы, получивших название social web mining (SWM – анализ данных социальных сетей) [1,2]. В данной статье рассматривается подход к решению одной из задач SWM, позволяющей на основе имеющихся данных социальных сетей получать нового вида информацию о туристически привлекательных объектах (ТПО).
Особенностью развития социальных сетей является быстрая скорость реакции на различные объекты и события, в частности на появление различных памятников, скверов и парков, фонтанов, новых зданий и других объектов городской инфраструктуры, часть из которых может быть потенциально привлекательна с туристической точки зрения [2,3]. В связи с этим социальная сеть как поставщик актуальной и развернутой информации может быть полезна при планировании туристического маршрута, написании обзорных статей, формировании списков обновлений для поисковых сервисов и т.д. Понятие туристически привлекательного объекта в рамках данной работы предполагает обязательное соблюдение следующих условий: во-первых, объект относится к одной из общепринятых категорий, используемых в туристических каталогах; во-вторых, объект представляет интерес с визуальной точки зрения и в-третьих, объект имеет привязку к конкретной географической точке. В рамках данной работы рассматриваются 12 классов ТПО: архитектурные сооружения и объекты природной среды (здания, фонтаны, памятники, парки, пруды, скверы и т.д.), для которых возможно составить пеший обзорный маршрут по городу.
Постановка задачи распознавания туристически привлекательных объектов
Для распознавания ТПО могут быть использованы различные группы данных, генерируемые пользователями социальных сетей, в частности, такие как: отзывы, фотографии, информация о геолокациях. Поскольку в рамках данной работы в качестве источника данных будут использоваться изображения с информацией о геолокации, то задачу распознавания ТПО можно представить в виде последовательного выполнения этапов: 1) подготовки данных, 2) бинарной классификации для отсеивания изображений, не относящихся к ТПО, 3) настраиваемой или гибкой классификации для уточнения класса изображения (здание, мост, парк и т.д.), 4) группировки отдельных изображений в ТПО и разметки, 5) оценки объектов с последующим ранжированием.
Для решения задач классификации изображений в работе исследуется применение глубоких архитектур нейронных сетей, в частности, сверточных нейронных сетей, показывающих на текущий момент одни из лучших результатов в задаче распознавания естественных сигналов [4]. Для разработки алгоритмов оценки и ранжирования ТПО в работе планируется использовать методы линейной классификации и модификацию метода опорных ветров Ranking SVM.
Процедура сбора исходных данных
В качестве сервисов-поставщиков исходных данных в работе используются данные сервиса для размещения фотографий Flickr (http://flickr.com) и социальной сети с функцией геопозиционирования Foursquare (http://foursquare.com/) , полученные с помощью публично открытых API.
Процедура работы с сервисами представлена на рис. 1 и предполагает выполнение следующих этапов: 1) получение изображений и дополнительной информации из API Flickr и Foursquare, 2) сохранение полученного изображения на жесткий диск, 3) добавление в базу данных новой записи об изображении с данными о геопозиции и другой дополнительной информацией (используется файловая БД SQLite).
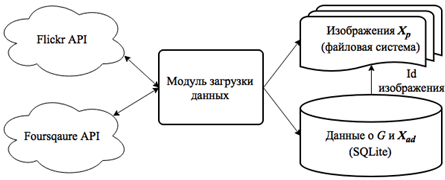
Рис. 1 - Работа с API сервисов
В качестве средства реализации модуля загрузки данных использовался язык разработки Python и библиотеки: flickr_api - взаимодействие с API Flickr, foursquare - взаимодействие с API Foursquare, sqlite3 - создание БД и запись в нее данных, urllib - скачивание изображений, json - разбор http-ответа API в формате json. Следует отметить, что публичные API имеют ряд ограничений на количество запросов (для Foursquare API - от 500 до 5000 запросов в час, для Flickr API - 3600 запросов в час), поэтому процедура скачивания изображений занимает продолжительное время.
Foursquare является социальной сетью, в которой пользователи помимо фотографий дополнительно генерируют достаточно большое количество данных о посещенных объектах с точками привязки к геолокациям, которые будут использованы в процессе оценки и ранжирования ТПО, в частности: categories - рубрики для каталогизации мест (https://developer.foursquare.com/categorytree); name - общеупотребительное название геолокации; contacts - контакты объекта (телефон, наличие сайта, групп в социальных сетях); stats - статистика посещения места (usersCount - количество побывавших на объекте пользователей, tipCount - количество текстовых подсказок, оставленных пользователями, checkinsCount - количество посещений).
Описание массива данных
С целью предварительного анализа особенностей решения поставленной задачи было собрано 4534 изображений (геолокация - г. Новосибирск): 1790 изображения с использования Flickr API, 2744 с использованием Foursquare API. Общий размер всех скаченных данных составил 1,31 Гб. Для собранных объектов была выполнена разметка классов Y={0,1}. Изображение классифицировалось как ТПО, если выполнялись следующие критерии:
- изображение четкое, без помех и размытий, не темное;
- на изображении отсутствуют лица людей;
- изображение относится к одной из туристических рубрик, описанных в постановке задач);
- объект представляет интерес для посещения при визуальном анализе (для спорных изображений использовалось голосование трех экспертов с подсчетом большинства голосов).
Характеристики размеченного массива данных и примеры изображений представлены на рис. 2.
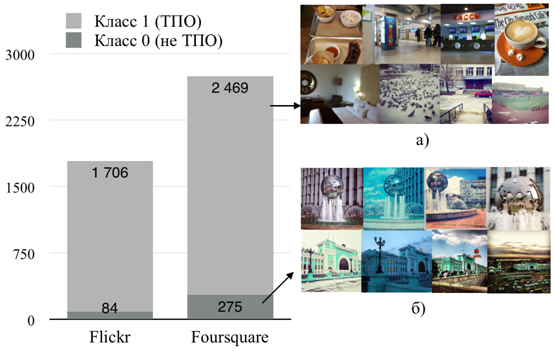
Рис. 2 - Характеристики массива данных изображений: а) не относятся к классу ТПО, б) относятся к классу тПО
Для сервиса Flickr релевантными классу ТПО получилось 84 изображения (4,7 % от исходного массива данных), тогда как для сервиса Foursquare этот показатель составляет 275 (10%), что логично объясняется целью сервиса Foursquare - фиксировать и делиться своей геопозицией с друзьями. Следовательно, данный сервис более привлекателен с точки зрения сбора релевантных данных. Анализ изображений, не относящихся к классу ТПО, показывает, что здесь преобладают фотографии следующих типов: 1) фотографии, на которых присутствуют лица людей, 2) фотографии еды и продуктов, 3) фотографии интерьера различных заведений, 4) нечеткие фотографии городской среды.
Собранные массивы данных в дальнейшем планируется использовать для обучения и тестирования алгоритмов классификации, оценки и ранжирования.
Заключение
В рамках данной работы был разработан программный модуль для сбора исходных данных с использованием публично доступных API сервисов Flickr и Foursquare. Разработанный модуль был использован для загрузки 4534 изображений и последующей разметки на классы. Полученные результаты по разметке показывают, что для более точного обучения бинарного классификатора в дальнейшем необходимо будет увеличить процент изображений, относящихся к классу ТПО, путем добавления уже размеченных изображений из открытых источников данных.
Список литературы / References
- Herrouz A., Khentout C., Djoudi M. Overview of Web Content Mining Tools // The International Journal of Engineering and Science (IJES), Volume 2, Issue 6, June 2013, ISSN: 2319 – 1813.
- Balan S., Ponmuthuramalingam P. A study of various techniques of Web Content Mining Research Issues and Tools // International Journal of Innovative Research and Studies (IJRIS), Volume 2, Issue 5, May 2013, ISSN: 2319-9725.
- Cortizo, J., Carrero, F., Gomez, J., Monsalve, B., Puertas, E.:Introduction to Mining SM // In: Proceedings of the 1 Workshop on Mining SM, 1 – 3, 2009.
- Lee H., Grosse R., Ranganath R., Ng A.Y. Convolutional Deep Belief Networks for Scalable Unsupervised Learning of Hierarchical Representations. Proceedings of the 26th Annual International Conference on Machine Learning. 2009.
- Сташевский П. С. Метод профилей для селекции признаков из временных рядов в задачах анализа данных / П. С. Сташевский, И. Н. Яковина // Автоматика и программная инженерия. - 2015. – № 4 (14). – С. 59–64.
Список литературы на английском языке / References in English
- Herrouz A., Khentout C., Djoudi M. Overview of Web Content Mining Tools // The International Journal of Engineering and Science (IJES), Volume 2, Issue 6, June 2013, ISSN: 2319 – 1813.
- Balan S., Ponmuthuramalingam P. A study of various techniques of Web Content Mining Research Issues and Tools // International Journal of Innovative Research and Studies (IJRIS), Volume 2, Issue 5, May 2013, ISSN: 2319-9725.
- Cortizo, J., Carrero, F., Gomez, J., Monsalve, B., Puertas, E.:Introduction to Mining SM // In: Proceedings of the 1 Workshop on Mining SM, 1 – 3, 2009.
- Lee H., Grosse R., Ranganath R., Ng A.Y. Convolutional Deep Belief Networks for Scalable Unsupervised Learning of Hierarchical Representations. Proceedings of the 26th Annual International Conference on Machine Learning. 2009.
- Stashevskiy P. S. Metod profilej dlja selekcii priznakov iz vremennyh rjadov v zadachah analiza dannyh [Method of feature engineering for time series in data analysis problems] / P. S. Stashevskiy, I. N. Yakovina // Avtomatika i programmnaja inzhenerija [Automatics & Software Enginery]. - 2015. – № 4 (14). – P. 59–64.