РАЗРАБОТКА МОДИФИЦИРОВАННОГО АЛГОРИТМА ПОИСКА КНИГ В ЭЛЕКТРОННОЙ БИБЛИОТЕКЕ
РАЗРАБОТКА МОДИФИЦИРОВАННОГО АЛГОРИТМА ПОИСКА КНИГ В ЭЛЕКТРОННОЙ БИБЛИОТЕКЕ
Аннотация
В данной работе показан процесс разработки алгоритма поиска книг в электронной библиотеке с целью улучшения параметров поиска. Научная новизна проведенного исследования заключается в том, что предложен модифицированный алгоритм поиска, отличающийся от алгоритма расширения выборки, на основе которого он создан, большей скоростью поиска при сохранении приемлемой надежности. Для подтверждения эффективности внесенных модификаций в среде Visual Studio был произведен эксперимент по сравнению времени и надежности поиска с использованием классического алгоритма расширения выборки и предлагаемого модифицированного алгоритма поиска. Приведены результаты проведенного эксперимента, подтверждающие эффективность предложенного модифицированного алгоритма поиска. Также при разработке электронной библиотеке была предложена онтологическая модель предметной области, отличающаяся от известных расширенным набором сущностей и классов предметной области, и набор оригинальных дискретно-событийных имитационных GPSS-моделей, важной особенностью которых является то, что они, в отличие от известных аналогичных моделей, имеют комплексный характер и позволяют учитывать как особенности работы аппаратного обеспечения электронной библиотеки, так и человеческий фактор, связанный с деятельностью ее сотрудников.
1. Введение
Для электронной библиотеки большое значение имеет эффективная организация процесса поиска требуемых книг. От данной организации в большой степени зависят как скорость поиска, так и релевантность его результатов. Кроме того, стоит отметить, что указанные характеристики могут вступать в противоречие друг с другом.
Наибольшую скорость поиска демонстрирует обычный текстовый поиск, проверяющий названия книг на соответствие требуемому поисковому запросу и отбирающий те из них, которые в полной мере ему удовлетворяют. Однако данный поиск удобен далеко не всегда, поскольку поисковый запрос может содержать в себе ошибки и неточности, вследствие чего нужные книги могут быть не найдены. Для решения этой проблемы, обычно используются алгоритмы нечеткого поиска, позволяющие находить не только результаты, которые полностью соответствуют требуемому запросу, но и результаты, относительно которых запрос может содержать одну или несколько ошибок, хотя и ценой меньшей скорости по сравнению с точным поиском. Именно такой поиск и было решено реализовать в разрабатываемой электронной библиотеке , , , .
2. Материалы и методы
Проектирование разрабатываемой электронной библиотеки целесообразно проводить на основе предварительного анализа, структуризации и систематизации информации предметной области. Разработка онтологической модели предметной области начинается с онтологического анализа . С этой целью в среде Protege был разработан соответствующий задаче набор классов, свойств этих классов, а также набор связей и взаимодействий между ними, в результате чего была получена онтологическая модель предметной области. Онтологический граф модели представлен на рисунке 1.
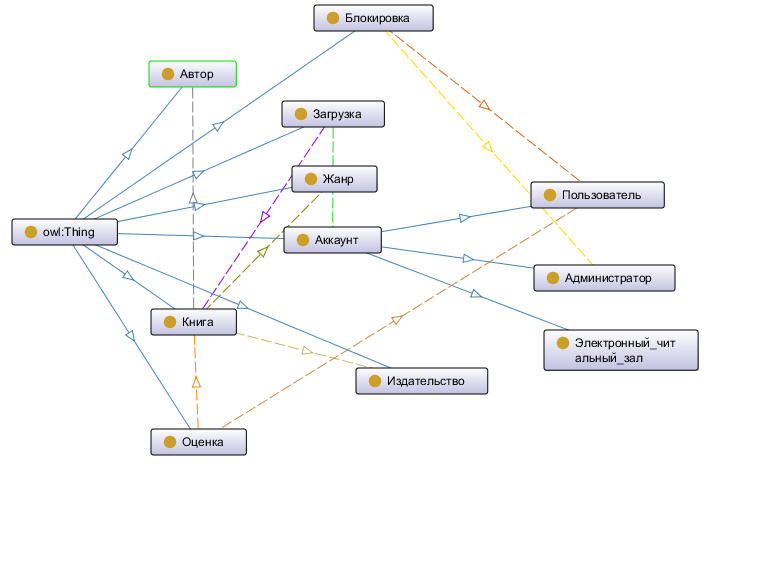
Рисунок 1 - Онтологический граф модели
Предложенная расширенная онтологическая модель предметной области для электронных библиотек отличается от известных расширенным набором сущностей и классов предметной области.
Кроме проведения онтологического моделирования нужно оптимальным организовать структуру электронной библиотеки. В этом большую помощь могут оказать технологии имитационного моделирования, которые на сегодня являются одним из наиболее востребованных инструментов в научных исследованиях, управленческой и производственной деятельности, обучении и других областях.
Цель проведенного имитационного моделирования – это определить оптимальные значения следующих характеристик электронной библиотеки: количество администраторов, количество оцифровщиков, число библиотекарей и компьютеров в электронном читальном зале, время обработки запроса сервером.
С учетом указанной цели исследования в среде GPSS Studio была проведена разработка 4 оригинальных дискретно-событийных имитационных GPSS-моделей: одной – для моделирования обработки сервером запросов, второй – для добавления книг администраторами, третьей – для процесса оцифровки бумажных книг перед их добавлением в библиотеку и четвертой – для моделирования работы электронного читального зала , , , . Важной особенностью этих моделей является то, что они, в отличие от известных аналогичных моделей, имеют комплексный характер и позволяют учитывать как особенности работы аппаратного обеспечения электронной библиотеки, так и человеческий фактор, связанный с деятельностью ее сотрудников. Для примера рассмотрим структуру одной из 4 разработанных моделей для блока электронного читального зала .
Q-схема модели для блока электронного читального зала представлена на рисунке 2.
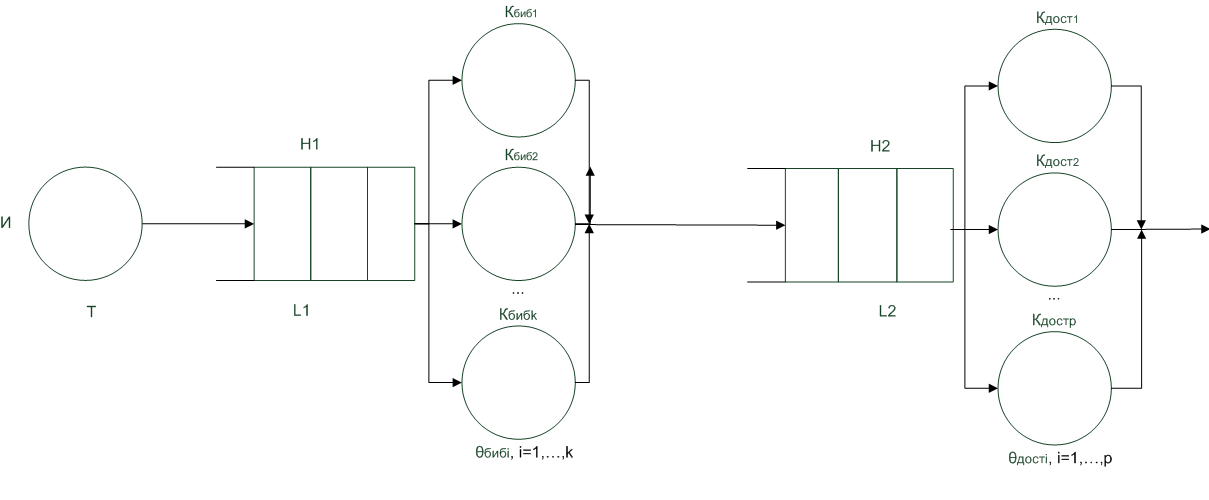
Рисунок 2 - Q-схема модели для блока электронного читального зала
Исходные количественные данные (интервал поступления заявок, время обработки заявок) для модели были получены экспериментально путем мониторинга работы электронного читального зала библиотеки в течение нескольких рабочих дней, в результате чего были определены средние значения указанных величин и сделано предположение об их распределении.
В качестве входного потока заявок используется простейший поток заявок с интервалом поступления, распределенным по экспоненциальному закону распределения, так как заявки поступают в совершенно случайный момент времени, и именно такой подход, как правило, применяется на практике при имитационном моделировании систем. Также экспоненциальное распределение принято для соответствующих длительностей обслуживания заявок разработанной многофазной сети массового обслуживания. Для блока электронного читального зала единица времени также равна 1 минуте, а временной промежуток составляет 1 рабочий день (8 часов).
Пример исследования разработанной имитационной модели в среде имитационного моделирования GPSS Studio представлен на рисунке 3.
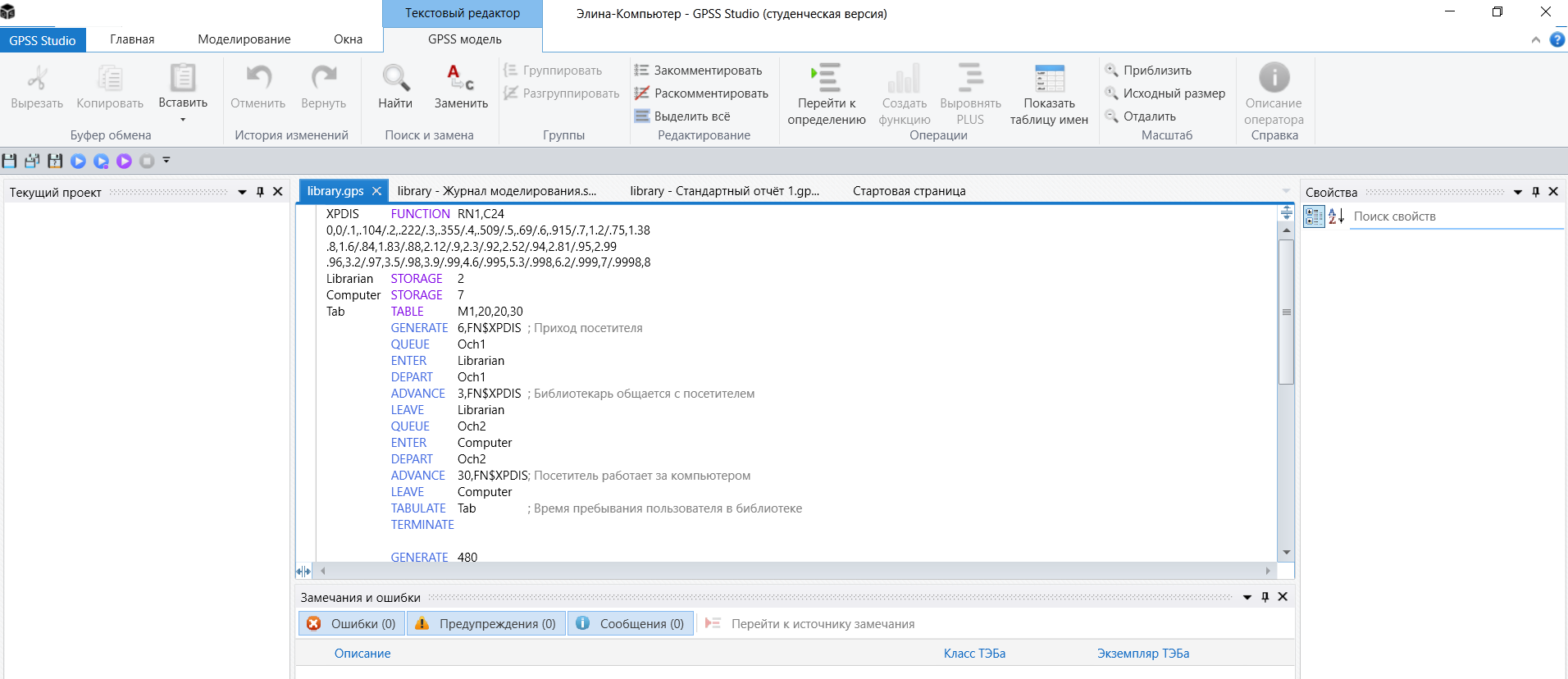
Рисунок 3 - Исследование модели в среде GPSS Studio
Существует множество известных алгоритмов нечеткого поиска, каждый из которых имеет свои достоинства и недостатки , , , . К ним относятся следующие:
- алгоритм расширения выборки;
- метод N-грамм;
- метод хеширования по сигнатуре;
- метод BK-деревьев и т.д.
В качестве базовой основы для разработки модифицированного алгоритма поиска книг был выбран алгоритм расширения выборки. Данный алгоритм основывается на сведении задачи о нечетком поиске к задаче о точном поиске. Из исходного запроса формируется множество «ошибочных» запросов, после чего для каждого из них выполняется точный поиск. Основной принцип работы алгоритма показан на рисунке 4.
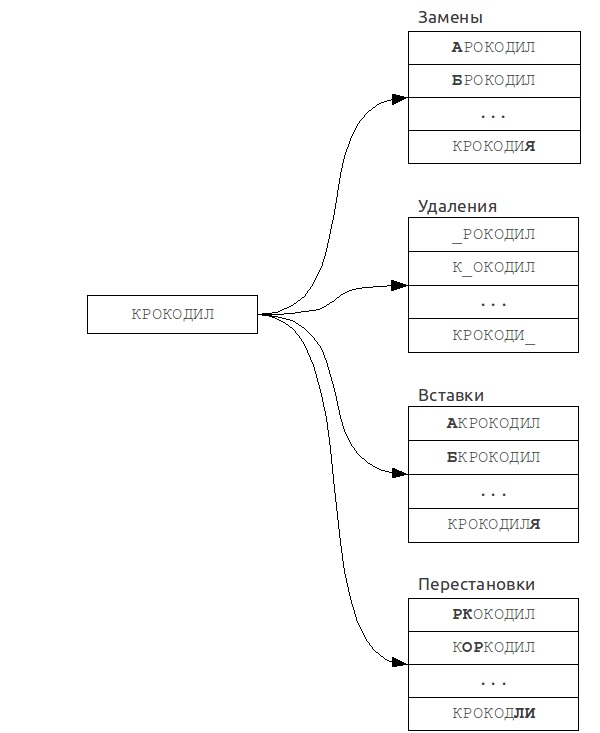
Рисунок 4 - Принцип работы алгоритма расширения выборки
К основным его недостаткам относится относительно низкая скорость поиска, в связи с чем разработанная модификация алгоритма должна обеспечить его ускорение. С этой целью из числа возможных вариантов ошибок поисковых запросов будут проверяться только наиболее вероятные. Маловероятные ошибки будут игнорироваться, что позволяет дать довольно существенное увеличение скорости поиска за счет приемлемых потерь в надежности. Вероятность возможных ошибок определяется на основе местоположения символов на клавиатуре, а также типовых орфографических ошибок в русском языке (например, «с» вместо «з», «а» вместо «о» и тому подобное).
Диаграмма деятельности для разработанного модифицированного алгоритма поиска представлена на рисунке 5.
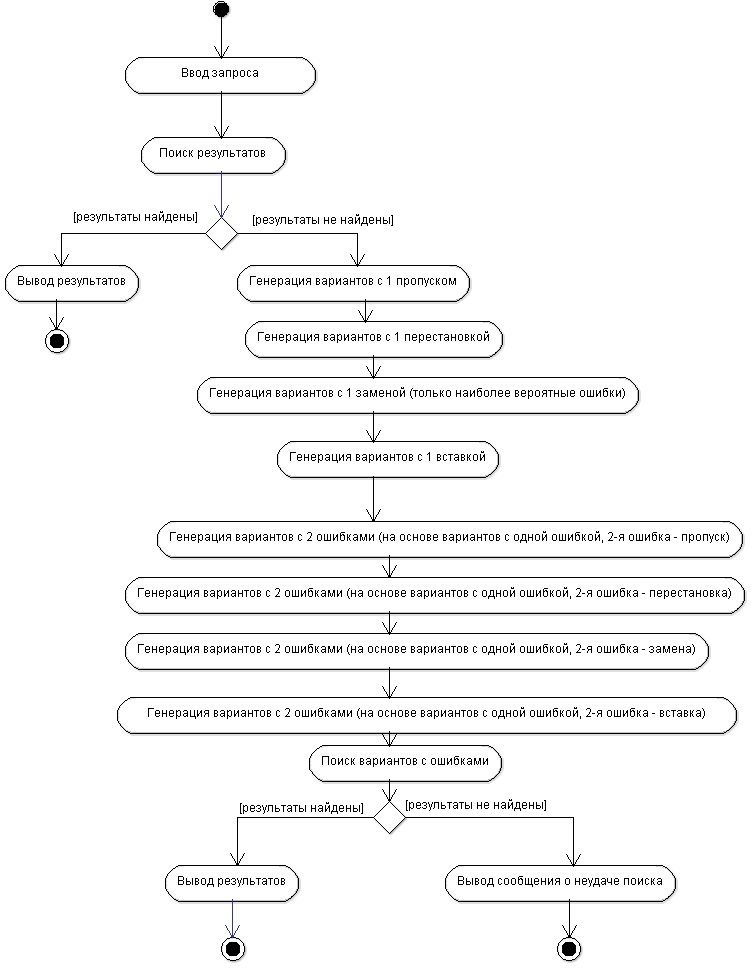
Рисунок 5 - Диаграмма деятельности модифицированного алгоритма
3. Основные результаты
Для доказательства полученных аналитическим путем улучшений в модифицированном алгоритме поиска был организован и проведен соответствующий эксперимент. С этой целью в инструментальной среде Visual Studio наряду с программой на языке С#, реализующей предлагаемый модифицированный алгоритм поиска, также была разработана программа, реализующая поиск по классическому алгоритму расширения выборки.
Результаты эксперимента по сравнению времени поиска для классического и модифицированного алгоритмов для одних и тех же запросов и на одних и тех же тестовых данных представлены на рисунке 6.
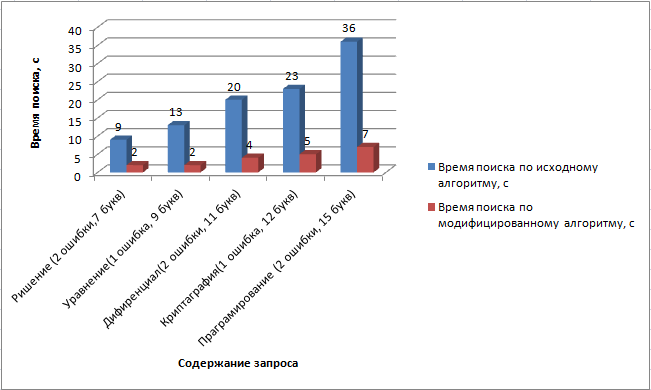
Рисунок 6 - Результаты проведенного эксперимента (время поиска)
Для проверки сохранения надежности поиска для модифицированного алгоритма в приемлемых пределах используем F-меру Ван Ризбергена. Для ее вычисления сначала нужно найти точность и полноту результатов поиска. Они вычисляются по следующим формулам:
где Presicion – точность, Recall – полнота, TP – число истинно-положительных результатов, FP – число ложно-положительных результатов, FN – число ложно-отрицательных результатов.
F-мера Ван Ризбергена вычисляется по формуле:
F = (β2+1)(Presicion × Recall)/(β2 Presicion+ Recall),
где β – некоторый коэффициент, предназначенный для задания приоритета точности или полноты. При 0< β <1 больший упор делается на точность, при β >1 - на полноту, при β =1 (сбалансированная F-мера) точность и полнота считаются равнозначными. В рамках эксперимента использовалась сбалансированная F-мера, для которой формула вычисления принимает вид:
Результаты эксперимента по сравнению F-меры поиска для классического и модифицированного алгоритмов для одних и тех же запросов и на одних и тех же тестовых данных, вычисленные в среде табличного процессора Excel по приведенным выше формулам, представлены на рисунке 7.
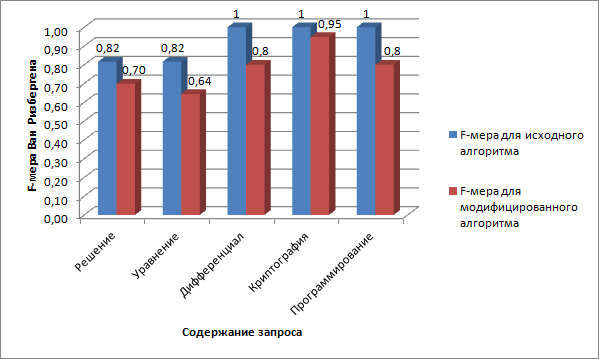
Рисунок 7 - Результаты проведенного эксперимента (F-мера)
Таким образом, для модифицированного алгоритма F-мера в среднем на 0,15 меньше, чем для классического, что свидетельствует о приемлемых потерях в надежности поиска.
4. Заключение
В ходе проведенного исследования был показан процесс разработки модифицированного алгоритма поиска книг в электронной библиотеке с целью улучшения параметров поиска. В качестве научной новизны в проведенном исследовании нужно отметить то, что предложен модифицированный алгоритм поиска, отличающийся от классического алгоритма расширения выборки, на основе которого он создан, большей скоростью поиска при сохранении приемлемой надежности. Был проведен компьютерный эксперимент, результаты которого подтвердили эффективность предложенного модифицированного алгоритма поиска книг в электронной библиотеке. Также при разработке электронной библиотеке была предложена онтологическая модель предметной области, отличающаяся от известных расширенным набором сущностей и классов предметной области, и набор оригинальных дискретно-событийных имитационных GPSS-моделей, важной особенностью которых является то, что они, в отличие от известных аналогичных моделей, имеют комплексный характер и позволяют учитывать как особенности работы аппаратного обеспечения электронной библиотеки, так и человеческий фактор, связанный с деятельностью ее сотрудников.