Гибридное программирование MPI+T++ для T-системы с открытой архитектурой
Гибридное программирование MPI+T++ для T-системы с открытой архитектурой
Аннотация
В настоящее время существует большое количество высокопроизводительных вычислительных систем, состоящих из узлов с многоядерными процессорами и ускорителями от разных производителей оборудования. Удобной моделью программирования в таких системах является модель MPI+X. Гибридные программы MPI+X часто имеют более высокую производительность по сравнению с программами на «чистом» MPI. Научные результаты, полученные при разработке таких программ, используются для создания новых версий стандарта MPI (Message Passing Interface). Гибридный метод параллельного программирования состоит в использовании модели общей памяти внутри узла и модели передачи сообщений MPI для обмена данными между узлами. Примеры гибридных моделей: MPI+OpenMP, MPI+Posix Threads, MPI+CUDA, MPI+T++ и другие. Программирование в смешанном режиме даёт разработчику возможность добиться более высокой производительности и масштабируемости приложения. В некоторых случаях смешанный код может выполняться медленнее, чем код, написанный на «чистом» MPI. В статье описываются некоторые аспекты, связанные с гибридной моделью программирования MPI+T++ в среде OpenTS. Т‑система (OpenTS) – система для параллельного программирования, поддерживающая динамически загружаемые библиотеки для коммуникационного уровня. В системе OpenTS реализован язык для параллельных вычислений Т++, который является расширением языка программирования C++. Синтаксис языка Т++ отличается от синтаксиса языка С++ добавлением в него нескольких ключевых слов. В статье приведены результаты испытаний производительности приложений MPI+T++ из пакета Mantevo (CoMD, HPCCG, MiniAero, phdMesh) и примеров из пакета LAMMPS, реализованных в среде OpenTS. В пакет Mantevo входят несколько параллельных приложений, в которых реализованы алгоритмы для решения некоторых дифференциальных уравнений с частными производными. Дается оценка эффективности такой реализации в сравнении с оригинальными MPI‑версиями приложений. В статье приведен простой пример гибридного MPI+T++ приложения на языке T++.
1. Введение
Интерфейс передачи сообщений MPI (Message Passing Interface) является стандартом для межузловой связи. Он определяет семантику и синтаксис коммуникационных функций. Он был разработан научным сообществом и промышленностью для стандартизации программирования передачи сообщений. На сегодняшний день есть две основные реализации MPI: OpenMPI
и MPICH . Существует также несколько других реализаций MPI .Архитектуры узлов HPC (High-Performance Computing) имеют тенденцию к увеличению количества ядер в одном процессоре, а также используют ускорители, например, графические процессоры. Чтобы лучше использовать общие ресурсы внутри узла и программировать ускорители, пользователи обратились к гибридному программированию, которое сочетает в себе MPI с моделями параллельного программирования на уровне узла.
Параллельные многопоточные программы становятся все более распространенными. Параллельные вычисления становятся все более популярными, и создание эффективных моделей параллельного программирования является приоритетной задачей. Модели с общей памятью и распределенной памятью – это две хорошо известные классификации модели параллельной аппаратной архитектуры. Использование ресурсов всех ядер и снижение временных затрат является основной целью модели многоядерного программирования
.Гибридное параллельное программирование в модели MPI+X стало нормой в высокопроизводительных вычислениях
. Этот подход к параллельному программированию отражает иерархию параллелизма в современных высокопроизводительных системах, в которых высокоскоростное соединение объединяет множество узлов.Последние тенденции в области высокопроизводительных вычислений (HPC) – использовать ускорители (графические процессоры), программируемые пользователем вентильные матрицы (FPGA), сопроцессоры, ‑‑ привели к значительной неоднородности в вычислительных подсистемах и подсистемах памяти.
Разработчики приложений обычно используют модель интерфейса передачи сообщений MPI на вычислительных узлах кластера, и внутриузловую модель, такую как OpenMP или библиотеку для ускорителя (например: CUDA, OpenACC).
Гибридный метод параллельного программирования состоит в использовании модели общей памяти внутри узла и модели передачи сообщений для обмена данными между узлами
. Программирование в смешанном режиме даёт разработчику возможность добиться более высокой производительности и масштабируемости приложения.Т‑система (OpenTS) является средой программирования для разработки высокопроизводительных и хорошо масштабируемых приложений
. Она поддерживает язык T++, который дополняет стандартный язык C++ включением в него нескольких ключевых слов.Ключевые слова необходимы для определения T‑переменных и T‑функций в теле T-программы, которая будет выполняться параллельно на вычислительной установке или суперкомпьютере.
Динамическая библиотека OpenTS DMPI является неотъемлемой частью T-системы.
T‑система является самодостаточной системой в том смысле, что программисту нет необходимости использовать в своей программе MPI‑вызовы. Однако, если есть необходимость использовать вызовы MPI, например, для достижения более высокой производительности программы, то это можно делать.
Гибридное программирование MPI+T+ в среде OpenTS предполагает, что основная часть кода реализуется на языке T++, при этом в теле T‑программы используется библиотека MPI.
Цель статьи – познакомить читателя с приложениями MPI+T++, которые занимают свое место среди гибридных приложений. В статье рассматривается простой пример гибридного MPI+T++ приложения на языке T++. Приводятся результаты тестирования четырех MPI+T++ реализаций приложений из пакета Mantevo и четырех примеров из пакета LAMMPS в сравнении с их оригинальными MPI‑версиями.
Испытание происходило в несколько этапов, на каждом этапе определялось среднее значение производительности приложения.
2. Простой пример гибридного MPI+T++ приложения на языке программирования T++
Рассмотрим простой пример гибридного MPI+T++ приложения на языке T++.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define USRTAG 1024
#define MSGSIZE 128
static int root_rank = 0;
static int worker_rank = 1;
tfun int tworker() {
printf("I am node %d of %d.\n", ts::myRank, ts::realsuperSize);
tval int tx;
char msg[MSGSIZE];
MPI_Status stat;
memset(msg, '\0', sizeof(msg));
MPI_Recv(msg, sizeof(msg) - 1, MPI_BYTE, root_rank, USRTAG, MPI_COMM_WORLD, &stat);
printf("node=%d, msg=\"%s\"\n", ts::myRank, msg);
tx = 1;
return (int) tx;
}
tfun int main(int argc, char *argv[]) {
static char *MSG = (char *) "This is a message from the root T-process!";
if (ts::realsuperSize != 2) {
printf("\n\nSorry, this program works correctly only for the two ranks!\n\n");
exit(0);
}
printf("I am node %d of %d.\n", ts::myRank, ts::realsuperSize);
tval int tv;
tct(atRank(worker_rank % ts::realsuperSize));
tv = tworker();
MPI_Send(MSG, strlen(MSG), MPI_BYTE, worker_rank, USRTAG, MPI_COMM_WORLD);
(int) tv;
return 0;
}
В приведенном примере создаются два процесса на двух узлах (рангах) вычислительной установки: первый – основной процесс – создается на нулевом узле, а второй ‑ рабочий процесс – на первом узле. Основной процесс представлен в виде Т-функции main(), а рабочий процесс – в виде Т-функции tworker(). Т-функция main() создает рабочий процесс на первом ранге вычислительной установки с помощью операторов:
tval int tv;
tct(atRank(worker_rank % ts::realsuperSize));
tv = tworker();
В теле T‑программы определяется T‑переменная tv. Выход Т-функции tworker() присваивается Т-переменной tv. Далее, основной процесс посылает данные ‑‑ сообщение: "This is a message from the root T-process!"‑‑ рабочему процессу с помощью вызова MPI-функции MPI_Send(). После этого основной процесс ждет завершения работы рабочего процесса (готовности Т-переменной tv) с помощью оператора:
(int) tv;
В теле Т-функции tworker() выполняется вызов MPI-функции MPI_Recv() для приема сообщения от основного процесса. После этого рабочий процесс производит печать полученного сообщения и завершает свою работу.
3. Приложение CoMD
CoMD – простое приложение молекулярной динамики проекта Mantevo. Имитирует реализацию SPaSM (Scalable Parallel Short-Range Molecular Dynamics).
Реализация приложения CoMD (и других приложений) на MPI+T++ происходила следующим образом. Функцию С++ main пакета CoMD мы переименовали в worker. В пакет мы добавили файл на языке программирования Т++, который параллельно запускает столько задач, сколько в текущей вычислительной системе вычислительных узлов, по одной задаче на каждом вычислительном узле. Каждая из этих задач вызывает функцию worker. Обеспечивается передача параметров командной строки в каждый из экземпляров функции worker. Все вхождения файла <mpi.h> заменяются на заголовочный файл, необходимый для корректной работы Т‑системы. Происходит сборка исполняемого файла с использованием компилятора Т++.
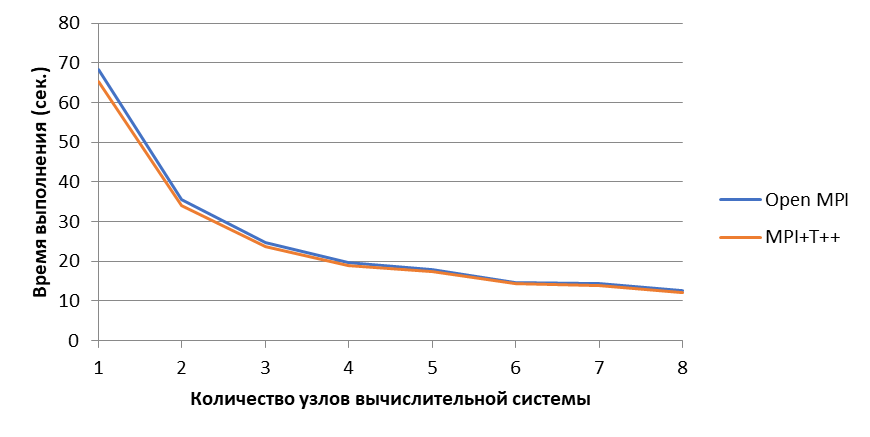
Рисунок 1 - На рисунке представлены два графика: среднее время выполнения CoMD с использованием OpenMPI и среднее время выполнения CoMD с использованием MPI+T++
4. Приложение HPCCG
Приложение HPCCG из проекта Mantevo является решателем линейной системы уравнений с частными производными на области, которая имеет форму пучка лучей (beam shaped). Для решения системы уравнений используется метод сопряжённых градиентов с предобусловливанием.
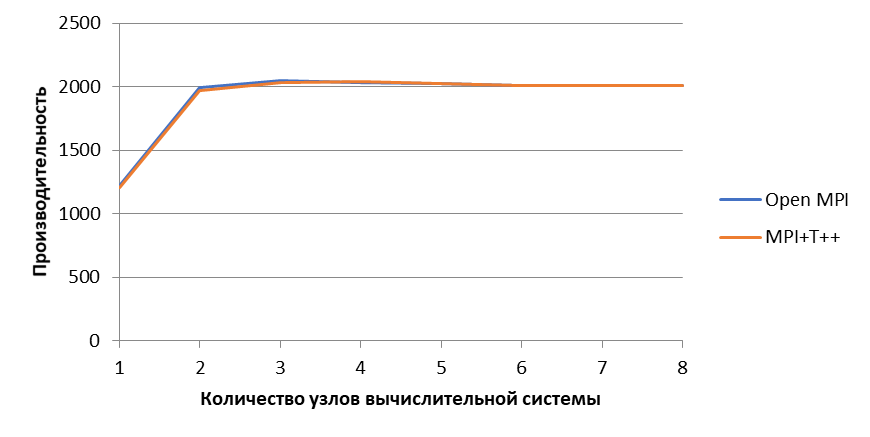
Рисунок 2 - На рисунке представлены два графика: средняя производительность HPCCG с использованием OpenMPI и средняя производительность HPCCG с использованием MPI+T++
5. Приложение MiniAero
В приложении MiniAero из проекта Mantevo строится решение уравнения Навье-Стокса для сжимаемой жидкости методом Рунге-Кутта четвертого порядка.
Было проведено сравнительное тестирование приложений MiniAero OpenMPI и MiniAero MPI+T++. Испытывался один из тестов miniAero FlatPlate_Parallel на 8 процессорах. Проводилось 10 испытаний. Отклонение среднего значения производительности приложения составило 0.1%., то есть производительность приложения miniAero MPI+T++ приблизительно совпадает с производительностью приложения miniAero OpenMPI.
6. Приложение phdMesh
Пакет phdMesh проекта Mantevo поддерживает параллельные гетерогенные вычисления с использованием динамической неструктурированной сетки.
Было проведено сравнительное тестирование приложений phdMesh OpenMPI и phdMeshMPI+T++ на 8 процессорах. Отклонение среднего значения времени работы приложения составило 1%., то есть производительность приложения phdMeshMPI+T++ приблизительно совпадает с производительностью приложения phdMesh OpenMPI.
7. Модель погруженного иона
Рисунок 3 - Пример eim LAMMPS. Модель погруженного иона для хлористого натрия
,
где N – количество атомов, ϕij – функция парного потенциала, rij – расстояние между i-м и j-м атомами, i1, ..., iN – соседние атомы атома i, Ei – энергия погружения атома i, qi – заряд, σi – электрический потенциал.
,
,
,
Где ηji – парная функция, описывающая поток электронов от атома i к атому j,
Ψij – парная функция, связанная с кулоновским взаимодействием.
В пакете LAMMPS
модель применялась к системе из 1000 молекул хлористого натрия (рисунок 3).Было проведено сравнительное тестирование примера eim пакета LAMMPS на платформах OpenMPI и MPI+T++. Отклонение среднего значения времени работы приложения составило 0.2%., то есть производительность приложения eim LAMMPS MPI+T++ приблизительно совпадает с производительностью приложения eim LAMMPS OpenMPI.
8. Связанные наностержни (tethered nanorods)
Рисунок 4 - Пример rigid LAMMPS. Наностержни со связями (tethered nanorods)
9. Симуляция деформации сдвига металла
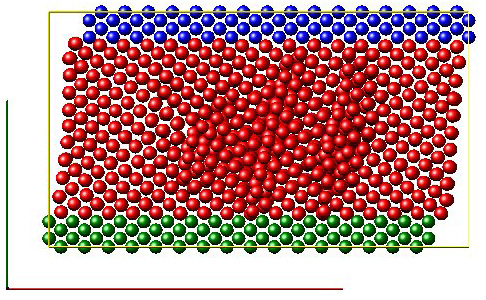
Рисунок 5 - Пример shear LAMMPS. Симуляция деформации сдвига куска металла
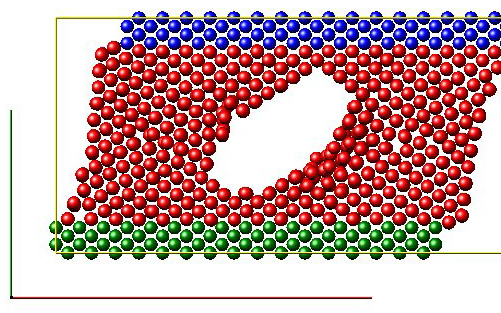
Рисунок 6 - Пример shear LAMMPS. Симуляция деформации сдвига куска металла с пузырем внутри
10. Динамика многочастичных взаимодействий
Динамика многочастичных взаимодействий (Multi-particle collision dynamics), также известная как стохастическая динамика вращения (Stochastic rotation dynamics), представляет собой метод мезомасштабного моделирования сложных жидкостей на основе частиц, который полностью включает в себя тепловые флуктуации и гидродинамические взаимодействия. Связь внедренных частиц с крупнозернистым растворителем достигается с помощью молекулярной динамики. Модель может использоваться для изучения поведения микроэмульсий или растворенных гибкоцепных полимеров.
В пакете LAMMPS
растворитель моделируется в виде набора N частиц массы m с непрерывными координатами ri и скоростями vi. Алгоритм симуляции состоит из шагов моделирования движения и столкновения частиц. На шаге моделирования движения координаты ri всех частиц растворителя в момент времени t одновременно обновляются в соответствии с.
При моделировании взаимодействий частицы группируются по ячейкам, и они взаимодействуют только с частицами из той же ячейки, обычно для этого строится решетка. Как правило, количество частиц в каждой ячейке – от 3 до 20. Скорости частиц в каждой ячейке обновляются в соответствии с правилом столкновения
,

Рисунок 7 - Пример LAMMPS srd. Большие частицы находятся в крупнозернистом растворителе
Примечание: модель динамики многочастичных взаимодействий
11. Заключение
Приложения MPI+X занимают важное место среди приложений для высокопроизводительных вычислений. Приложения MPI+T++ – это приложения, написанные на языке для параллельных вычислений T++ с добавлением вызовов функций MPI. В статье приводится пример простого приложения MPI+T++ на языке программирования T++ и описываются результаты тестирования производительности восьми приложений MPI+T++. По результатам тестирования можно сделать вывод, что производительность MPI+T++ реализаций приложений из пакета Mantevo незначительно отличается от производительности соответствующих OpenMPI реализаций.