ОБ ИСПОЛЬЗОВАНИИ КОЛМОГОРОВСКОЙ СЛОЖНОСТИ ДЛЯ ИССЛЕДОВАНИЯ СХОЖЕСТИ ИЗОБРАЖЕНИЙ
ORCID: 0000-0002-0683-0019, Доктор технических наук,
Карельский научный центр Российской академии наук, Петрозаводск, Россия
ОБ ИСПОЛЬЗОВАНИИ КОЛМОГОРОВСКОЙ СЛОЖНОСТИ ДЛЯ ИССЛЕДОВАНИЯ СХОЖЕСТИ ИЗОБРАЖЕНИЙ
Аннотация
Предложен подход к исследованию схожести изображений с использованием теоретического понятия Колмогоровской сложности, являющегося основой для нормализованного расстояния сжатия. Описан конкретный эксперимент, выполненный с применением известных программных средств типа программ-архиваторов и стандартных статистических процедур, и показывающий возможности такого подхода. Формулируется ряд вопросов, которые требуется исследовать, прежде чем автоматизировать проведение больших исследований.
Ключевые слова: Колмогоровская сложность, нормализованное расстояние сжатия, обработка изображений, флаг страны, иерархическая кластеризация.
Pechnikov A.A.
ORCID: 0000-0002-0683-0019, PhD in Engineering,
Karelian Research Center of the Russian Academy of Sciences, Petrozavodsk, Russia
ON USE OF KOLMOGOROV COMPLEXITY FOR INVESTIGATION OF IMAGES
Abstract
The approach to the study of the similarity of images with the use of the theoretical concept of Kolmogorov complexity is proposed in the paper, this similarity is the basis for the normalized compression distance. A specific experiment, performed with the use of known software such as archiver programs and standard statistical procedures is described, it shows the possibility of such an approach. A number of questions are formulated and they have to be investigated before automating large studies.
Keywords: Kolmogorov complexity, normalized compression distance, image processing, country flag, hierarchical clustering.
Проблема поиска похожих изображений активно изучается, по крайней мере, последние двадцать пять лет [1] и результаты этих исследований широко применяются в самых разных областях человеческой деятельности, связанных с электронными ресурсами, Интернетом и не только. Как правило, алгоритмы поиска анализируют содержание изображения (Content-based image retrieval), например, цвет представленных на нём объектов, их форму, текстуру или разделяют изображения на ячейки, для которых строят гистограммы направлений градиентов (Histogram of Oriented Gradients); современные обзоры в [2], [3]. Наша попытка добавить что-то новое к исследованиям этой проблемы является несколько иной, мы не ищем сходства во многих конкретных признаках. Задача в постановке, изложенной в этом кратком сообщении, возникла в связи с исследованием более общей задачи схожести сайтов с использованием нормализованного расстояния сжатия (Normalized Compression Distance – NCD) [4], базирующегося, в свою очередь, на теоретическом понятии Колмогоровской сложности [5,6]. Ранее показано, что эта универсальная характеристика сходства хорошо работает на конкретных примерах в самых разных областях применения, таких как автоматическое конструирование дерева филогенеза [7], классификация музыкальных жанров [8], анализ текстовых данных в задачах обеспечения кибербезопасности [9] и др.
Этот подход в нашем случае уже на первых шагах показал определенный потенциал для исследования схожести сайтов на уровне текстового представления его первых html-страниц [10]. Очевидность того факта, что сайт – это далеко не только первая страница, и не только html-файлы, привела к мысли попробовать этот же подход к изображениям для дальнейшего совмещения структуры, сценариев, стилей, текстов и изображений, составляющих веб-сайт, и исследования схожести веб-сайтов по некоей единой методике.
Следуя [7] способом описания (или декомпрессором), называется произвольное вычислимое частичное отображение D из множества двоичных слов Ξ в себя. Если D(y)=x, говорят, что y является описанием x при способе описания D. Для каждого способа описания D мы определяем сложность относительно этого способа описания, полагая её равной длине кратчайшего описания l(y):
![]()
Теперь зафиксируем некоторый (не обязательно оптимальный) способ описания, и сложность слова x относительно этого способа описания обозначим K(x). Для простоты скажем сразу, что в дальнейшем мы будем ее считать равной числу битов в сжатой версии x, а в качестве отображения D мы будем использовать стандартную программу-архиватор.
Пусть y – еще одно двоичное слово. Обозначим K(x|y) минимальное количество битов, необходимых для восстановления x из y. Для любой пары строк x и y можно определить нормализованное расстояние сжатия как:
![]() (1)
(1)
Грубо говоря, два объекта считаются близкими, если мы можем значительно "сжать" один из них, учитывая информацию, содержащуюся в другом; идея заключается в том, что если два объекта достаточно похожи, то мы можем более кратко описать один из них, учитывая информацию другого.
В [11] доказывается весьма изощренная теорема о симметрии алгоритмической информации, следствием из которой является приближенное равенство (здесь yx обозначает конкатенацию двоичных строк y и x)
![]() (2)
(2)
Опишем применение этого подхода для определения схожести изображений на примере одного из серии очень простых экспериментов, с полученными наглядными результатами. Мы взяли в качестве объектов-изображений флаги 15 стран мира с сайта «ВСЕ ФЛАГИ СТРАН МИРА в HD» (http://flagi-1.ru) в формате .png и имеющих одинаковую ширину 2560 пикселей (и несколько разную высоту, что зависит не от нас, а от пропорций флага, заданных государственным нормативным актом).
Все они пронумерованы от 1 до 15 и содержатся в файлах с номерами в качестве имен: 1 – Чад, 2 Финляндия, 3 – Фарерские острова, 4 – Франция, 5 – Нидерланды, 6 – Румыния, 7 – Россия, 8 – Сербия, 9 – Словакия, 10 – Австрия, 11 – Греция, 12 – Израиль, 13 – Монако, 14 – Польша, 15 – Индонезия.
Конвертируем их в текстовое представление в стандарте кодирования двоичных данных Base64, сохраняя в файлах с соответствующими номерами и расширением .txt. Архивируем текстовые файлы свободным файловым архиватором 7–Zip, получая для каждого флага i файл с его номером и типом i.7Z, размер которого в байтах принимаем в качестве оценки сложности соответствующего флага K(i). Заметим, что архиватор должен обладать свойствами идемпотентности, монотонности, симметричности и дистрибутивности, которым удовлетворяет 7-Zip в данном эксперименте.
Для каждой пары флагов i и j выполняем конкатенацию их текстовых представлений как добавление содержимого файла j.txt в конец файла i.txt, получая файл ij.txt, архивируем его и получаем оценку сложности K(ij). Зная оценки сложности K(i), K(j), K(ij) по формуле (1) с использованием (2) вычисляем приближенные значения матрицы расстояний {NCD(i,j)}, i,j=1,..15.
Например, для флага 1 (Чад) объем файла 1.png равен 21250 байт, и после конвертации его в текстовое представление в стандарте кодирования двоичных данных Base64 получаем файл 1.txt объемом 28336 байт. Затем архивируем этот файл и получаем файл 1.7-zip объемом 715 байт, то есть K(1)=715.
Для флага 2 (Финляндия) имеем объем 2.png, равный 19702 байт, объем 2.txt – 26272 байта, 2.7-zip – 890 байт, то есть K(2)=890.
Конкатенация файлов 1.txt и 2.txt дает нам файл объемом 54610 байт, а файл 12.7-zip объемом 1242 байта, значит K(12)=1242.
По формуле (2) K(x|y)≈352, K(y|x)≈527 и по формуле (1) NCD(1,2)=0,59213.
Для флага 6 (Румыния) объем 6.png равен 21251 байт, объем 6.txt – 28336 байта, K(6)=707, а NCD(1,6)=0,37483.
То есть расстояние между флагами Чала и Румынии гораздо меньше, чем флагами Чада и Финляндии.
Дендрограмма, построенная по методу ближайшего соседа [12] применительно к данной матрице расстояний, приводится на рисунке 1.
Практически точно обнаружена близость по кратчайшему расстоянию флагов 13 (Монако) и 15 (Индонезия), имеющих красно-белые цвета и одинаково расположенные части с разной раскраской. При этом кажущиеся практически идентичными флаги 1 (Чад) и 6 (Румыния) находятся на несколько большем расстоянии, чем флаги 13 и 15, что, по-видимому, объясняется разными оттенками синего цвета (это можно увидеть только на большом изображении). Очень близок к ним флаг 4 (Франция), и так же достаточно очевидна причина этого, заключающаяся в различии полосы флага, расположенной в его середине.
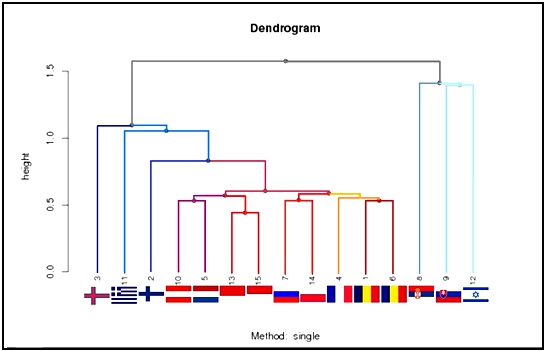
Рис. 1 – Дендрограмма по методу одиночной связи
Отдельную ветвь дендрограммы (на рисунке 1 справа) образуют три флага, имеющие дополнительные изображения: гербы на флагах 8 и 9 (Сербия и Словакия) и звезда Давида на флаге 12 (Израиль). Представляется, что усложнение изображения флага является весьма существенным для его сжатия.
Как минимум, полученные результаты не противоречат «интуитивному» представлению. Самые схожие флаги попарно наиболее близки, самые несхожие наиболее далеки друг от друга.
Возможные направления развития предложенного подхода:
- Увеличение сложности изображений и добавление к ним текстовых фрагментов, что характерно для построения веб-страниц. В первую очередь надо исследовать и предложить решение вопроса о том, что в таком случае представляет собой некий аналог двоичного слова x, и как в одном таком «слове» совместить по единой методике несколько изображении и текстов, составляющих страницы веб-сайтов.
- Теоретические оценки сложности алгоритма реализации данного подхода, которые с учетом композиции изображений и текстов не выглядят очевидными.
- Сравнение результатов данного подхода с известными подходами [2,3], и т.д.
Список литературы / References
- Kato T. A Sketch Retrieval Method for Full Color Image Database. Query by Visual Example / T. Kato, T. Kurita, N. Otsu and others // Proc. of Int. Conf. on Pattern Recognition. – 1992. – P. 530-533.
- Венцов Н.Н. Обзор алгоритмов кластеризации, используемых в задачах поиска изображений по содержанию / Н.Н. Венцов, В.В. Долгов, Л.А. Подколзина // Инженерный вестник Дона (Электронный научный журнал). – 2016. – №3. http://ivdon.ru/ru/magazine/archive/n3y2016/3707.
- Datta R. Image retrieval: Ideas, influences, and trends of the new age / R. Datta, D. Joshi, J. Li and others // ACM Computing Surveys. – April 2008. – V. 40. – No. 2. – Article 5. doi.acm.org/10.1145/1348246.1348248.
- Cilibrasi R. Clustering by compression / R. Cilibrasi, P. Vitanyi // IEEE Transactions on Information Theory. – 2005. – V. 51. – Iss. 4. – P. 1523-1545.
- Колмогоров А.Н. Три подхода к определению понятия «количество информации» / А.Н. Колмогоров // Проблемы передачи информации. – 1965. – Т. 1. – Вып. 1. – С. 3-11.
- Верещагин Н.К. А. Колмогоровская сложность и алгоритмическая случайность / Н.К. Верещагин, В.А.Успенский, А. Шень. – М.: МЦНМО, 2013. – 576 с.
- Ming Li An information-based sequence distance and its application to whole mitochondrial genome phylogeny / Li Ming, H. Badger Jonathan, Chen Xin and others // Bioinformatics. – 2001. – V. 1. – No 2. – P. 149-154.
- Cilibrasi R. Algorithmic Clustering of Music Based on String Compression / R. Cilibrasi, P. Vitanyi, R. de Wolf // Computer Music Journal. – Winter 2004. – V. 28. – Iss. 4. – P. 49-67.
- Суркова А.С. Анализ и моделирование текстовых данных в задачах обеспечения кибербезопасности / А.С. Суркова // Системы управления и информационные технологии. – 2015. – №3.1(61). – С. 178-182.
- Печников А.А. О схожести сайтов и колмогоровской сложности / А.А. Печников // Norwegian Journal of development of the International Science. – 2018. – №14. – Vol. 1. – C. 25-29.
- Ming Li An Introduction to Kolmogorov Complexity and Its Applications / Li Ming, P.Vitanyi. – 3rd ed. – New York: Springer-Verlag, 2008. – 809 p.
- Жамбю М. Иерархический кластер-анализ и соответствия / М. Жамбю. – М.: Финансы и статистика, 1988. – 345 с.
Список литературы на английском языке / References in English
- Kato T. A Sketch Retrieval Method for Full Color Image Database. Query by Visual Example / T. Kato, T. Kurita, N. Otsu and oters // Proc. of Int. Conf. on Pattern Recognition. – 1992. – P. 530-533.
- Ventsov N.N. Obzor algoritmov klasterizacii, ispol’zuemyh v zadachah poiska izobrazhenii po soderzhaniju [An overview of clustering algorithms used in the tasks of image search by content] / N.N. Ventsov, V.V. Dolgov, L.A. Podkolzina // Inzhenernyi vestnik Dona (Elektronnyi nauchnyi jurnal) [Engineering journal of Don (E-journal)]. – 2016. – №3. – http://ivdon.ru/ru/magazine/archive/n3y2016/3707. [in Russian].
- Datta R. Image retrieval: Ideas, influences, and trends of the new age / R. Datta, D. Joshi, J. Li and others // ACM Computing Surveys. – April 2008. – V. 40. – No. 2. – Article 5. doi.acm.org/10.1145/1348246.1348248.
- Cilibrasi R. Clustering by compression / R. Cilibrasi, P. Vitanyi// IEEE Transactions on Information Theory. – 2005. – V. 51. – Iss. 4. – P. 1523-1545.
- Kolmogorov A.N. Tri podhoda k opredeleniju ponjatija “kolichectvo informacii” [Three approaches to the definition of "quantity of information"] / A.N. Kolmogorov // Problemy peredachi informacii [Problems of information transmission]. – 1965. –V. 1. – №. 1. – P. 3-11.
- Vereschagin N.K. Kolmogorovskaja slojnost’ i algoritmicheskaja sluchainost’ [Kolmogorov complexity and algorithmic randomness] / N.K. Vereschagin, V.A. Uspenskii, A. Shen – M: MCNMO, 2013. – 576 p.
- Ming Li An information-based sequence distance and its application to whole mitochondrial genome phylogeny / Li Ming, H. Badger Jonathan, Chen Xin and others // Bioinformatics. – 2001. – V. 1. – No 2. – P. 149-154.
- Cilibrasi R. Algorithmic Clustering of Music Based on String Compression / R. Cilibrasi, P. Vitanyi, R. de Wolf // Computer Music Journal. – Winter 2004. – V. 28. – Iss. 4. – P. 49-67.
- Surkova A.S. Analiz i modelirovanie tekstovyh dannyh v zadachah obespechnenija kiberbezopasnosti [Analysis and modeling of text data in the task of cybersecurity] / A.S. Surkova // Sistemy upravlenija i informacionnye tehnologii [Management systems and information technology]. – 2015. – №3.1(61). – P. 178-182.
- Pechnikov A.A. O shojesti saitov I kolmogorovskoi slojnosti [Similarity between sites and Kolmogorov complexity] / A.A. Pechnikov // Norwegian Journal of development of the International Science. – 2018. – №14. – Vol. 1. – P. 25-29.
- Ming Li An Introduction to Kolmogorov Complexity and Its Applications / Li Ming, P.Vitanyi. – 3rd ed. – New York: Springer-Verlag, 2008. – 809 p.
- Jambju M. Ierarhicheskii klaster-analiz i sootvetstvija [Hierarchical cluster-analysis and compliance] / M. Jambju. – M.: Finansy i satatistika – 1988. – 345 p.