РАСПРЕДЕЛЕНИЕ ДЛИТЕЛЬНОСТИ ФОНАЦИОННЫХ ОТРЕЗКОВ В УСТНОПОРОЖДАЕМОМ ВЫСКАЗЫВАНИИ: ЛОГНОРМАЛЬНАЯ МОДЕЛЬ
Ратникова Е.И.
Кандидат филологических наук, Московский Государственный университет имени М.В.Ломоносова
РАСПРЕДЕЛЕНИЕ ДЛИТЕЛЬНОСТИ ФОНАЦИОННЫХ ОТРЕЗКОВ В УСТНОПОРОЖДАЕМОМ ВЫСКАЗЫВАНИИ: ЛОГНОРМАЛЬНАЯ МОДЕЛЬ
Аннотация
В статье представлены результаты экспериментального исследования распределения длительности фонационных отрезков в устнопорождаемом высказывании на материале французского, русского и английского языков в трех ситуациях общения: 1) интервью, 2) устной беседы, 3) устного ответа на экзамене по иностранному языку. В ходе анализа статистически репрезентативного корпуса устных текстов было установлено, что такая темпоральная характеристика устнопорождаемого высказывания как длительность фонационного отрезка подчиняется логнормальному статистическому распределению вне зависимости от типа изучаемой ситуации, индивидуальных особенностей говорящих, тематики и общей длительности высказывания, а также от того, на каком языке осуществляется порождение (родном или иностранном). Подчинение логнормальному распределению количественных характеристик проявлений какого-либо процесса свидетельствует об устойчивости базового механизма, отвечающего за их реализацию. Результаты настоящей работы могут быть использованы при разработке методики анализа устнопорождаемого высказывания, а также компьютерных алгоритмов автоматического распознавания речи.
Ключевые слова: акустическая фонетика, устнопорождаемая речь, логнормальное распределение, фонационный отрезок, пауза.
Ratnikova E.I.
PhD in Philology, Lomonosov Moscow State University
TOWARDS A LOG-NORMAL MODEL OF PHONATION UNITS LENGTHS DISTRIBUTION IN THE ORAL UTTERANCES
Abstract
The present article is concerned with the issue of developing workable approaches to establishing a more robust parametrization of the phonetic and prosodic characteristics of a speech utterance. The article presents the results of an experimental study analyzing the distribution of phonation units within speech utterances produced in the French, Russian and English languages in three communicative situations: 1) interview; 2) general oral discussion and 3) student’s spoken answer in a foreign language test. The analysis of an extensive corpus of recorded speech data showed that such fundamental intrinsic characteristic of speech utterance as the length of its constituent phonation units distinctly follows a log‐normal distribution irrespective of the communicative situation, the language spoken (mother or foreign), the thematic subject and overall duration of the utterance, and the individual manner of the speakers. The findings of the conducted study presented in the article can be a valuable resource for developing a practicable methodology of speech‐utterance analysis, as well as for fine‐tuning and improving the existing speech‐recognition algorithms and approaches.
Keywords: acoustic phonetics, oral speech, speech utterance, log‐normal distribution, phonation unit, pause.
Introduction
One of the principal temporal-acoustic characteristics of a speech signal is the length of its constituent segments. A number of studies conducted in this field have demonstrated that such phenomena as the distribution of the lengths of filled-in pauses in oral French speech [2], the distribution of the lengths of non-filled-in pauses in the speech of sufferers from ataxic dysarthria articulatory disorders [4], and of the lengths of vowels and consonants in oral English speech [3] follow a log-normal model. Besides that, the length-related characteristics of certain specific instances of the written speech have also been found to be log-normally distributed, for example, the length of postings on internet forums dedicated to various subjects [5]. It is also well-known that in many languages the length of speech segments plays a key role in the formation of the rhythmic structure of an utterance, therefore further and more thorough analysis of the observed distribution patterns undoubtedly presents a matter of exceptional scientific interest bound to deepen our knowledge about the speech-production process.
As it is impossible to explore the whole multitude of speech-production forms within a single study, this article narrows down the research subject to three communicative situations: 1) interview, 2) general oral discussion and 3) a student’s spoken answer in a foreign language test. Therefore, the subject of the conducted analysis is monologue spontaneous oral utterance, its spontaneous nature being determined by the absence of any visual (textual) support for the speaker and by the unpredictability of its realization course, the latter, however, not excluding the presence of some general cognitive concept or, in some cases, even of a speech plan. By monologue is meant a long-distance speech production during which the speaker is not interrupted by the listener.
The study adopts a formal approach towards the analysis of the oral utterance, regarding it from the acoustic viewpoint as a combination of phonation units (speech chunks) and pauses. This approach appears to be fully workable at the initial stages of the research as it allows to ensure the required degree of consistency of the input data represented by a large oral-speech corpus (more than 100 speech productions) whose preliminary systematization with the use of perception analysis would have posed considerable difficulties.
While intentionally leaving the language contents of the phonation units outside the boundaries of the analysis, we presume that there exists a certain mechanism, a definitive model, responsible for turning these units into an ultimate speech production. It is the effort to get an insight, however limited, into the workings of this mechanism that lies at the basis of the current research.
The study is dedicated to the exploration of the frequency distribution of phonation units of different lengths making up oral utterances produced, as was mentioned above, in three different communicative situations. The given article presents preliminary results of this experimental research and sets out a hypothesis that irrespective of the communicative situation, thematic speech subject, individual manner of the speaker and the language spoken (mother tongue or taught foreign), the time-length values of the constituent speech segments follow a log-normal distribution.
Experimental Platform
The study examined a corpus of recorded speech data comprising 100 spontaneous monologue speech utterances with a total length 4 minutes produced in three communicative situations: 1) interview, 2) general oral discussion and 3) a student’s spoken answer in a foreign language test. The first group contains recorded radio broadcasts in interview format on various subjects (music, sports, cinema, literature, computer games) conducted in Russian and French respectively on Russian and French radio stations. The second group contains recordings made by the author: the speakers were asked to give an extended monologue answer in native Russian to the question put by the researcher. The third group consists of monologue answers of the Russian school students given during a French language competition (the language competency level B2). Therefore, the analyzed corpus comprises speech recordings both in the native and taught foreign languages, with the age of the speakers, both male and female, lying within the range from 15 to 65 years. The sound files were recorded in .wav file format with a sample rate of 44 kHz and processed in Adobe Audition computer program.
Method
Acoustic analysis and speech signal annotation were made with the use of Praat computer program, whereas the quantitative analysis was performed with the use of Excel and statistical analysis with MiniTab program.
Experiment Stages
- Segmentation of the speech signals into pauses and phonation units in Praat computer program. The utterances were analyzed from the acoustic standpoint, i.e. as interconnected sequence of phonation and pauses. By ‘pause’ is meant a period of complete silence (interruption of the phonation) with a length starting from 200ms [1]. In line with the approaches of traditional linguistics, the so-called ‘filled-in pauses’ are regarded as phonation, which enables a more precise application of the selected segmentation methodology.
- Annotation of the identified segments. Writing orthographic transcription (e.g. see fig. 1 below).
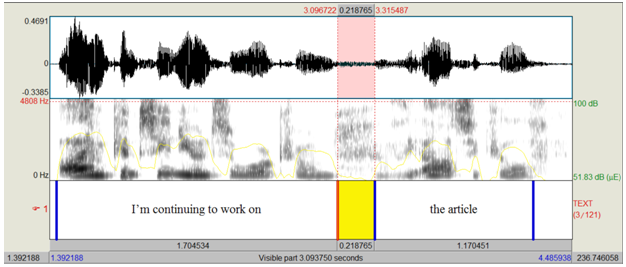
Fig. 1 — Segmentation and annotation of an English utterance as L2
- Calculation of the length of phonation segments in Excel
- Histogram and distribution analysis in MiniTab.
The purpose of the next stage was to establish the character of the observed frequency distribution, which was done with the use of Minitab computer program. The analysis of the output histograms demonstrated the presence of a distinct lognormal distribution. Histograms serve as an instrument for graphically representing the experimentally obtained data and describing its frequency distribution. To make the analyzed data visually compact and easily readable, in accordance with the selected grouping algorithm it is sub-divided by the computer program into intervals, or bins. Along with the total number of data values, this algorithm takes into account their range and variance, thus aiming to ensure the best possible representation of the revealed statistical distribution. The most important characteristic of a histogram is its shape, representing the character of the established frequency distribution.
The histograms built in the course of the experiment contain 9 bins (groups), with an interval of 1 second between the average values of the data in each bin. The first bin contains phonation units with a length 200 to 500ms, the second 500ms to 1.5sec and so on.
The Y axis shows the frequency, i.e. the total number of phonation units. The higher the vertical box, the higher the frequency of the phonation units within the given group. This approach was used for all the oral-speech utterances in the analyzed corpus, i.e. for each speaker was built a separate histogram.
The histogram (frequency) analysis has demonstrated that the lengths of the considered phonation units are log-normally distributed (see fig.2).
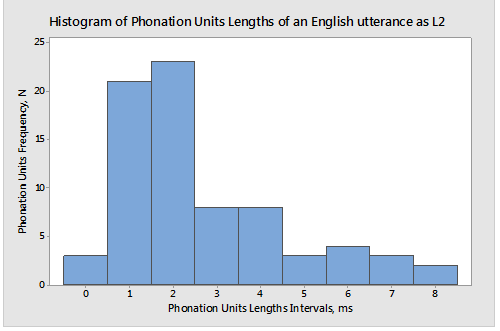
Fig. 2 — The example of the log-normal distribution of the phonation units' lengths in an utterance with a duration of 4 minutes in non-native English (p< 0.05)
The quantitative analysis has found that the total number of phonation units varies depending on the total length of the utterance. As for the range of the lengths of the individual phonation units within the utterance, it is subject to a much lesser variance, being almost identical in each particular instance and on average measuring from 200ms to 7sec, meaning that each utterance contains short, medium and long phonation units.
The same graph also shows the inverse relation between the frequency and length of the phonation units. As the most frequent units are situated on the left-hand side from the mean value and the least frequent on the right-hand side, it can be seen that the left side contains the lesser number of bins as compared to the right one containing the most part of them. The most frequent phonation units are grouped in bins 1 and 2, while the less frequent are contained in bins 5 to 8, i.e. the frequency falls as the length grows. As a result, the right-hand side of the histogram has a distinctly elongated narrowing tail demonstrating a skewness and general asymmetry typical of a log-normal distribution.
Conclusions
The identified log-normal distribution pattern for phonation units’ lengths has turned out to be valid for all the types of utterances analyzed in the experiment. This allows to conclude that the variance in the phonation units’ length values is subject to a certain universal model which is realized each time irrespective of the subject of the utterance, individual traits of the speaker, the language spoken, etc. It seems only natural to assume that the observed general applicability of this distribution pattern reflects the working of a certain intrinsic mechanism regulating the production of a spontaneous oral utterance as such, or at least its temporal structure.
More than that, as the experiment has also shown, this model is not violated by either the degree of predictability of the speech stimulus put forward to the speaker (an unexpected question from the researcher), or the amount of time provided for preparing the answer or delivering it, or the fact whether the communicative task in question was explicitly specified or merely contextually implied. There was only one common condition for all the speakers: the requirement to produce an oral monologue utterance.
Список литературы / References
- Boomer D. S., Dittmann A. T. Hesitation pauses and juncture pauses in speech // Language and Speech. - 1962. - 5.- P. 215-220.
- Christodoulides G., Avanzi M. Phonetic and Prosodic Characteristics of Disfluencies in French Spontaneous Speech // Poster presented at the 14th Conference on Laboratory Phonology 2014, July 25-27, 2014. Tokyo, Japan.
- Kristin M. R. Analysis of speech segment duration with the lognormal distribution: A basis for unification and comparison // Journal of Phonetics.- 2005.- 33(4). - P. 411–426.
- Rosen K.M., Kent R.D., Duffy J.R. Lognormal distribution of pause length in ataxic dysarthria // Clinical Linguistic Phonetics. - 2003. - 17(6). - P. 469-86.
- Sobkowicz P. et al. Lognormal distributions of user post lengths in Internet discussions - a consequence of the Weber-Fechner law? // EPJ Data Science, 2013.