ИНТЕРФОНОЛОГИЯ СОВРЕМЕННОГО ФРАНЦУЗСКОГО ЯЗЫКА: ОПЫТ РАЗРАБОТКИ РУССКОЯЗЫЧНОГО МОДУЛЯ ПРОЕКТА «IPFC»
Ратникова Е.И.
Доцент кафедры французского языка для факультета иностранных языков и регионоведения, кандидат филологических наук, Федеральное государственное бюджетное образовательное учреждение высшего образования «Московский государственный университет имени М.В.Ломоносова»
ИНТЕРФОНОЛОГИЯ СОВРЕМЕННОГО ФРАНЦУЗСКОГО ЯЗЫКА: ОПЫТ РАЗРАБОТКИ РУССКОЯЗЫЧНОГО МОДУЛЯ ПРОЕКТА «IPFC»
Аннотация
Статья посвящена одному из наиболее актуальных направлений корпусного исследования звучащей речи — интерфонологии. В работе рассматривается методика формирования русскоязычного модуля интерфонологического корпуса французского языка в рамках международного научно-исследовательского проекта «IPFC». Описывается протокол записи звучащего материала, освещаются основные подходы к составлению транскрипций и аннотации устной речи на французском языке как иностранном. Наряду с этим, обозначаются перспективы дальнейших корпусных лингвистических и психолингвистических исследований речи русскоговорящих учащихся на французском языке, в т.ч. в сопоставительном аспекте. Разработка русскоязычного модуля интерфонологического корпуса может способствовать решению прикладных задач, например, усовершенствованию компьютерных алгоритмов распознавания иноязычной речи, созданию современных обучающих программ по иностранному языку.
Ключевые слова: корпусная лингвистика, устная речь, французский язык, интерфонология, фонетика, иностранные языки.
Ratnikova E.I.
Associate Professor of the Department of French Language for the Faculty of Foreign Languages and Regional Studies, PhD in Philology, Federal State Budget Educational Institution of Higher Education “Lomonosov Moscow State University”
INTERPHONOLOGY OF MODERN FRENCH LANGUAGE: THE DEVELOPMENT OF THE RUSSIAN MODULE OF “IPFC” PROJECT
Abstract
The article is devoted to one of the most topical directions of the corpus study of the sounding speech – interphonology. The paper considers the methodology for the formation of the Russian-language module of the French language interphonological corpus within the framework of the international “IPFC” research project. The recording protocol of the sounding material is described; the main approaches to the compilation of transcripts and the annotation of oral speech in French as a foreign language are covered. Along with this, the prospects for further corpus linguistic and psycholinguistic studies of the speech of the Russian-speaking students in French are outlined, including the comparative aspect. The development of the Russian-language module of the interphonological corpus can contribute to the solution of applied problems, for example, the improvement of computer algorithms for recognizing foreign speech, as well as the creation of modern teaching programs in a foreign language.
Keywords: corpus linguistics, oral speech, the French language, interphonology, phonetics, foreign languages.
- Интерфонологические исследования речи в русле развития корпусной лингвистики
В настоящее время в лингвистических исследованиях речи все большее применение находит использование корпуса текстов [1, С. 2]. В широком смысле под лингвистическим корпусом принято понимать компьютеризированную базу данных, содержащую большой массив единиц анализа, отобранных по определенному принципу [2, С. 171]. Современный корпус может включать в себя письменные, устные тексты, а также видео, и использоваться как в собственно лингвистических, так и в дидактических целях. На сегодняшний день в рамках корпусной лингвистики создано несколько сотен корпусов текстов. Корпусы, предназначенные для анализа устной речи, широко используются в ходе изучения синтаксиса, лексики и фонетики. Из наиболее известных корпусов можно выделить корпус разговорного французского языка «DELIC», разработанный в Университете Прованса (Франция); корпус «IviE» (English Intonation in the British Isles), фиксирующий особенности интонации английского языка; национальный корпус «РАН», отражающий особенности устной разговорной речи русского языка («Рассказы о сновидениях», «Рассказы сибиряков») и ряд других корпусов.
Специализированные корпусы, направленные на изучение особенностей устной речи на иностранном языке, в частности фонетики, появились относительно недавно, например, корпус на материале голландского [3], польского [4], немецкого, английского [5] языков. Подобные корпусы, позволяющие фиксировать произношение учащихся на иностранном языке, получили название интерфонологических [6]. Интерес ученых к составлению интерфонологических корпусов обусловлен рядом причин: 1) анализ широкого круга фонетических явлений; 2) сопоставительное изучение языковых уровней; 3) анализ речи большого количества информантов (репрезентативность); 4) запись материала как в лабораторных условиях, так и в ситуации приближенной к реальному речевому общению (аутентичность); 5) контрастивные исследования на материале нескольких языков; 6) возможность многократного использования корпуса широким кругом ученых.
- Интерфонология современного французского языка — проект «IPFC»
Одним из наиболее крупных проектов на материале французского языка как иностранного является «IPFC» («InterPhonologie du Français Contemporain - «Интерфонология современного французского языка») [7, 8]. Основная цель проекта, объединившего ученых из разных стран мира, заключается в составлении интерфонологического корпуса устных текстов большого объема для решения следующих задач:
- контрастивное изучение фонетических особенностей речи учащихся-носителей различных языков на французском языке как иностранном;
- изучение фонетических особенностей речи учащихся в зависимости от типа выполняемых ими учебных упражнений;
- контрастивные исследования французского языка как родного и иностранного благодаря сопоставлению данных с фонологическим корпусом «PFC» (Phonologie du Français Contemporain - «Фонология современного французского языка»), отражающего географические, социолингвистические и стилистические особенности устной французской речи. [9, 10]
На момент написания статьи в рамках проекта «IPFC» составлены подкорпусы (модули), фиксирующие произношение немецких, испанских, японских, норвежских, португальских, турецких и других учащихся на французском языке. Проведен ряд интересных исследований, касающихся реализации фонетического связывания [11], качества гласных и согласных, в т.ч. сопоставительные исследования (например, произношения испаноговорящих и японоговорящих учащихся) [12]. Ведется разработка методики анализа и кодирования просодических характеристик речи на французском языке как иностранном.
В России активное участие в проекте с 2013 года принимает кафедра французского языка ФИЯР МГУ имени М.В.Ломоносова. В 2017 году в сотрудничестве с Женевским университетом начата работа по созданию русскоязычного модуля интерфонологического корпуса, основной задачей которого является описание фонетических трудностей, характерных для русскоязычных учащихся на французском языке как иностранном. Как и в случае других языков, формирование русскоязычного модуля осуществляется по стандартной методике проекта «IPFC», предполагающей несколько обязательных этапов:
1) запись звучащего материала по специально разработанному протоколу;
2) составление орфографической транскрипции речевого сигнала;
3) аннотация (разметка) транскрипции: а) лингвистическая; б) нелингвистическая (метаданные, комментарии);
4) кодирование языковых явлений (с использованием специального буквенно-цифрового кода в орфографической транскрипции);
5) автоматическая обработка данных (количественный и качественный анализ);
6) обеспечение хранения и доступа к звучащему материалу для широкого круга исследователей.
Кратко рассмотрим содержание указанных выше этапов, составляющих последовательность формирования русскоязычного модуля «IPFC».
2.1. Протокол записи корпуса и требования к объему модуля
Протокол записи материала в рамках «IPFC» включает в себя выполнение информантами 6 заданий:
1 задание на повторение слов за диктором
3 задания на чтение вслух
2 задания на устную речевую продукцию
+заполнение социолингвистической анкеты
Первое задание протокола представляет собой упражнение на повторение списка слов за диктором (список «IPFC»). Данный список содержит как общие фонетические трудности французского языка, характерные для всех учащихся независимо от того, какой язык является для них родным (например, носовые гласные, гласные двойного тембра и т.п.), так и специфические трудности, вызванные особенностями родного языка. В сотрудничестве с профессором И.Расин (I.Racine) в рамках создания русскоязычного модуля автором статьи в лаборатории Женевского университета список «IPFC» был дополнен новыми лексическими единицами, содержащими фонологические оппозиции и контексты, представляющие как слуховые, так и артикуляторные сложности для русскоговорящих учащихся, например, консонантные группы, сонорные перед гласными заднего ряда в ударном слоге, высокочастотные щелевые согласные и т.п. Затем доработанный список был надиктован носителем французского языка и записан в отдельный аудиофайл, ставший основой упражнения на повторение для русскоговорящих учащихся.
В ходе выполнения упражнения на повторение информанты прослушивают каждое слово дважды и повторяют его за диктором один раз. Проверяется правильность слуховой дискриминации основных фонологических оппозиций, а также качество реализации гласных и согласных звуков, их соответствие французской произносительной норме. На последующих этапах записи протокола учащимся предлагается прочитать этот же список вслух уже самостоятельно, что позволяет исследователю: 1) провести сопоставительное изучение реализации одних и тех же фонетических контекстов в ходе выполнения информантами 2-х различных упражнений (повторение/чтение); 2) зафиксировать особенности произношения, обусловленные присутствием/отсутствием визуальной опоры (орфографической транскрипции); 3) выявить основные перцептивные и артикуляторные сложности студентов на французском языке как иностранном.
Следующая часть протокола ставит задачей получение материала для проведения контрастивных исследований речи учащихся и речи носителей французского языка. Для обеспечения сопоставительной базы информанты выполняют 2 упражнения из протокола «PFC». Во-первых, информантам дается задание прочитать вслух список слов, содержащих основные фонологические оппозиции французского языка, например, «beauté-botté», «épais-épée». Затем учащиеся читают вслух текст из прессы «Le Premier Ministre ira-t-il à Beaulieu?» объемом 2 000 печатных знаков. При этом текст содержит слова из предыдущего задания, что позволяет в зависимости от цели и задач дальнейших исследований: 1) проводить сопоставительное изучение озвучивания одних и тех же фонологических оппозиций в ходе чтения информантами слов и текста; 2) оценивать успешность реализации учащимися широкого круга фонетических явлений: беглого [ə] (schwa), связывания, палатализации, ассимиляции и т.п.; 3) проводить сопоставительное изучение произношения учащихся и носителей французского языка.
Несмотря на то, что чтение текста представляет собой озвучиваемую, а не устнопорождаемую речь, выполнение данного задания позволяет судить о сформированности произносительного навыка информантов, а также степени владения просодическими средствами французского языка. В процессе чтения текста, в отличие от чтения слов, учащиеся в значительно меньшей степени контролируют фонетическую форму высказывания, что объясняется усложнением когнитивной задачи и просодической структуры озвучиваемых единиц.
Заключительная часть протокола посвящена записи речевой продукции информантов на французском языке (диалогической речи). Сначала в ходе беседы с «интервьюером» (исследователем) информант отвечает на ряд вопросов, предусмотренных протоколом, в частности, о своём социолингвистическом профиле, языковом опыте, уровне владения языком, культурных различиях между его родной и франкоговорящей страной и т.д. Затем информанту дается задание побеседовать с другим учащимся на свободную тему (о литературе, кино и т.п.). Во время записи разговора, чтобы условия общения были как можно более приближены к реальной коммуникации и говорящие чувствовали себя более уверенно и свободно, исследователь не присутствует рядом с учащимися.
До начала записи протокола информант заполняет вместе с исследователем социолингвистическую анкету, а также подписывает согласие на использование звуковых данных в дальнейших лингвистических исследованиях. Социолингвистическая анкета позволяет получить информацию о возрасте учащегося, языках которыми он владеет, образовании, объеме часов обучения французскому языку, регионе проживания, количестве времени, проведенного в стране изучаемого языка, а также данные о языковом профиле его семьи.
Таким образом, протокол «IPFC» представляет собой классический протокол записи устного корпуса, широко используемого в лингвистике и социолингвистике, охватывает достаточно большой спектр упражнений, с которыми обычно сталкиваются учащиеся в ходе изучения иностранного языка. Структура протокола отражает один из фундаментальных дидактических принципов «от простого к сложному», поэтому отдельные задания, например, повторение и чтение слов, могут быть выполнены учащимися овладевшими иностранным языком не только на продвинутом (B2-C1), но и на начальном, а также среднем уровне (A1-B1).
К настоящему моменту в рамках создания русскоязычного модуля международного интерфонологического проекта «IPFC» автором статьи была запротоколирована речь 8 информантов, с общей длительностью записи 6,5 часов. В первую группу испытуемых вошли 3 русскоговорящих учащихся Женевского университета в возрасте от 40 до 50 лет, изучающих французский язык как иностранный в этом же университете и постоянно проживающих в Швейцарии. Уровень владения языком этих информантов оценивается как B1. Все они имеют инженерные специальности, французский язык начали учить за границей во взрослом возрасте на языковых курсах, а до переезда в Щвейцарию постоянно проживали в Москве. Навыки устной речи у этих учащихся преобладают над навыками речи письменной, в т.ч. чтением. Отчасти это обусловлено методикой преподавания французского языка как иностранного в университете, а также тем, что основной целью изучения языка данной группы информантов является решение повседневных задач в реальных ситуациях общения с носителями французского языка. По наблюдениям, сделанным нами во время записи материала, можно сказать, что учащиеся этой группы охотно участвуют в беседе на французском языке, используют различные компенсаторные стратегии преодоления языковых трудностей для решения поставленной перед ними коммуникативной задачи.
Вторую группу информантов корпуса составили 5 русскоговорящих студентов в возрасте от 18 до 19 лет, обучающихся на 2-ом курсе кафедры французского языка МГУ по профилю лингвистика и межкультурная коммуникация. Отличием данной группы информантов от предыдущей стало то, что все они постоянно проживают в Москве, учат французский язык с детства, окончили специализированные школы французского языка. В университете французский язык является для этих студентов профильным, и они готовят себя к преподавательской деятельности. На момент записи корпуса уровень их владения языком оценивался как B2-B2+. При этом в ходе интервью многие информанты признались, что во время учебы в школе им не хватало практики речевого общения, а некоторые из них никогда не были во франкоязычной стране. Несмотря на то, что уровень владения языком данной группы выше уровня учащихся, проживающих в Швейцарии, в ходе записи свободной беседы некоторые информанты испытывали определенные сложности и неуверенность в общении на французском языке. Они старались не столько решить коммуникативную задачу, сколько говорить правильно и без ошибок. В случае, если им не хватало языковых средств для выражения какой-либо мысли, учащиеся предпочитали сменить тему, а не искать способы преодоления коммуникативной трудности. По-видимому, это связано как с относительно небольшим языковым опытом студентов, так и с некоторыми возрастными психологическими особенностями, которые в дальнейшем, без сомнения, будут преодолены.
На следующих этапах разработки проекта планируется увеличение объема материала русскоязычного подкорпуса, в том числе через запись большего количества информантов в соответствии с критериями статистической значимости выборки. Согласно нормам, предъявляемым к объему модуля интерфонологического корпуса, необходима запись как минимум 15 информантов. Максимальный объем корпуса при этом не ограничен.
2.2. Составление транскрипции и аннотация речевого сигнала
Следующим этапом создания модуля корпуса является составление и синхронизация транскрипции с речевым сигналом. Транскрипция — это абстрактная репрезентация речи, продукт слухового анализа, в ходе которого транскрибирующий достраивает сообщение в соответствии с собственными ожиданиями, делая выбор в пользу той или иной словоформы (например, в случае омофонии). Однако, однозначный выбор словоформы зачастую осложняется полисемичностью контекста. Особенно остро это проявляется в процессе анализа речи на иностранном языке. Как показывают исследования в данной области, при транскрибировании речи на родном языке расхождения в транскрипциях, полученных разными фонетистами, составляют в среднем 5%, а в случае иностранного языка этот показатель может достигать от 10% до 34% [13].
Поэтому транскрипция интерфонологического корпуса должна легко читаться, при этом позволяя достоверно фиксировать специфику речи на иностранном языке (выделение ошибок). В проекте «IPFC» традиционная фонетическая транскрипция не используется, что обусловлено несколькими причинами. Во-первых, составление фонетической транскрипции само по себе предполагает проведение фонетического анализа, что нежелательно на первичном этапе обработки материала, поскольку полноценные фонетические исследования должны проводиться по специально разработанным для этого критериям. Во-вторых, фонетическая транскрипция затрудняет достоверную фиксацию речи на иностранном языке из-за большой фонетической вариативности (особенно это касается качества реализуемых говорящими звуков), а также значительного количества ошибок, которые эта речь содержит. Использование символов Международного фонетического алфавита (МФА) в транскрипции требует слишком подробного и сложного анализа, что неизбежно приводит к множественной интерпретации речевого сигнала, и как следствие, к увеличению вероятности расхождений в транскрипциях разных фонетистов. Подробный фонетический анализ является к тому же и весьма ресурсозатратным, осложняя процесс создания корпуса, опирающегося на большой массив звучащих данных [14].
В рамках проекта «IPFC» разработана специальная методика, позволяющая верифицировать правильность и точность составленной транскрипции. Во-первых, каждая транскрипция проверяется несколькими специалистами (как минимум тремя). Во-вторых, сравнить транскрипции нескольких фонетистов можно с помощью программы «Dolmen», которая автоматически определит и покажет расхождения в двух файлах. Автоматическая проверка также позволяет оценить степень сформированности навыка составления транскрипции каждого фонетиста, что имеет важное значение в том случае, если в работе над корпусом принимают участие студенты (например, в ходе научно-исследовательской работы).
Составление орфографической транскрипции и ее синхронизация с речевым сигналом выполняется в программе «PRAAT». Проектом разработаны правила транскрибирования каждого типа заданий протокола, а также даны рекомендации по разметке транскрипции, облегчающие ее дальнейший анализ, например, выделение реплик собеседников в интервью и свободной беседе. Большое внимание уделяется и аннотации ряда явлений, характерных для устной речи: неразборчивое произнесение слогов, ономатопеи, хезитации, смех, шум, наложение реплик говорящих и т.п.
Подробные правила аннотации разработаны и для различного рода ошибок в речи учащихся. Как было сказано ранее, фонетические ошибки в орфографической транскрипции не указываются. Однако, у составителя транскрипции есть возможность создать в «PRAAT» дополнительную графу (tier) «Комментарии» и указать в ней ту фонетическую ошибку, которая, по его мнению, может представлять интерес для последующих фонетических исследований. Аннотация ошибки осуществляется с помощью символов алфавита «SAMPA». Данный алфавит распознается компьютерными программами «PRAAT» и «Dolmen», используемыми в проекте для анализа и обработки материала. На Рис.1 в графе №3 «commentaires» представлен пример фиксации фонетической ошибки в слове «signal», произнесенного русскоговорящим учащимся как [signal] (вместо [siɲal]).
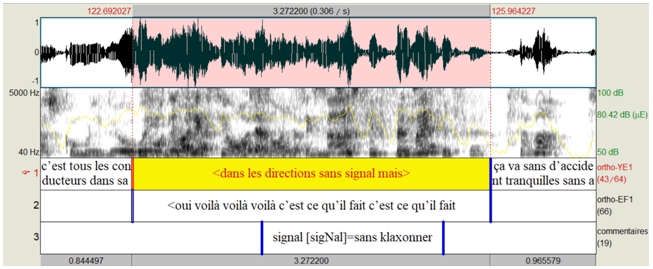
Рис. 1 – Фрагмент транскрипции и аннотации диалогической речи русскоговорящих учащихся в «PRAAT» в рамках проекта «IPFC»
Что касается других отклонений в речи учащихся, обусловленных как языковой интерференцией, так и речевыми сбоями, то все они обязательно указываются в транскрипции: грамматические и лексические ошибки, фальстарты, оговорки, самоисправления и т.п. В качестве примера фиксации грамматических и лексических ошибок можно привести тот же «signal» (см. Рис.1, графа 1). Говорящий употребляет существительное «signal» вместо глагола «signaler», неправильно выбирая при этом саму лексему, корневая морфема которой совпадает со схожим по звучанию словом в русском языке, но имеет при этом другое значение (правильно «klaxonner» (сигналить). Таким образом, в данном примере реализация одного слова говорящим является источником ошибок сразу нескольких языковых уровней, что представляет интерес для комплексного изучения языковой интерференции на иностранном языке.
2.3. Фонетический анализ корпуса — использование кода в транскрипции
В «IPFC» используется перцептивный подход к фонетическому анализу речи, который в зависимости от целей конкретного исследования может быть дополнен акустическим анализом. В ходе слухового анализа осуществляется кодирование фонетических явлений в орфографической транскрипции с помощью специального буквенно-цифрового кода [15]. Код нужен для того, чтобы специальная программа (конкорданс) могла производить автоматическую обработку полученных данных, а также их сопоставительный анализ в ходе выполнения информантом разных упражнений протокола (например, реализацию носовых гласных в ходе повторения и чтения списка слов).
Код позволяет фиксировать контекст интересующего исследователя фонетического явления, его качественные характеристики и имеет следующий вид в транскрипции (на примере анализа носовых гласных):
«ses chemises en11_2F_20F_1_10_10 soie»
Шестизначный код можно условно разделить на две части: первые три элемента описывают контекст реализации носового гласного, а последние три — качество реализации звука говорящим и его соответствие фонетической норме французского языка. Первый элемент кода 11 обозначает звук, который должен быть произнесен говорящим (носовой [ã]), второй элемент 2F — левый фонетический контекст гласного, т.е. в данном примере реализация носового после щелевого звука [z] в «chemises», 20F — правый контекст: реализация носового перед щелевым [s] (soie). Четвертый и пятый элементы говорят о том, что у анализируемого гласного присутствует носовой тембр, что реализован именно [ã], а не какой-либо другой носовой звук (например, [õ]), а шестой элемент указывает на отсутствие призвука согласного [n] (более подробно о кодировании носовых гласных см. [16]). Таким образом, в рассматриваемом примере говорящий произносит носовой [ã] правильно. По аналогичному принципу разработаны кодировки, позволяющие осуществлять фонетический анализ ртовых и носовых гласных, согласных, фонетического связывания, беглого [ə] (schwa).
2.4. Автоматическая обработка данных фонетического анализа
Автоматическая обработка и количественный анализ данных осуществляются в специальной программе-конкордансе «Dolmen» [17]. Программа позволяет осуществлять быстрый поиск нужного явления или фонетического контекста в транскрипциях, а также прослушивать соответствующий транскрипции звуковой фрагмент. Например, на Рис.2 представлены результаты поиска в «Dolmen» всех случаев реализации носового гласного [ɛ̃] в ходе чтения текста из протокола «IPFC» русскоговорящим учащимся. Пятый элемент кода показывает, что из 19 случаев реализации звука [ɛ̃] только в 6 случаях этот звук произнесен говорящим корректно, тогда как в 10 случаях наблюдается замена звука [ɛ̃] на носовую гласную [ã], а в 3-х случаях на гласную, тембр которой невозможно установить в ходе перцептивного анализа (что, вероятно, указывает на редукцию или дифтонгизацию звука). Таким образом, использование конкорданса позволяет проводить быстрый поиск и первичную обработку материала. Результаты поиска могут быть экспортированы в «Excel» для более подробного качественного и количественного анализа. Не останавливаясь подробно на описании всех возможностей программы «Dolmen», отметим, что она может также использоваться для редактирования орфографической транскрипции и кодировок.

Рис. 2 – Результаты поиска в конкордансе «Dolmen» всех случаев реализации носового гласного [ɛ̃] в ходе чтения текста из протокола «IPFC» русскоговорящим учащимся
Несмотря на то, что работа над созданием русскоязычного модуля интерфонологического корпуса «IPFC» только началась, нами получен достаточно интересный и разнообразный материал. Первые сделанные транскрипции и кодировки звучащего материала подтверждают надежность применения протокола «IPFC» к записи и анализу речи русскоговорящих учащихся на французском языке. Протоколы кодировок позволяют исследователю проводить корректную и исчерпывающую аннотацию таких часто встречающихся фонетических явлений в речи русскоговорящих учащихся как палатализация, веляризация согласных, некорректная реализация полугласных и ряда других явлений.
2.5. Хранение и предоставление материала другим исследователям
Как указано на сайте проекта «IPFC» [18], на следующих стадиях его развития планируется предоставление онлайн конкорданса широкому кругу специалистов с возможностью поиска нужных фонетических явлений по ключевым словам, социолингвистическому профилю дикторов и другим параметрам, что позволит значительно сократить время на запись, обработку и первичный анализ материала.
- Практическая значимость интерфонологического корпуса
Составление интерфонологического корпуса текстов в рамках проекта «IPFC» открывает широкие перспективы для дальнейшего исследования речи русскоговорящих учащихся на французском языке. Базируясь на обширном массиве статистически значимых данных, данный корпус целиком соответствует современным требованиям к репрезентативности и аутентичности исходного материала. В первую очередь корпус имеет значение для создания исчерпывающих классификаций и типологии фонетических ошибок изучающих французский язык, но также может найти применение при исследовании других языковых уровней (лексического, грамматического, семантического).
Ценность системного подхода к анализу материала в рамках проекта заключается в том, что исследователь имеет возможность в ходе сопоставительного изучения ошибок устанавливать связь между типом ошибки и упражнением, выполняемым информантом, а также обнаруживать корреляцию ошибки с формой устной речи (озвученной или устнопорождаемой). Протокол «IPFC» включает в себя практически все основные упражнения, с которыми сталкиваются учащиеся во время обучения фонетике, а также устной речевой продукции. Тип ошибок, по-видимому, может позволить сделать выводы и о психолингвистической составляющей каждого типа упражнения (в частности, степени контроля фонетического компонента речи), а также степени влияния письменной опоры на произношение. Так, первые исследования, выполненные в рамках проекта на материале испаноговорящих учащихся подтверждают тот факт, что количество фонетических ошибок в процессе чтения слов вслух значительно (в соотношении 79,93% к 21,35%) превышает количество ошибок, допущенных учащимися в ходе повторении списка слов за диктором без визуальной опоры [19]. Эти данные находят подтверждение и на материале русскоговорящих учащихся: во время чтения списка слов наблюдается явление гиперкоррекции согласных в ударном слоге закрытого типа, тогда как в ходе упражнения на повторение данное явление в аналогичном фонетическом контексте практически отсутствует [20].
Универсальность протокола записи корпуса и методики обработки звучащего материала позволяют проводить сопоставительные исследования речи учащихся-носителей различных языков на французском языке и выявлять как специфические сложности, обусловленные интерференцией родного языка, так и общие трудности, характерные для всех изучающих французский язык. Наряду с этим, включение в протокол ряда заданий из проекта «PFC» предоставляет возможность проведения контрастивных исследований речи. Большой интерес вызывает и изучение взаимодействия говорящих в ходе беседы на иностранном языке (структурирование диалогической речи), анализ их стратегий для решения поставленных коммуникативных задач.
Инструментарий интерфонологического корпуса имеет также неоспоримую ценность и для изучения процессов освоения, восприятия и порождения речи на иностранном языке, как в синхронии, так и в диахронии. Дополнительная запись речи информантов по прошествии определенного времени, например, даёт ценные данные о динамике формирования языковой и коммуникативной компетенций. Это, в свою очередь, может стать основой для уточнения требований, предъявляемых к владению французским языком как иностранным по Общеевропейской шкале компетенций, особенно в том, что касается произносительной нормы учащихся на каждом уровне обучения.
Не меньшей представляется роль интерфонологического корпуса и в дидактическом аспекте. Наши наблюдения показывают, что вовлечение студентов в процесс создания корпуса позволяет не только ознакомить учащихся с основными подходами и принципами корпусной лингвистики, закрепить на практике материал из курса теоретической фонетики, но и сформировать у студентов навык самостоятельной научно-исследовательской работы с привлечением современных инструментов записи и анализа звучащей речи.
Не вызывает сомнения и актуальность использования корпуса «IPFC» для решения многих прикладных задач, в частности, создания компьютерных алгоритмов распознавания речи на иностранном языке, которые находят всё более широкое применение при разработке современных интерактивных обучающих программ по фонетике, а также автоматическому оцениванию ответов студентов на устных экзаменах по иностранному языку (в т.ч. оценка правильности чтения текста вслух). Наряду с этим, создание перцептивных моделей может способствовать усовершенствованию программ автоматического транскрибирования иноязычной речи. На сегодняшний день подобные программы достаточно успешно составляют транскрипции озвучиваемой речи, тогда как существующие алгоритмы транскрибирования устнопорождаемой речи, и тем более речи на иностранном языке, требуют существенной доработки. Таким образом, интерфонологический корпус может лечь в основу создания не только традиционных учебных пособий и корректирующих упражнений по фонетике, но и современных обучающих компьютерных программ, способствующих повышению эффективности процесса обучения иностранным языкам, а также оптимизации инструментального анализа речи.
Список литературы / References
- Durand J., Gut U., Kristoffersen G. The Oxford Handbook of Corpus Phonology. – Oxford: Oxford University Press, 2014. – 680 p.
- Sinclair J. Corpus, Concordance, Collocation. – Oxford: Oxford University Press, 1991. – 179 p.
- Neri A., Cucchiarini C., Strik H. Selecting segmental errors in non-native Dutch for optimal pronunciation training // IRAL - International Review of Applied Linguistics in Language Teaching (43), 2006, pp.357-404.
- Cylwik N., Wagner A., Demenko G. The EURONOUNCE corpus of non-native Polish for ASR-based Pronunciation Tutoring System // Proceedings of SlaTE 2009 – 2009 ISCA Workshop on Speech and Language Technology in Education, Birmingham, UK, 2009.
- Gut U. Non-native Speech : A Corpus-based Analysis of Phonological and Phonetic Properties of L2 English and German. – Wien, Peter Lang, 2009. – 354 p.
- Detey S., Kawaguchi Y. Interphonologie du Français Contemporain (IPFC) : récolte automatisée des données et apprenants japonais // Journées PFC : Phonologie du français contemporain : variation, interfaces, cognition, Paris, 11-13 décembre, 2008.
- Detey S., Racine I., Kawaguchi Y., Zay F. Variation among non-native speakers: the InterPhonology of Contemporary French // Varieties of Spoken French. – Oxford: Oxford University Press, 2016. – 491-502 p.
- Racine I., Detey S., Zay F., Kawaguchi, Y. Des atouts d’un corpus multitâches pour l’étude de la phonologie en L2 : l’exemple du projet « Interphonologie du français contemporain » (IPFC) // Recherches récentes en FLE. Berne : Peter Lang, pp. 1-19, 2012.
- Durand J., Laks B., Lyche C. La phonologie du français contemporain: usages, variétés et structure // Romance Corpus Linguistics - Corpora and Spoken Language. Tübingen: Gunter Narr Verlag, pp. 93-106, 2002.
- Durand J., Laks B., Lyche C. Le projet PFC: une source de données primaires structurées // Phonologie, variation et accents du français. Paris: Hermès, 2009, pp. 19-61.
- Racine I., Detey S. L'apprentissage de la liaison en français par des locuteurs non natifs: éclairage des corpus oraux // Bulletin VALS-ASLA 102, 2015.
- Racine I., Detey S., Buehler N., Schwab S., Zay F., Kawaguchi Y. The production of French nasal vowels by advanced Japanese and Spanish learners of French: a corpus-based evaluation study // Proceedings of New Sounds2010, Poznan: Adam Mickiewicz University, 2010, pp. 367-372.
- Zechner K. What did they actually say? Agreement and Disagreement among Transcribers of Non-Native Spontaneous Speech Responses in an English Proficiency Test. // Proceedings of the ISCA SLaTE-2009 Workshop, September, 2009, pp. 25-28.
- Racine I., Zay F., Detey S., Kawaguchi, Y. De la transcription de corpus à l’analyse interphonologiques : enjeux méthodologiques en FLE // Travaux Linguistiques du CerLiCO 24 (Actes du 24ème colloque du CERLICO « Transcrire, écrire, formaliser», Université de Tours, juin 2010). Rennes : PUR, 2011, pp. 13-30.
- Detey S. Coding an L2 phonological corpus: from perceptual assessment to non-native speech models–an illustration with French nasal vowels // Tono. Y., Kawaguchi, Y.& Minegishi, M. (eds), Developmental and Crosslinguistic Perspectives in Learner Corpus Research. Amsterdam: John Benjamins, 2012, pp. 229–250.
- Detey S., Racine I., Kawaguchi Y. Des modèles prescriptifs à la variabilité des performances non-natives : les voyelles nasales des apprenants japonais et espagnols dans le projet IPFC // La phonologie du français : normes, périphéries, modélisation. Hommage à Chantal Lyche. Paris: PUPO, 2014, pp. 197-226.
- Eychenne J., Paternostro R. Analyzing transcribed speech with Dolmen // Varieties of Spoken French, Oxford: Oxford University Press, 2016, pp.35-52.
- http://cblle.tufs.ac.jp/ipfc/index.php?id=88
- Detey S., Racine I., Kawaguchi Y. Assessing non-native speakers’ production of French nasal vowels: a multitask corpus-based study // Working Papers in Corpus-based Linguistics and Language Education 5, Tokyo: Tokyo University of Foreign Studies, 2010, pp.277-293.
- Ratnikova E. Comment la graphie influence-t-elle la prononciation en L2 ? Etude de cas des apprenants russes du français // Rencontres FLORAL - Français Langue ORAle et Linguistique, Paris, 8-9 décembre, 2014.
Список литературы на английском языке / References in English
- Durand J., Gut U., Kristoffersen G. The Oxford Handbook of Corpus Phonology. – Oxford: Oxford University Press, 2014. – 680 p.
- Sinclair J. Corpus, Concordance, Collocation. – Oxford: Oxford University Press, 1991. – 179 p.
- Neri A., Cucchiarini C., Strik H. Selecting segmental errors in non-native Dutch for optimal pronunciation training // IRAL - International Review of Applied Linguistics in Language Teaching (43), 2006, pp.357-404.
- Cylwik N., Wagner A., Demenko G. The EURONOUNCE corpus of non-native Polish for ASR-based Pronunciation Tutoring System // Proceedings of SlaTE 2009 – 2009 ISCA Workshop on Speech and Language Technology in Education, Birmingham, UK, 2009.
- Gut U. Non-native Speech : A Corpus-based Analysis of Phonological and Phonetic Properties of L2 English and German. – Wien, Peter Lang, 2009. – 354 p.
- Detey S., Kawaguchi Y. Interphonology of Contemporary French (IPFC): automated collection of data for Japanese Learners // PFC Days : Phonology of Contemporary French : variation, interfaces, cognition, Paris, 11-13 December, 2008. [In French]
- Detey S., Racine I., Kawaguchi Y., Zay F. Variation among non-native speakers: the InterPhonology of Contemporary French // Varieties of Spoken French. – Oxford: Oxford University Press, 2016. – 491-502 p.
- Racine I., Detey S., Zay F., Kawaguchi, Y. Advantages of a multitask corpora for studying L2 phonology: an example of the project “Interphonology of Contemporary French (IPFC)” // Recent research in FFL. Berne : Peter Lang, pp. 1-19, 2012. [In French]
- Durand J., Laks B., Lyche C. Phonology of Contemporary French: usages, varieties and structure // Romance Corpus Linguistics - Corpora and Spoken Language. Tübingen: Gunter Narr Verlag, pp. 93-106, 2002. [In French]
- Durand J., Laks B., Lyche C. PFC project: a source of primary structured data // Phonology, variation and accents of French. Paris: Hermès, 2009, pp. 19-61. [In French]
- Racine I., Detey S. French liaison learning by non-native speakers in the light of oral corpora // Bulletin VALS-ASLA 102, 2015. [In French]
- Racine I., Detey S., Buehler N., Schwab S., Zay F., Kawaguchi Y. The production of French nasal vowels by advanced Japanese and Spanish learners of French: a corpus-based evaluation study // Proceedings of New Sounds 2010, Poznan: Adam Mickiewicz University, 2010, pp. 367-372.
- Zechner K. What did they actually say? Agreement and Disagreement among Transcribers of Non-Native Spontaneous Speech Responses in an English Proficiency Test. // Proceedings of the ISCA SLaTE-2009 Workshop, September, 2009, pp. 25-28.
- Racine I., Zay F., Detey S., Kawaguchi, Y. From corpus transcription to interphonological analysis: methodological challenges // Linguistic papers of CerLiCO 24 (Proceedings of 24th colloquium of CERLICO « Transcribe, write, formalize», Tours University, June 2010). Rennes : PUR, 2011, pp. 13-30. [In French]
- Detey S. Coding an L2 phonological corpus: from perceptual assessment to non-native speech models – an illustration with French nasal vowels // Tono. Y., Kawaguchi, Y.& Minegishi, M. (eds), Developmental and Crosslinguistic Perspectives in Learner Corpus Research. Amsterdam: John Benjamins, 2012, pp. 229–250.
- Detey S., Racine I., Kawaguchi Y. From prescription models to variability of non-native performances: nasal vowels of Japanese and Spanish learners in IPFC project// French phonology: norms, peripheries, modeling. Hommage to Chantal Lyche. Paris: PUPO, 2014, pp. 197-226. [In French]
- Eychenne J., Paternostro R. Analyzing transcribed speech with Dolmen // Varieties of Spoken French, Oxford: Oxford University Press, 2016, pp.35-52.
- http://cblle.tufs.ac.jp/ipfc/index.php?id=88
- Detey S., Racine I., Kawaguchi Y. Assessing non-native speakers’ production of French nasal vowels: a multitask corpus-based study // Working Papers in Corpus-based Linguistics and Language Education 5, Tokyo: Tokyo University of Foreign Studies, 2010, pp.277-293.
- Ratnikova E. How does a visual support affect L2 pronunciation? A case of Russian speaking students learning French // FLORAL workshop – French Language ORAle and Linguistics, Paris, 8-9 December, 2014. [In French]