Effectiveness of using different spectral features for emotion classification using a convolutional neural network
Effectiveness of using different spectral features for emotion classification using a convolutional neural network
Abstract
Emotion classification in spoken language has attracted considerable attention in recent years due to its application in virtual assistants, training and sentiment analysis. Despite the successes in English-language studies, Russian-language data such as Dusha and RESD remain understudied. This research analyses spectral features (MFCC, fine spectrogram, chromagram, spectral contrast) for emotion classification using convolutional neural network. Experiments on the datasets showed the highest accuracy using fine spectrograms. For the RAVDESS dataset, the accuracy was 78%, for Dusha 62%, and for RESD 73%. Combining features did not improve the results. Current methods such as self-learning and transformers are efficient but resource demanding. A simplified neural network model for performance constrained devices is proposed, which extends its application to smartphones, smartwatches and smart home systems, providing high accuracy with low power consumption.
1. Введение
В последние годы классификация эмоций в разговорной речи получила значительное внимание со стороны исследователей, поскольку она находит широкое применение в различных областях, включая виртуальных ассистентов, системы обучения и анализа потребительских настроений. Несмотря на существенные успехи в этой области, большинство исследований проводилось на англоязычных данных, что оставляет заметный пробел в применении этих технологий к русскоязычным данным.
Анализ и интерпретация эмоций является сложной задачей
как для человека, так и для компьютера. Поскольку речь является основным средством общения между людьми, системы аффективных вычислений, способные распознавать эмоции, занимают важное место в развитии взаимодействия человека и компьютера. Однако точное определение эмоций представляет значительную сложность из-за их многообразной природы и способов выражения.Эмоциональное состояние человека предоставляет важные данные о его здоровье и психическом благополучии. Например, изменения в эмоциональном состоянии, вызванные болезнью Паркинсона, могут быть выявлены через анализ мимики, речи и ЭЭГ-сигналов
, , , .Развитие искусственного интеллекта стимулирует создание систем, моделирующих человеческое поведение, но многие современные виртуальные помощники игнорируют эмоциональные аспекты, полагаясь только на транскрипцию речи.
Большая часть исследований в области распознавания эмоций основана на анализе эмоциональной составляющей по расшифрованному тексту, что неудивительно, так как анализ настроений в письменном виде сопровождается значительно большим объемом работ
по сравнению с необработанным аудио. Исследователи достигли высокой точности на таких наборах данных, как Yelp и IMDb. К сожалению, транскрипция не учитывает множество характеристик, присутствующих в аудио.Для развития систем классификации эмоций в русскоязычном сегменте были созданы специализированные наборы данных, такие как Dusha и RESD, которые позволяют исследователям проводить эксперименты и разрабатывать алгоритмы для распознавания эмоций в русскоязычной речи. Набор данных Dusha, разработанный компанией SberDevices, является на данный момент крупнейшим ресурсом такого рода на русском языке
. Он состоит из двух частей: первая часть, названная Crowd, включает тексты, созданные на основе реальных диалогов с виртуальным ассистентом, которые затем озвучивались. Вторая часть, Podcast, содержит короткие фрагменты из русскоязычных подкастов, которые были классифицированы по эмоциональным категориям. Весь датасет включает около 300 тысяч аудиозаписей общей продолжительностью примерно 350 часов и охватывает пять классов эмоций: гнев, грусть, позитив, нейтральная эмоция и прочее.Другой значимый набор данных, Russian EmotionalSpeechDialogs (RESD), представлен в открытой библиотеке Aniemore и предназначен для анализа эмоциональной окраски разговорной и письменной речи
. В этом датасете записи диалогов с заранее заданными эмоциями были озвучены профессиональными актёрами. Он включает около 1400 аудиозаписей общей продолжительностью примерно 4 часа и классифицирует эмоции на семь категорий: нейтральная, гнев, энтузиазм, страх, грусть, радость и отвращение.Также был использован популярный набор данных Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS). В этот набор входят 1440 аудиофайлов, записанных с участием 24 профессиональных актеров (12 мужчин и 12 женщин), которые произносили два одинаковых высказывания с нейтральным североамериканским акцентом. Каждый актер воспроизводил фразы, выражая восемь различных эмоций с разной степенью интенсивности: спокойствие, радость, печаль, гнев, страх, удивление, отвращение и нейтральность. Этот набор данных был сбалансирован, выделяя шесть основных эмоций: гнев, отвращение, страх, радость, печаль и нейтральность
. Количество аудиофайлов составило 1152, что соответствует среднему количеству файлов в 196 для каждого класса эмоций. Также аудиофайлы были приведены к частоте дискретизации 16кГц.2. Обзор современных технологий классификации эмоций
В последние годы значительное внимание привлекает метод самообучения (Self-Supervised Learning, SSL), ставший ведущим в обработке данных. Этот метод позволяет алгоритмам автоматически обнаруживать закономерности в исходных данных, значительно улучшая результаты анализа. Важную роль в успехе SSL сыграло развитие архитектуры трансформеров, которая, в отличие от традиционных нейронных сетей, обеспечивает параллельную обработку больших объемов данных, ускоряя процесс обучения. Это позволило использовать огромные объемы интернет-данных для создания моделей, которые демонстрируют высокую эффективность даже с минимальной доработкой на специализированных наборах данных
.Одной из самых известных моделей самообучения, созданных на основе архитектуры трансформеров, является BERT, разработанный компанией Google для обработки письменного текста. BERT широко используется в различных приложениях, таких как обработка запросов в поисковых системах. Однако для задач, связанных с обработкой звуковой речи, BERT не столь эффективен. Это связано с необходимостью предварительной токенизации звуковых данных, что может вносить шум и снижать качество анализа. Для обработки разговорной речи были разработаны специализированные модели, такие как Wav2vec 2.0, HuBERT и WavLM
, , . Эти модели работают напрямую с необработанными аудиозаписями, разбивая их на короткие фрагменты и обучаясь предсказывать скрытые части записи, что позволяет получать качественные представления аудиоданных без необходимости их предварительной разметки.Тем не менее, авторы данной работы предлагают упрощенную версию нейросетевого классификатора, рассчитанного на внедрение в устройства с ограниченной производительностью.
Это существенно расширит спектр устройств для применения данной модели, например:
- устройства, такие как смартфоны, умные часы и фитнес-браслеты, часто имеют ограниченные вычислительные ресурсы. Упрощенная нейросетевая модель может быть эффективно использована для распознавания эмоций на таких устройствах, улучшая пользовательский опыт без значительного увеличения энергопотребления;
- в системе умного дома или умного офиса устройства с ограниченной вычислительной мощностью могут использовать данный классификатор для распознавания эмоций и адаптации окружающей среды (например, освещения или температуры) в зависимости от настроения пользователя;
- в образовательных приложениях, таких как интерактивные учебники или виртуальные помощники, распознавание эмоций может улучшить взаимодействие с учащимися, предоставляя более персонализированную помощь. В медицинских приложениях такая модель может помочь в мониторинге психоэмоционального состояния пациентов.
Если проводить сравнение предлагаемого подхода с существующими методами классификации эмоциональной составляющей в аудиоданных, то можно выделить следующее:
- трансформеры (например, BERT, Wav2vec 2.0) обеспечивают высокую точность за счет обработки больших объемов данных параллельно. Однако они требуют значительных вычислительных ресурсов и памяти, что ограничивает их применение на устройствах с ограниченными ресурсами;
- классические модели машинного обучения, такие как SVM и деревья решений, также могут быть применены для распознавания эмоций, но они часто требуют тщательной настройки и предварительной обработки данных. Упрощенные нейросетевые модели могут предложить более высокую гибкость и способность к обучению на разнообразных данных;
- глубокие нейронные сети (DNN) предлагают высокую точность и способность обрабатывать сложные данные, но они также требуют значительных вычислительных ресурсов.
В целом, упрощенная версия нейросетевого классификатора предлагает компромисс между точностью и вычислительной эффективностью. Упрощенные модели могут быть легко адаптированы и переобучены на новых данных, что позволяет быстро интегрировать их в новые приложения или устройства. За счет снижения требований к вычислительным ресурсам, предложенная модель может быть внедрена в устройства с ограниченной производительностью, не снижая при этом качество распознавания эмоций. Уменьшение сложности модели способствует снижению энергопотребления, что особенно важно для носимых устройств и IoT. Модель может быть адаптирована для различных задач и настроек, что делает ее универсальным инструментом для распознавания эмоций в различных приложениях.
3. Анализ спектральных признаков и их визуализация
В контексте задачи распознавания эмоций по аудиоданным можно выделить несколько спектральных признаков, используемых для анализа. Одними из наиболее распространенных являются мел-спектрограммы и мел-частотные кепстральные коэффициенты (MFCC). В более редких случаях используются хромограммы и спектральный контраст. Цель данного исследования состоит в сравнении эффективности этих признаков при использовании их для обучения сверточной нейронной сети (CNN).
Мел-спектрограмма представляет собой графическое изображение частотного спектра сигнала, изменяющегося во времени, которое широко применяется для анализа речи
, . Каждый участок сигнала представлен вертикальной линией на графике, отображающей амплитуду в зависимости от частоты в конкретный момент времени. Цветовая шкала используется для отображения амплитуды частот. График мел-спектрограммы аудио-фрагмента из применяемого набора данных представлен на рисунке 1 слева.MFCC представляет собой кратковременное спектральное представление мощности звука, основанное на линейном косинусном преобразовании логарифмического спектра мощности, измеренного по нелинейной шкале частот мела. График MFCC представляет собой визуализацию временной зависимости коэффициентов MFCC, используемых для анализа аудиосигнала. На горизонтальной оси отображается время, на вертикальной оси – номера коэффициентов MFCC. Используя цветовую шкалу, график показывает интенсивность каждого коэффициента в децибелах: чем ярче цвет, тем выше значение коэффициента, отражающее магнитуду коэффициента. Спектральные признаки MFCC представлены на рисунке 1 справа.
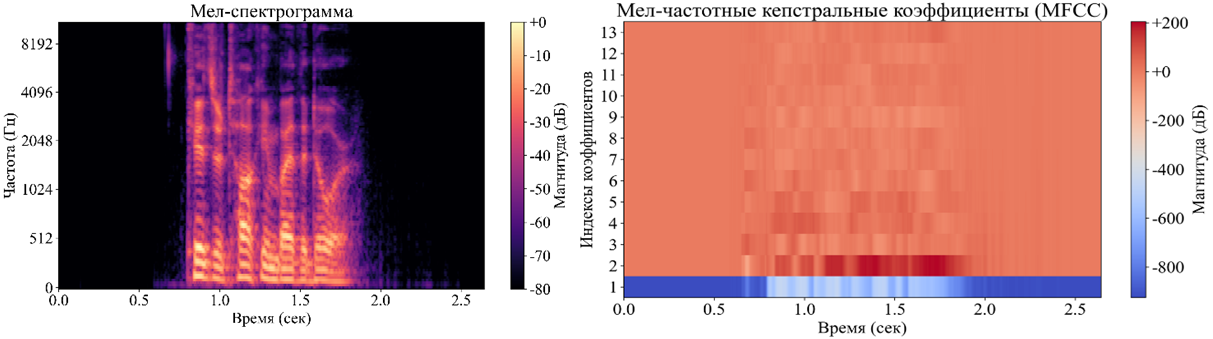
Рисунок 1 - Мел-спектрограмма аудиосигнала (слева), MFCC аудиосигнала (справа)
1. Метод, использующий кратковременное преобразование Фурье (STFT) для расчета хромаграммы, который обеспечивает высокое временное разрешение. Это полезно для анализа быстропеременных музыкальных структур. Хромаграмма, построенная с использованием STFT, позволяет детально рассматривать изменения в интенсивности нот во времени. Назовем его ChromaSTFT.
2. Метод, основанный на постоянной Q-преобразовании (Constant-Q Transform, CQT), который позволяет лучше захватывать музыкальные свойства сигнала за счет логарифмически равномерного распределения частотных полос, соответствующих музыкальным нотам. Это делает его особенно полезным для анализа гармонических и мелодических содержаний. Назовем его ChromaCQT.
3. Метод, который использует вариативное Q-преобразование (Variable-Q Transform, VQT), являющееся обобщением постоянной Q-преобразования (CQT). VQT позволяет динамически изменять разрешение в зависимости от частоты, обеспечивая более гибкое и точное представление частотных компонентов музыкального сигнала. Назовем его ChromaVQT.
4. Метод, который использует энергонезависимые хроматические признаки (Chroma Energy NormalizedStatistics, CENS). Этот метод включает дополнительные шаги нормализации и сглаживания, что делает его устойчивым к динамическим изменениям в аудиосигнале и более надежным для задач классификации и сравнения музыкальных фрагментов. Назовем его ChromaCENS.
На графике хромаграммы ось абсцисс представляет время в секундах, ось ординат обозначает 12 хроматических нотили классов высоты тона, цветовая шкала указывает интенсивность каждой ноты. Графики STFT и CENS приведены на рисунке 2. Графики CQT и VQT, приведены на рисунке 3.
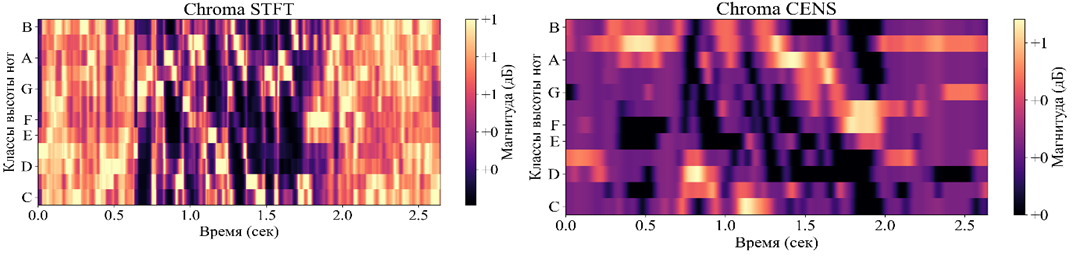
Рисунок 2 - Графики STFT, CENS для аудиосигнала
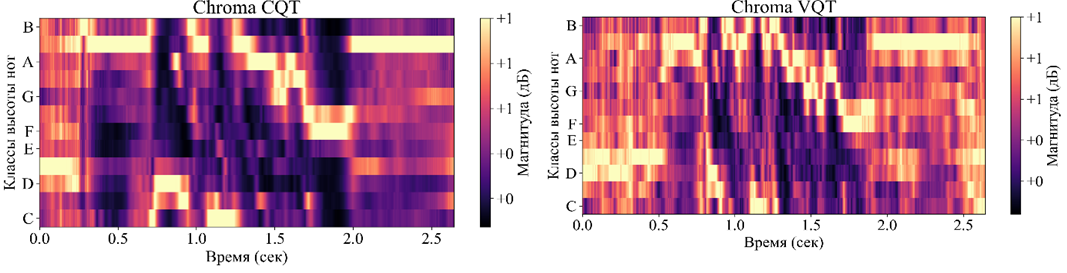
Рисунок 3 - Графики CQT, VQT для аудиосигнала
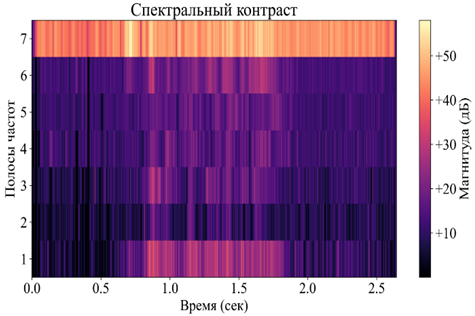
Рисунок 4 - Спектральный контраст аудиосигнала
4. Модель сверточного классификатора
Для проведения классификации эмоциональной окраски аудио фрагментов на основе извлеченных признаков, была разработана модель сверточной нейронной сети, которая представлена на рисунке 5.
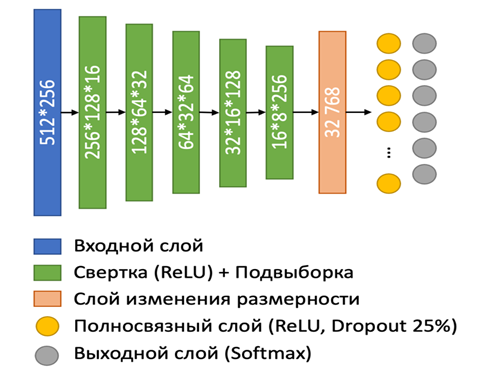
Рисунок 5 - Модель сверточного классификатора
Сверточные слои выполняют функцию извлечения основных характеристик из входного изображения путем применения фильтров. Сверточные операции помогают выделить важные особенности, такие как края, углы и текстуры. Размер фильтров составляет 3x3, с использованием шага (stride) 1 для перемещения фильтра по изображению и padding 1 для сохранения размеров карты признаков.
Слои подвыборки выполняют функцию уменьшения размеров карт признаков для снижения вычислительной сложности и предотвращения переобучения. Они используют операции максимальной подвыборки с окном, 2x2, для уменьшения размерности карт признаков.
Полносвязные слои преобразуют двумерные карты признаков в один вектор признаков для последующей классификации. Каждый нейрон в полносвязном слое соединен с каждым нейроном предыдущего слоя, что позволяет объединить все выявленные признаки и выполнить классификацию.
Слой регуляризации (Dropout Layer) предотвращает переобучение за счет случайного отключения некоторых нейронов во время обучения. Определенный процент нейронов (25%) отключается на каждой итерации обучения, что способствует обобщению модели.
Выходной слой осуществляет классификацию входного изображения по одному из возможных классов. Применяется функция активации softmax для получения вероятностей принадлежности к каждому классу. Количество нейронов на выходном слое равно количеству классов для классификации (в данном случае, 6 классов эмоций).
5. Результаты исследований
Для оценки эффективности классификации эмоций с использованием различных спектральных признаков применялись изображения размером 256 на 512 пикселей. Нейронная сеть обучалась на каждом спектральном признаке в течение 200 эпох с размером пакета 32. Результаты классификации, достигнутые каждой моделью, приведены в таблице 1.
Таблица 1 - Результаты распознавания эмоций с применением различных спектральных признаков
Спектральный признак | RAVDESS, % | RESD, % | Dusha, % |
Мел-спектрограмма | 78 | 73 | 62 |
MFCC | 75 | 70 | 58 |
Chroma STFT | 55 | 50 | 44 |
Chroma CQT | 55 | 50 | 44 |
Chroma VQT | 60 | 57 | 49 |
Chroma CENS | 51 | 48 | 39 |
Спектральный контраст | 52 | 49 | 37 |
Анализ данных выявил, что наилучшие результаты были достигнуты при использовании мел-спектрограмм и MFCC, демонстрируя точность 78% и 75% соответственно, что подтверждается в статье . Среди хромаграмм наибольшую точность показала Chroma VQT, достигнув 60%.
В работе авторы отмечают положительное влияние использования мел-спектрограмм с MFCC и других спектральных признаков для улучшения классификации эмоций. В данном исследовании комбинация различных признаков путем добавления их в модель в качестве отдельных каналов не дала значительного прироста точности. Наибольшая точность для комбинаций признаков (69%) была достигнута при использовании изображений мел-спектрограмм, MFCC и Chroma VQT, что не превосходит результаты, полученные при использовании только мел-спектрограмм или MFCC. Похожей точности достигла модель, которая дополнительно содержала изображения спектрального контраста. Результаты классификации с использованием комбинации признаков, достигнутые каждой моделью, приведены в таблице 2.
Таблица 2 - Результаты распознавания эмоций с применением комбинаций спектральных признаков
Спектральный признак | RAVDESS, % | RESD, % | Dusha, % |
Мел-спектрограмма, MFCC | 65 | 61 | 48 |
Мел-спектрограмма, MFCC, ChromaVQT | 69 | 65 | 51 |
Мел-спектрограмма, MFCC, ChromaVQT, Спектральный контраст | 68 | 63 | 49 |
6. Заключение
Мел-спектрограммы и MFCC продемонстрировали наилучшие результаты в классификации эмоций, что подтверждает их значимость и надежность в анализе аудиосигналов. Среди хромаграмм, Chroma VQT показала высшую точность, указывая на её потенциальную ценность в данной области. Использование нескольких каналов для добавления различных спектральных признаков в модель не привело к значительным улучшениям. Точность комбинаций оказалась ниже, чем при использовании отдельных мел-спектрограмм или MFCC, что может указывать на необходимость более тщательного подбора и обработки признаков для повышения эффективности.
Исследование подчеркивает критическую важность выбора правильных спектральных признаков для распознавания эмоций, демонстрируя, что эффективность комбинирования признаков может варьироваться в зависимости от конкретных условий и методов обработки данных, несмотря на их потенциальные преимущества.