Метод создания защищённой речеподобной помехи с идентификацией голоса
Метод создания защищённой речеподобной помехи с идентификацией голоса
Аннотация
Рассматриваются особенности использования защищенной речеподобной помехи для защиты конфиденциальных переговоров. Предложен метод генерации речеподобной помехи с возможностью идентификации голоса диктора и применения его фонем для генерации речеподобной помехи, для защиты от возможного перехвата средствами разведки и шумоочистки с применением специализированного программного обеспечения. Описана программная реализация предложенного метода с применением «Информационной системы идентификации дикторов по голосу», модернизированной под задачи генерации речеподобной помехи с применением фонем идентифицированного по голосу диктора для защиты от возможного перехвата средствами разведки и шумоочистки.
1. Введение
Защита акустической информации, циркулирующей в защищаемом помещении входит в один из базисов мероприятий по информационной безопасности предприятия (организации, фирмы). Данные мероприятия реализуются с применением пассивных и активных методов защиты
.Пассивные методы защиты строятся на основе снижения вероятности получения информации или ее расшифровки из акустических источников с использования различного вида звукопоглощающих материалов, используемых во время проведения строительных работ, связанных с возведением или реконструкцией капитального строения.
Активные методы защиты акустической информации – это методы, которые включают использование специального оборудования или программного аппаратных комплексов, для предотвращения утечки акустической информации. Активные методы основаны на создании дополнительных помех, которые скрывают сигнал, несущий речевую информацию, в каналах, где может быть утечка. В качестве маскирующих сигналов широко используется «белый» или «розовый» шум с диапазоном частот от 100 до 10000 Гц
.В последнее время начали применяться и комбинированные сигналы, включающие один из упомянутых и так называемые речеподобные сигналы. Наилучшие результаты можно получить при использовании сигналов, близких по спектральному составу к охраняемым и имеющих структуру речевого сообщения
, , , .В данной статье предложен алгоритм формирования речеподобной помехи (далее – РП), представляющей собой случайную последовательность звуков речи с возможностью идентификации голоса диктора c применением метода обеляющего фильтра . Алгоритм формирования речеподобной помехи реализован с использованием программного средства разработки MatLab в разработанной автором «Программе идентификации дикторов по голосу» (далее – ИС ИДГ) , модернизированной для решения задачи генерации речеподобной помехи диктора. Эффективность предлагаемой речеподобной помехи оценена экспериментально.
2. Теоретический анализ
Для защиты конфиденциальных переговоров часто применяют устройства активной защиты речевой информации, как правило, состоящие из генератора маскирующих сигналов и набора преобразователей электрических сигналов в акустические (например, электродинамических громкоговорителей) или преобразователей электрических сигналов в механические перемещения. В табл. 1 приведены характеристики наиболее распространенных средств защиты речевой информации от утечки по акустическим каналам.
Таблица 1 - Характеристики средств активной защиты речевой информации
Наименование | Диапазон рабочих частот, Гц | Вид маскирующих сигналов | Число каналов | Производитель |
«Прибой» | 100-8000 | «белый» шум | 4 | Беларусь |
«Прибой-Р» | 100-8000 | «белый» шум + речеподобные сигналы | 4 | Беларусь |
ANG-2000 | 250-5000 | «белый» шум | 1 | США |
WNG-023 | 100-12000 | «белый» шум | 1 | Россия |
«Шорох-2М» | 100-12000 | «белый» шум | 1 | Россия |
«Порог-2М» | 250-5000 | «белый» шум | 1 | Россия |
VNG - 006/ VNG - 012GL | 400-5000 | «белый» шум | 5 | Россия |
«Барон» | 90-11200 | «белый» шум + речеподобные сигналы | 4 | Россия |
СТБ231 «Бирюза» | 90-11200 | «белый» шум | 3 | Россия |
ЛГШ-402 | Нет данных | «белый» шум | 2 | Россия |
Проведенные исследования показали, что наиболее эффективным является речеподобная помеха, формируемая из речевых сигналов
.Речеподобный сигнал – это звуковой сигнал, который имитирует речь и предназначается для передачи сообщения или информации между людьми или машинами. Речеподобные сигналы характеризуются сильной корреляцией с человеческой речью, содержат явные фонетические и интонационные признаки и имеют определенный формат данных. Речеподобная помеха – это синтезируемый по случайному закону акустический сигнал, который по своим основным характеристикам соответствует речевому сигналу, но не содержит смысловой информации.
На данный момент времени специалистами предлагается три типа формирования речеподобной помехи:
– в РП 1-го типа производится формирование из N-го количества речи дикторов открытого радиовещания при равномерном сложении этих звуковых дорожек;
– в РП 2-го типа производится формирование из 1-го основного речевого сигнала или используется микширование музыкальных фрагментов и речевых сигналов дикторов радиовещания с определенным шумом;
– в РП 3-го производится формирование из скрываемого речевого сигнала при большом количестве наложений данного же речевого сигнала различного уровня.
В монографии «Расчет и измерение разборчивости речи» (1962) Н. Б. Покровского была описана теория разборчивости речи, а также представлен сравнительный анализ различных способов оценки качества передачи сигнала. Основным показателем эффективности защиты речевого сигнала является словесная разборчивость речи Wc.
Словесная разборчивость Wc показывает насколько понятна для оператора технических систем перехвата информации, очищенный речевой сигнал от систем защиты акустической информации. Для расчёта словесной разборчивости Wc выполняют следующе описанные ниже операции.
Спектр речи разбивают на N-ое количество октавных полос, в частных случаях произвольных, чаще всего используют среднегеометрические частоты в диапазоне от 250 Гц до 4000 Гц.
Для каждой частотной полосы определяется Аi, показывающий энергетическую избыточность дискретной составляющей речевого сигнала. Под избыточностью принято принимать наличие в речи неформатных составляющих (основной тон и т.д., зависящие от индивидуальных показателей диктора), так же рассчитывается весовой коэффициент ki (ki – показывает наличие форманты речи в частотной полосе).
Производится расчёт qi для N-ой октавной полосы, qi есть не что иное, как «уровень речевого сигнала к уровню шума». Используя qi возможно посчитать коэффициент восприятия слухового аппарата человека pi – это предположительное количество формантных речи, которые имеют показатель выше предельного значения восприятия. Далее рассчитывается спектральный индекс разборчивости речи Ri и интегральный индекс артикуляции речи R. После расчёта основных показателей для определения словесной разборчивость речи Wc, полученный индекс артикуляции речи» подставляется в формулу расчёта Wc .
Исследования показывают, что при Wc менее:
- «50% – 70%» – невозможно полностью восстановить информационную составляющую разговора;
- «20% – 40%» – невозможно установить тему разговора;
- «20%» – факт ведения разговор становится под вопросом.
Главная идея предложенного в статье алгоритма формирования РП с возможностью идентификации голоса диктора заключается не только в снижении коэффициента словесной разборчивости Wc, используемого для расчёта выполнения норм по противодействию речевой разведки при проведении конфиденциальных переговоров, но и значительное затруднение проведения цифровой шумоочистки (использование специального программного обеспечения может существенно понизить уровень шума и увеличить разборчивость речи на фоне шумов) перехваченного речевого сигнала, так как для генерации помехового сигнала используется не «белый шум», а РП с фонемами говорящего на совещании диктора.
3. Программа экспериментальных исследований
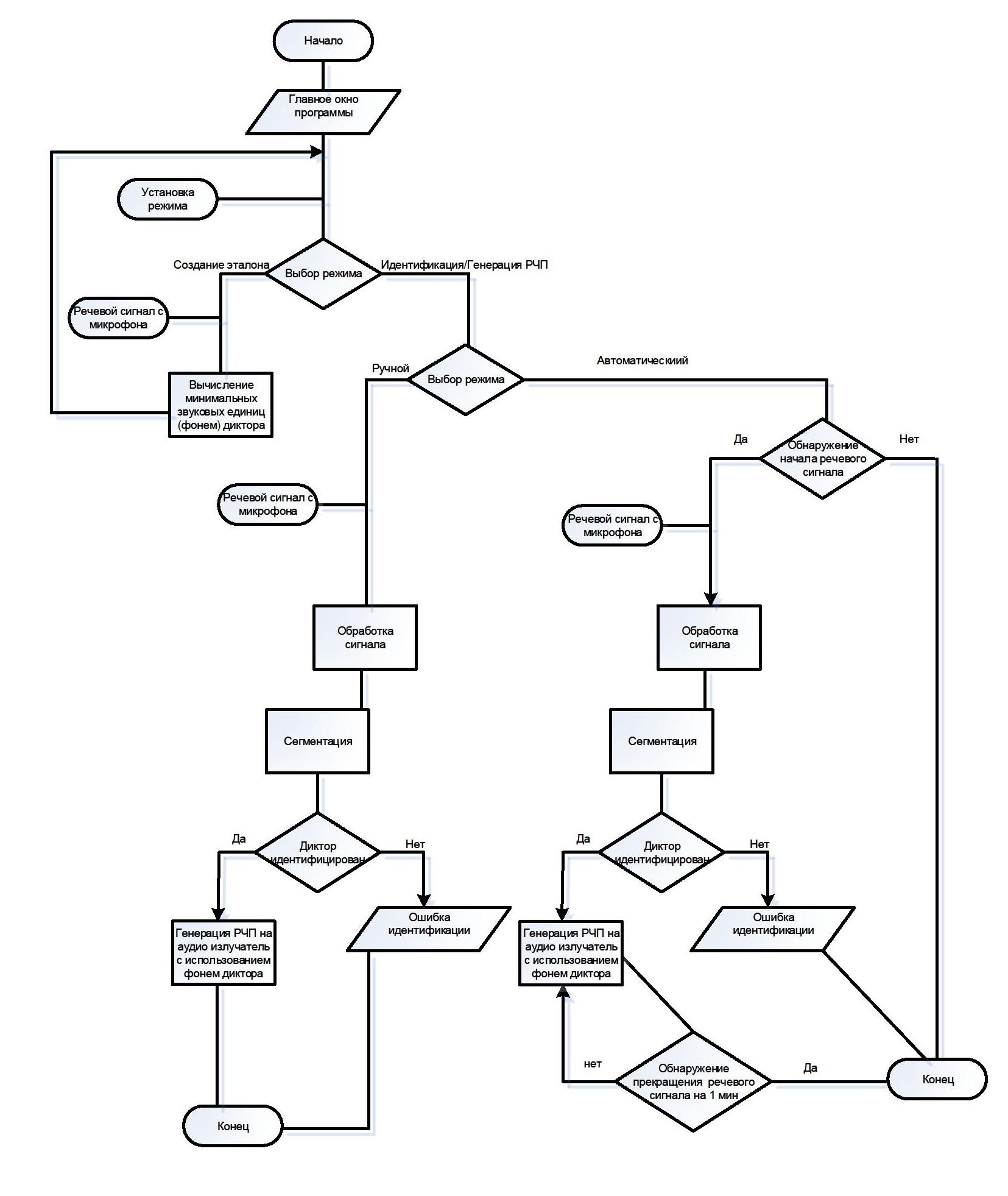
Рисунок 1 - Алгоритм генерации речеподобных помех с идентификацией диктора по голосу
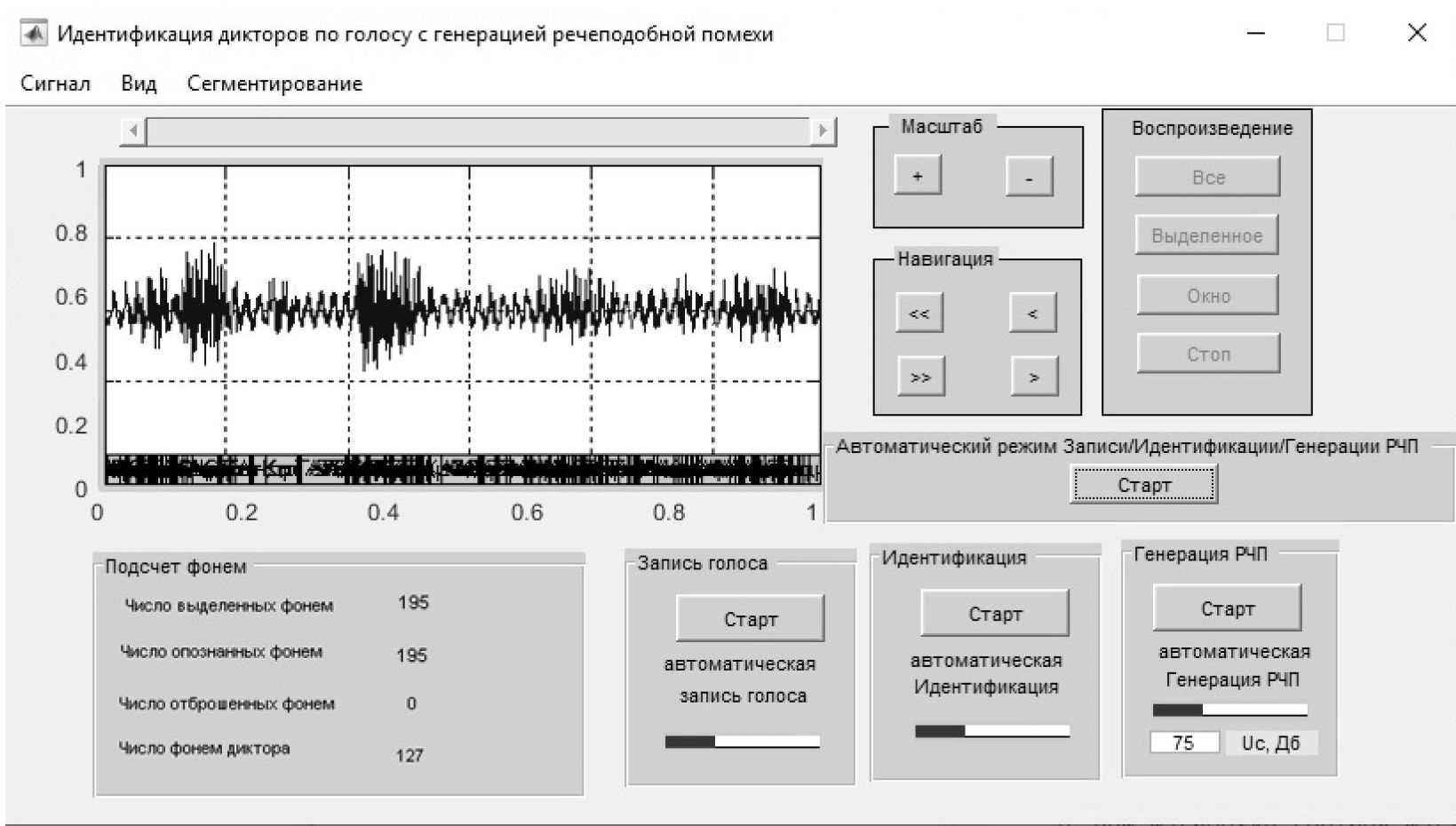
Рисунок 2 - Интерфейс ИС ИДГ с функцией автоматического режима работы с записью голоса, идентификацией и генерацией РП
Таблица 2 - Этапы экспериментальных исследований
Номер эксперимента | Цель эксперимента | Результаты эксперимента |
1 | Создание базы фонем диктора и проведение процедуры идентификации по голосу | Записаны голоса 10 дикторов, произведен анализ и сегментация фонем, произведена успешная идентификация конкретного диктора во время проведения конфиденциальных переговоров из общей базы фонем |
2 | Генерация РП диктора | Выполнена успешная генерация РП, с использованием фонем ранее идентифицированного диктора, на аудио излучатель с заданным уровнем сигнала |
3 | Измерение акустического сигнала и расчет коэффициента словесной разборчивости Wс в различных условиях | Выполнено измерение акустического сигнала и расчёт коэффициента словесной разборчивости Wс: - без применения средств виброакустической защиты (СВАЗ) – норма Wс не выполнилась; - с применением СВАЗ, генерирующей помещу «белый шум» - норма Wс выполнилась; - с применением разработанного алгоритма генерации РП, реализованного в модернизированном программном обеспечении ИС ИДГ - норма Wс выполнилась |
4 | Очистка речевого сигнала от помехи | Выполнена цифровая шумоочистка записанного аудио сигнала, модулированного «белым шумом» и РП диктора – при применении «белого шума» успешно выполнена очистка сигнала и содержание разговора перехвачено; с применением РП диктора – очистка не дала результата, содержание конфиденциального речевого сигнала не перехвачено |
Для проведения экспериментальных исследований применяется персональная электронно-вычислительная машина (ПЭВМ), функционирующая на базе операционной системы Windows 7/10, подключенный к ПЭВМ микрофон и аудио излучатель.
В первом эксперименте, при создании фонетической базы, были записаны голоса 10 дикторов, в ИС ИДГ был произведен анализ и сегментация фонем, каждая фонема была названа в соответствии с первой буквой в имени диктора, например, одна из реализаций фонемы «Ы» пользователя «Васильев Роман» названа «Ы3-Р», и соответственно фонема «А» диктора «Николаева Надежда» – «А1-Н». На рис.3 изображен принцип занесения фонем в голосовую базу ИС ИДГ.
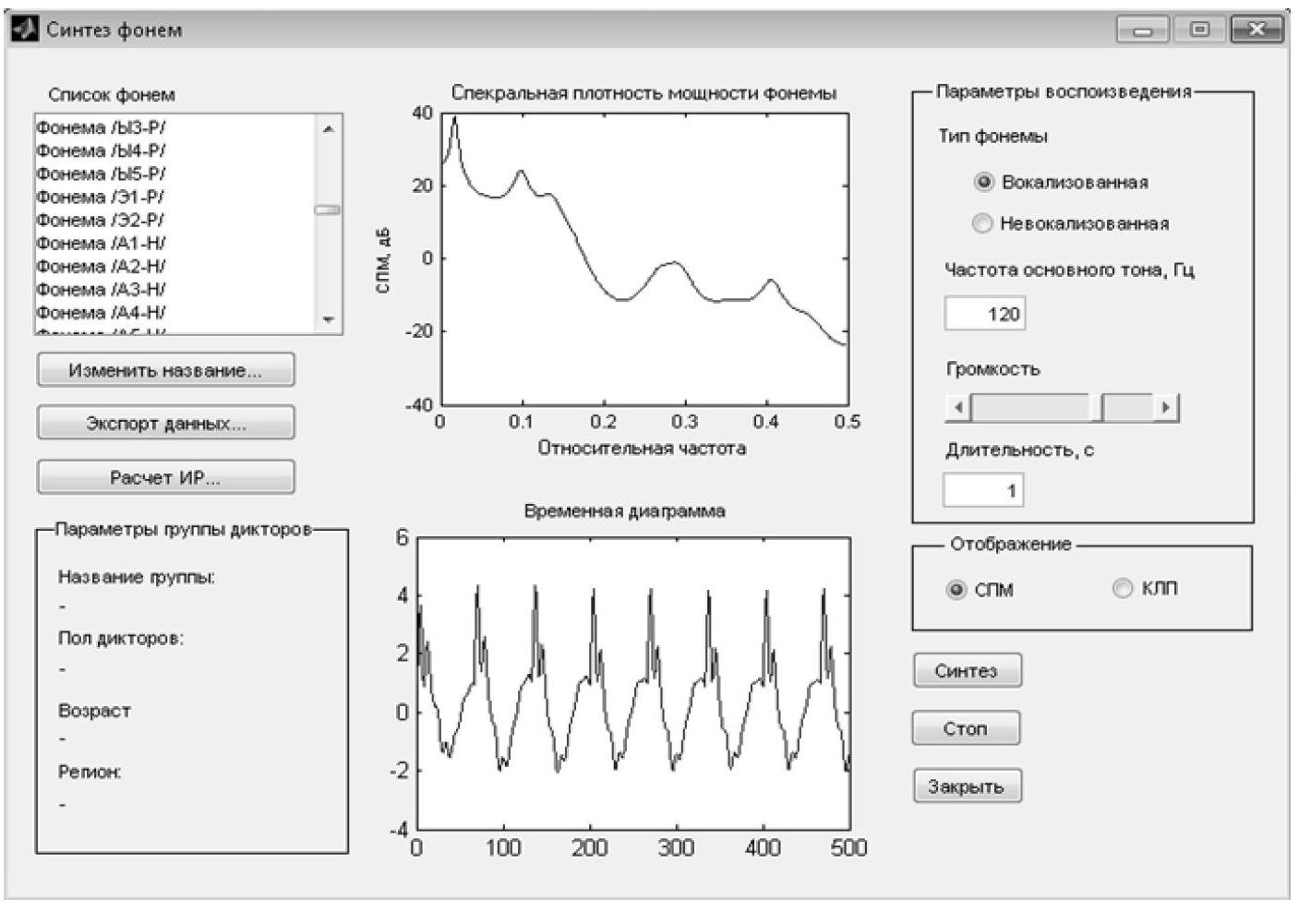
Рисунок 3 - Принцип занесения фонем в голосовую базу ИС ИДГ.
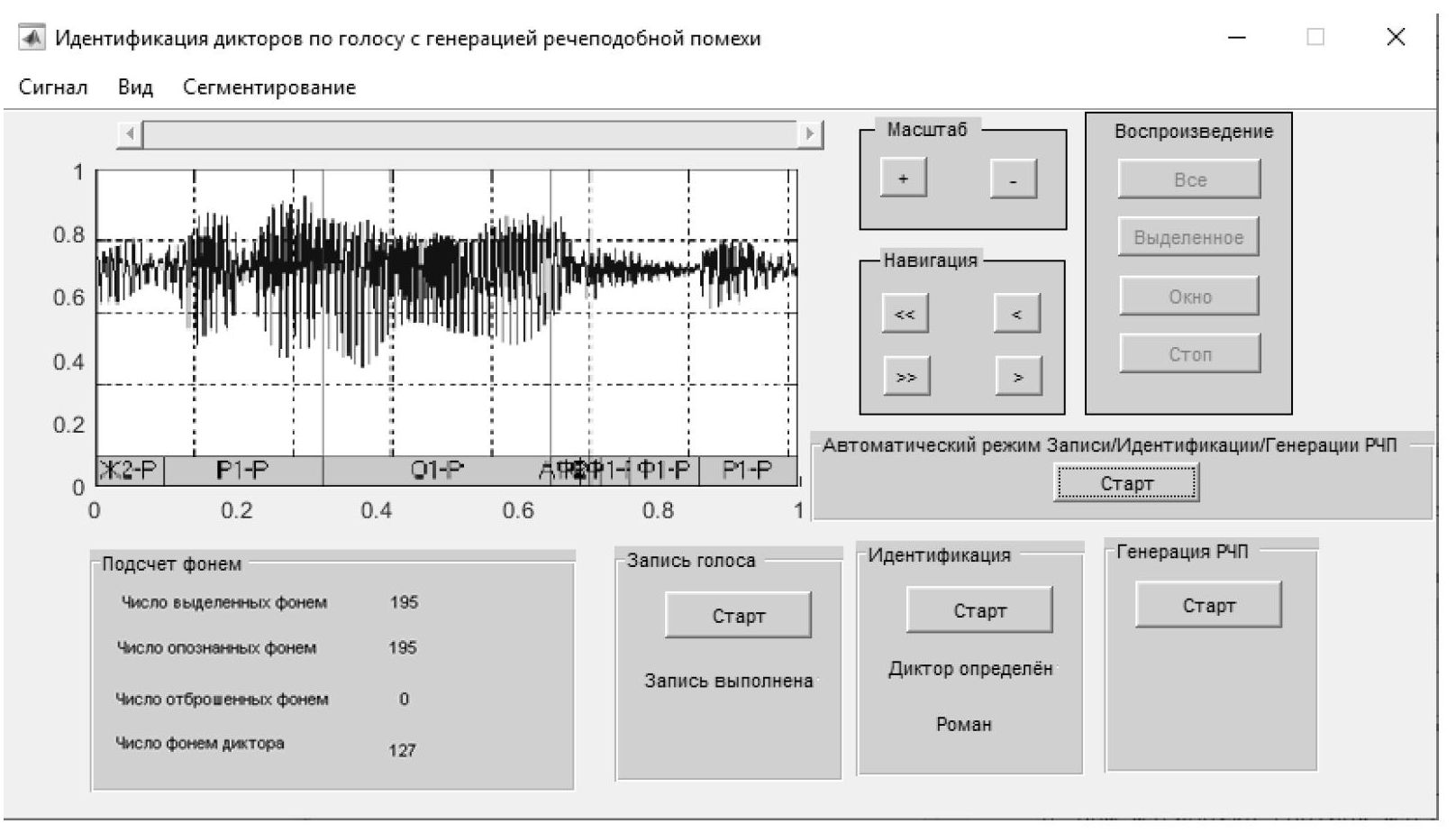
Рисунок 4 - Успешная идентификация диктора «Васильев Роман»
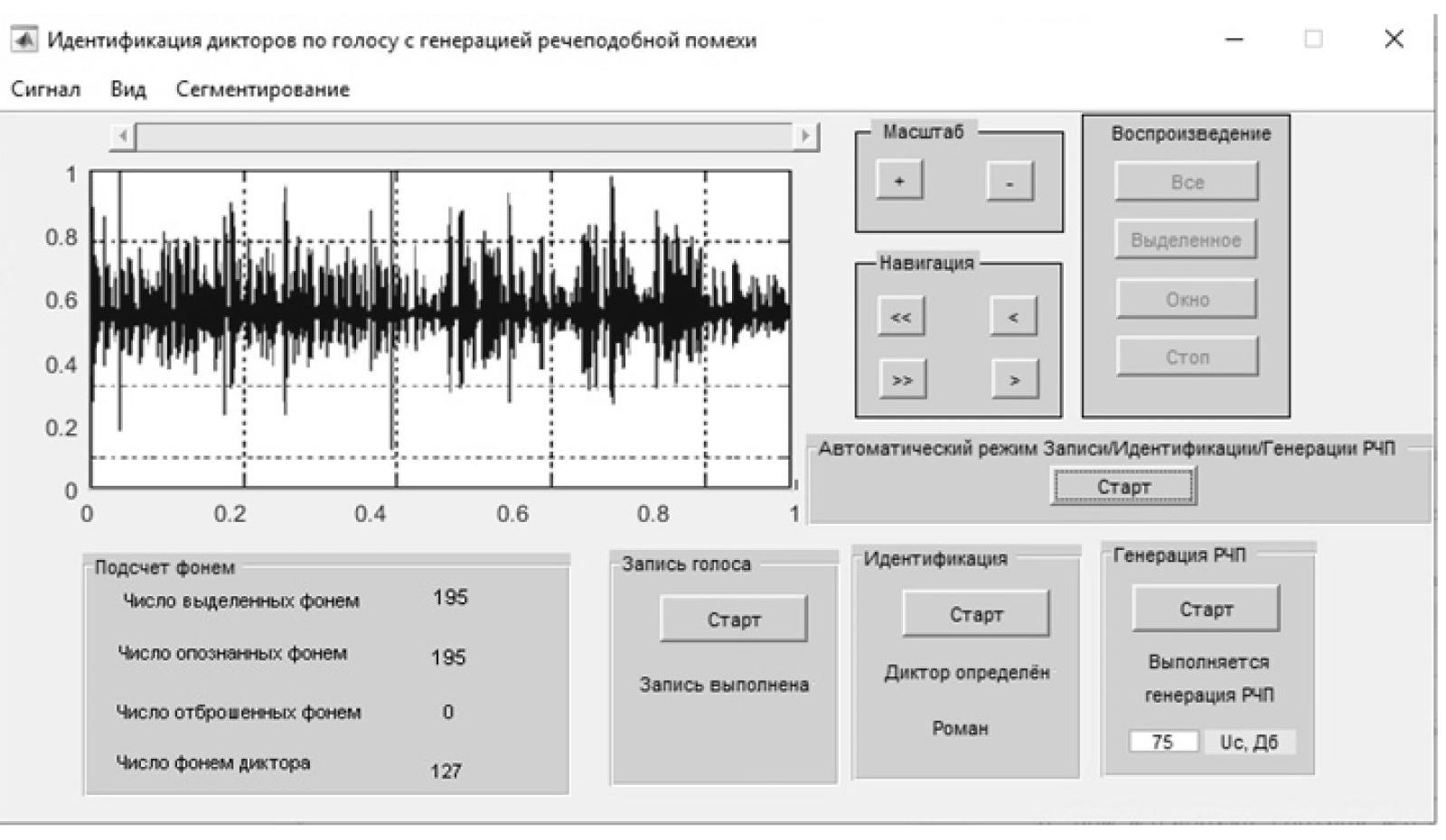
Рисунок 5 - Генерация РП фонем ранее идентифицированного диктора
В третьем эксперименте, с применением системы оценки защищенности помещений по виброакустическому каналу «ШЕПОТ» (Рис. 6), выполнено измерение акустического речевого сигнала, поданного на звуковую колонку с ПЭВМ, и расчёт коэффициента словесной разборчивости Wс
. При измерениях оценивалась вероятность перехвата речевой информации за счёт непреднамеренного прослушивания за дверным проёмом, расчёт Wс производился в трех режимах:- без применения средств активной защиты речевой информации (САЗ);
- с применением акустического излучателя САЗ «Шорох-2М», генерирующего помещу «белый шум»;
- с применением разработанного алгоритма генерации РП, реализованного в модернизированном программном обеспечении ИС ИДГ, установленного на ПЭВМ с подключенным микрофоном и акустическим излучателем.
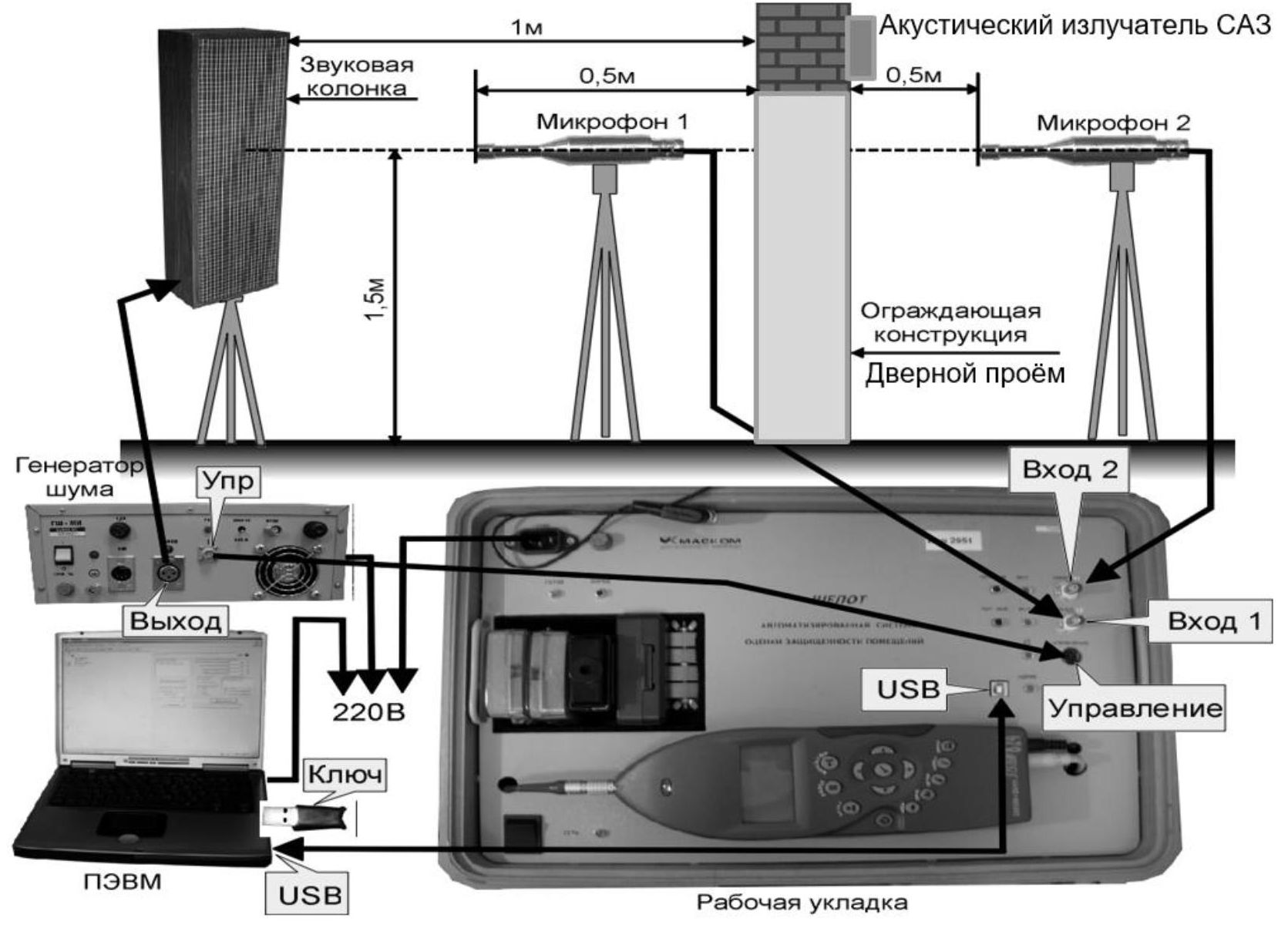
Рисунок 6 - Стенд для оценки защищённости речевой информации от утечки по акустическому каналу
Таблица 3 - Измерение акустического сигнала без применения САЗ
№ октавной полосы | Уровень звукового давления тестового сигнала Lт, дБ | Уровень акустического шума Lш, дБ | Уровень акустического сигнала и акустического шума Lс+ш, дБ | Уровень акустического сигнала Lс, дБ | Отношение «сигнал/шум» Еi, дБ | Соответствие нормированным отношениям «сигнал/шум» |
1 | 88,30 | 40,70 | 75,90 | 75,90 | 12,90 | Не вып. |
2 | 89,40 | 40,30 | 75,10 | 75,10 | 11,40 | Не вып. |
3 | 88,60 | 42,90 | 76,00 | 76,00 | 5,50 | Не вып. |
4 | 87,40 | 35,70 | 70,80 | 70,80 | 3,70 | Не вып. |
5 | 86,50 | 39,40 | 74,90 | 74,90 | 2,00 | Не вып. |
Отношение сигнал/шум не выполняется во всех октавных полосах. Произведен расчет словесной разборчивости речи Wс, норма не выполнилась (Табл. 4).
Таблица 4 - Расчет словесной разборчивости речи Wс без применения САЗ
№ октавной полосы | Значение октавного индекса артикуляции ri | Значение интегрального индекса артикуляции R | Значение показателя противодействия Wс | Выполнение нормы противодействия |
1 | 0,0102 | 0,3711 | 0,961 | Не вып. |
2 | 0,0501 | |||
3 | 0,0777 | |||
4 | 0,1280 | |||
5 | 0,1051 |
Проведено измерение акустического сигнала в контрольной точке «дверной проём» с применением САЗ (Табл. 5)
Таблица 5 - Измерение акустического сигнала с применением САЗ
№ октавной полосы | Уровень звукового давления тестового сигнала Lт, дБ | Уровень акустического шума и САЗ Lш, дБ | Уровень акустического сигнала и акустического шума Lс+ш, дБ | Уровень акустического сигнала Lс, дБ | Отношение «сигнал/шум» Еi, дБ | Соответствие нормированным отношениям «сигнал/шум» |
1 | 89,40 | 55,90 | 76,20 | 76,20 | -3,10 | Вып. |
2 | 90,50 | 55,00 | 75,40 | 75,40 | -4,10 | Не вып. |
3 | 89,70 | 54,90 | 76,30 | 76,30 | -7,30 | Не вып. |
4 | 88,50 | 55,80 | 71,10 | 71,10 | -17,20 | Вып. |
5 | 87,60 | 57,40 | 75,20 | 75,20 | -16,80 | Вып |
Отношение сигнал/шум не выполняется в двух октавных полосах. Произведен расчет словесной разборчивости речи Wс, норма выполнилась (Табл. 6).
Таблица 6 - Расчет словесной разборчивости речи Wс с применением САЗ
№ октавной полосы | Значение октавного индекса артикуляции ri | Значение интегрального индекса артикуляции R | Значение показателя противодействия Wс | Выполнение нормы противодействия |
1 | 0,0012 | 0,0459 | 0,283 | Вып. |
2 | 0,0084 | |||
3 | 0,0184 | |||
4 | 0,0084 | |||
5 | 0,0095 |
Проведено измерение акустического сигнала в контрольной точке «дверной проём» с применением разработанного алгоритма генерации РП (Табл. 7)
Таблица 7 - Измерение акустического сигнала с применением РП
№ октавной полосы | Уровень звукового давления тестового сигнала Lт, дБ | Уровень акустического шума и РП Lш, дБ | Уровень акустического сигнала и акустического шума Lс+ш, дБ | Уровень акустического сигнала Lс, дБ | Отношение «сигнал/шум» Еi, дБ | Соответствие нормированным отношениям «сигнал/шум» |
1 | 88,30 | 63,10 | 75,90 | 75,90 | -9,50 | Вып. |
2 | 89,40 | 62,20 | 75,10 | 75,10 | -10,50 | Вып. |
3 | 88,60 | 62,10 | 76,00 | 76,00 | -13,70 | Вып. |
4 | 87,40 | 63,00 | 70,80 | 69,80 | -24,60 | Вып. |
5 | 86,50 | 64,60 | 74,90 | 74,90 | -23,20 | Вып. |
Отношение сигнал/шум выполняется во всех октавных полосах. Произведен расчет словесной разборчивости речи Wс, норма выполнилась (Табл. 8).
Таблица 8 - Расчет словесной разборчивости речи Wс с применением РП
№ октавной полосы | Значение октавного индекса артикуляции ri | Значение интегрального индекса артикуляции R | Значение показателя противодействия Wс | Выполнение нормы противодействия |
1 | 0,0003 | 0,0131 | 0,070 | Вып. |
2 | 0,0026 | |||
3 | 0,0062 | |||
4 | 0,0016 | |||
5 | 0,0024 |
По результатам третьего эксперимента можно сделать вывод, что эффективность разработанного алгоритма генерации РП не только не уступает методам генерации помехи «белый шум», но и выдаёт более высокие показатели при расчёте показателя противодействия словесной разборчивости речи Wс.
В четвертом эксперименте, с применением программного обеспечения «Audacity», выполнена цифровая шумоочистка записанного аудио сигнала, модулированного «белым шумом» (Рис. 7), где верхняя строка – модулированный «белым шумом» речевой сигнал, а нижняя строка – очищенный речевой сигнал, и шумоочистка аудио сигнала, модулированного РП диктора (Рис. 8), где верхняя строка модулированный РП речевой сигнал, нижняя строка – очищенный речевой сигнал.
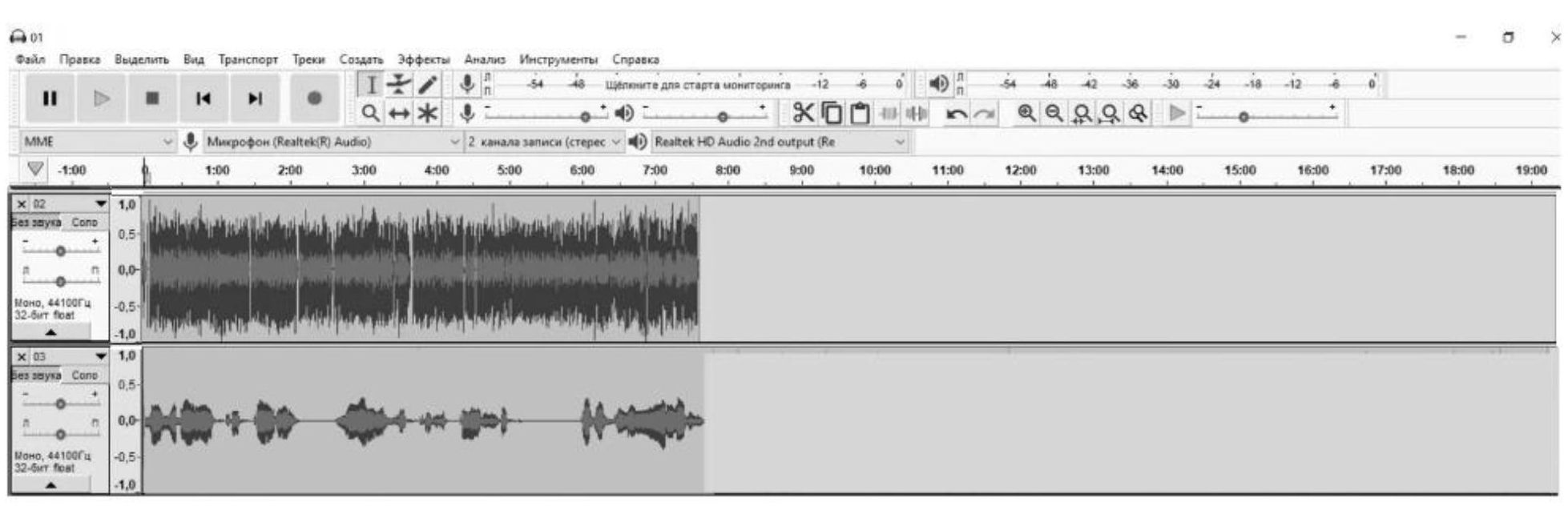
Рисунок 7 - Цифровая шумоочистка аудио сигнала, модулированного «белым шумом»
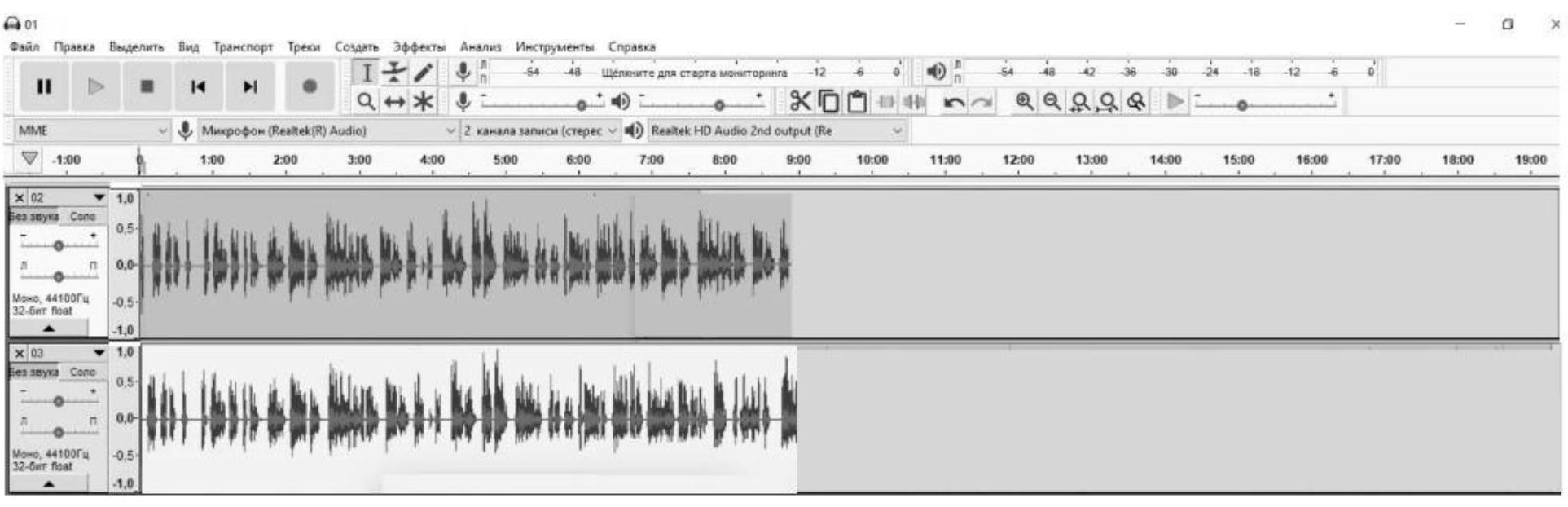
Рисунок 8 - Цифровая шумоочистка аудио сигнала, модулированного РП диктора
4. Заключение
В настоящей статье предложен метод формирования речеподобной помехи, представляющей собой случайную последовательность звуков речи идентифицированного ранее диктора. Эффективность предлагаемой речеподобной помехи оценена экспериментально, показаны преимущества разработанного алгоритма генерации РП с идентификацией голоса диктора, по сравнению с другими методами формирования помех акустического сигнала .